An Adversarial Perspective on Machine Unlearning for AI Safety
作者: Jakub Łucki, Boyi Wei, Yangsibo Huang, Peter Henderson, Florian Tramèr, Javier Rando
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-09-26 (更新: 2025-05-31)
备注: Published in Transactions on Machine Learning Research (TMLR); Best technical paper at Neurips 2024 SoLaR workshop
💡 一句话要点
从对抗视角评估AI模型卸载学习的安全性,揭示现有方法的脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI安全 卸载学习 对抗攻击 大型语言模型 越狱攻击
📋 核心要点
- 现有大型语言模型安全防护措施易被绕过,卸载学习旨在彻底移除模型中的有害能力,但效果存疑。
- 论文从对抗视角出发,通过精心设计的攻击方法,挑战了现有卸载学习方法的安全性。
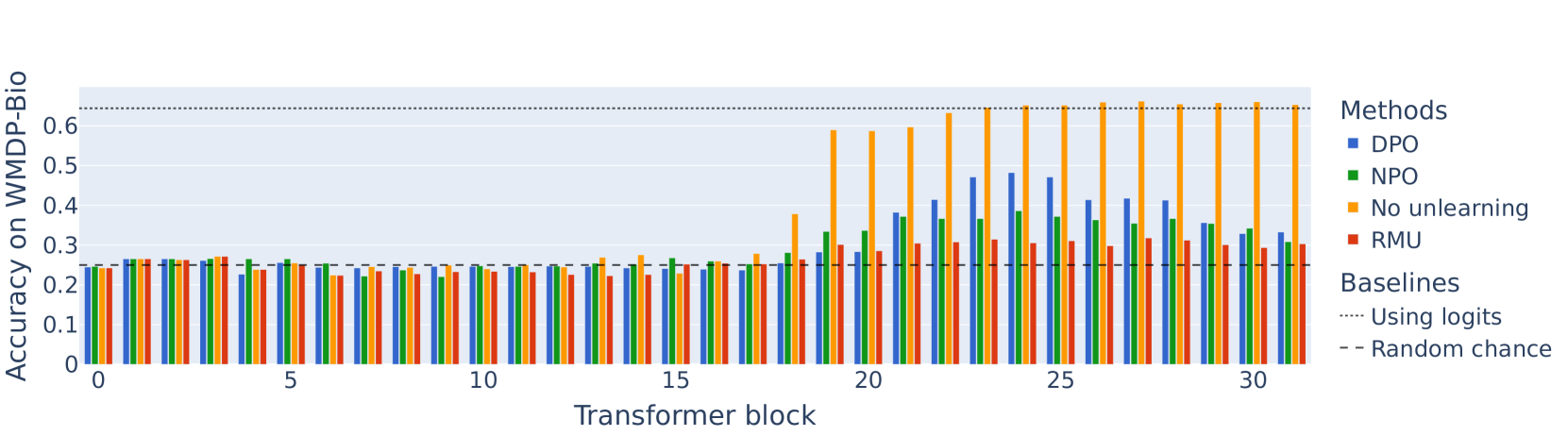
- 实验表明,简单的微调或激活空间操作即可恢复模型已卸载的危险能力,质疑了卸载学习的有效性。
📝 摘要(中文)
大型语言模型通常经过微调以拒绝回答有关危险知识的问题,但这些保护措施经常可以被绕过。卸载学习方法旨在从模型中完全移除危险能力,使其无法被攻击者利用。本文从对抗的角度挑战了卸载学习与传统安全后训练之间的根本差异。研究表明,先前被认为对卸载学习无效的越狱方法,在仔细应用时可以成功。此外,本文开发了多种自适应方法,可以恢复大部分据称已卸载的能力。例如,研究表明,在10个不相关的示例上进行微调或移除激活空间中的特定方向,可以恢复使用最先进的卸载学习方法RMU编辑的模型的大部分危险能力。这些发现挑战了当前卸载学习方法的鲁棒性,并质疑其相对于安全训练的优势。
🔬 方法详解
问题定义:论文关注的是AI模型卸载学习的安全性问题。现有的卸载学习方法,如RMU,旨在从模型中移除有害知识和能力,防止模型被用于恶意目的。然而,这些方法的有效性和鲁棒性尚不明确,容易受到对抗攻击的威胁。现有方法的痛点在于,它们可能无法完全移除有害能力,或者移除有害能力的同时,也损害了模型的其他有用能力。
核心思路:论文的核心思路是从对抗的角度评估卸载学习的安全性。通过设计和应用各种对抗攻击方法,包括已有的越狱方法和自适应攻击方法,来测试卸载学习后的模型是否仍然具有有害能力。如果攻击能够成功恢复模型已卸载的能力,则说明卸载学习方法存在安全漏洞。
技术框架:论文的技术框架主要包括以下几个部分:1) 选择一种或多种卸载学习方法(如RMU)对模型进行编辑,移除有害能力;2) 应用现有的越狱攻击方法,测试模型是否仍然能够生成有害内容;3) 开发自适应攻击方法,例如在少量无关数据上进行微调,或者移除激活空间中的特定方向,以恢复模型已卸载的能力;4) 评估攻击的成功率,并分析卸载学习方法的安全漏洞。
关键创新:论文最重要的技术创新点在于,它从对抗的角度重新审视了卸载学习的安全性,并证明了现有的卸载学习方法容易受到对抗攻击。与以往的研究不同,论文不仅使用了已有的越狱方法,还开发了自适应攻击方法,能够更有效地恢复模型已卸载的能力。
关键设计:论文的关键设计包括:1) 精心选择和调整现有的越狱攻击方法,使其能够绕过卸载学习的防御;2) 设计自适应攻击方法,例如通过在少量无关数据上进行微调,来恢复模型已卸载的能力;3) 通过移除激活空间中的特定方向,来恢复模型已卸载的能力。这些设计旨在尽可能地恢复模型已卸载的有害能力,从而评估卸载学习方法的安全性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使使用最先进的卸载学习方法RMU,通过在10个不相关的示例上进行微调,或者移除激活空间中的特定方向,也可以恢复模型的大部分危险能力。这表明现有的卸载学习方法在对抗攻击面前非常脆弱,其安全性远低于预期。
🎯 应用场景
该研究成果可应用于评估和改进AI模型的安全性,特别是在涉及敏感信息或潜在危害的领域,如医疗、金融和自动驾驶。通过对抗性测试,可以发现卸载学习方法的漏洞,并开发更鲁棒的卸载学习算法,从而降低AI模型被恶意利用的风险,提升AI系统的整体安全性。
📄 摘要(原文)
Large language models are finetuned to refuse questions about hazardous knowledge, but these protections can often be bypassed. Unlearning methods aim at completely removing hazardous capabilities from models and make them inaccessible to adversaries. This work challenges the fundamental differences between unlearning and traditional safety post-training from an adversarial perspective. We demonstrate that existing jailbreak methods, previously reported as ineffective against unlearning, can be successful when applied carefully. Furthermore, we develop a variety of adaptive methods that recover most supposedly unlearned capabilities. For instance, we show that finetuning on 10 unrelated examples or removing specific directions in the activation space can recover most hazardous capabilities for models edited with RMU, a state-of-the-art unlearning method. Our findings challenge the robustness of current unlearning approaches and question their advantages over safety training.