Accumulator-Aware Post-Training Quantization for Large Language Models
作者: Ian Colbert, Giuseppe Franco, Fabian Grob, Jinjie Zhang, Rayan Saab
分类: cs.LG, cs.AI, cs.DM
发布日期: 2024-09-25 (更新: 2025-07-31)
💡 一句话要点
AXE:首个面向大语言模型的累加器感知型后训练量化框架,保障溢出避免。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大语言模型 累加器感知 溢出避免 低精度计算
📋 核心要点
- 现有量化方法忽略了低精度累加带来的溢出风险,限制了推理性能的提升。
- AXE框架通过理论分析,为PTQ算法提供溢出避免保证,支持多阶段累加。
- 实验表明,AXE在量化Llama3 8B时,能显著提升性能,并保持较高的模型精度。
📝 摘要(中文)
当权重和激活量化到越来越窄的表示时,乘法累加(MAC)单元中加法的成本开始超过乘法的成本。最近的研究表明,通过低精度累加来降低加法成本可以提高推理平台上的吞吐量、功耗和面积,但会增加溢出的风险。到目前为止,累加器感知量化研究只考虑了量化感知训练(QAT)范式,其中模型经过微调或从头开始训练,并在循环中进行量化。随着模型和数据集规模的持续增长,QAT技术的成本变得越来越高,这推动了最近后训练量化(PTQ)研究的激增。为了弥合这一差距,我们引入了AXE,这是第一个累加器感知量化框架,专门为PTQ算法提供溢出避免保证。我们提出了AXE的理论动机,并通过在GPFQ和OPTQ两种现有算法之上实现它来展示其灵活性。我们将AXE设计为支持多阶段累加,从而首次打开了完整数据路径优化的可能性。我们使用最新的语言生成模型评估AXE;当为16位多阶段累加数据路径量化Llama3 8B时,AXE保持了高达98%的FP16困惑度,超过了朴素位宽操作高达15%。
🔬 方法详解
问题定义:论文旨在解决大语言模型后训练量化(PTQ)过程中,由于低精度累加导致的溢出问题。现有的PTQ方法通常只关注权重和激活的量化,而忽略了累加器本身的精度,这可能导致计算结果超出累加器的表示范围,从而影响模型的准确性和稳定性。
核心思路:论文的核心思路是设计一个累加器感知的量化框架AXE,该框架能够显式地考虑累加器的精度限制,并在量化过程中避免溢出。AXE通过理论分析,推导出溢出发生的条件,并据此调整量化参数,以保证计算结果始终在累加器的表示范围内。这种设计使得AXE能够在不牺牲模型精度的情况下,充分利用低精度累加带来的性能优势。
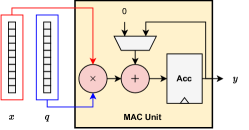
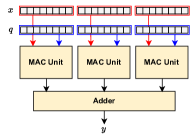
技术框架:AXE框架主要包含以下几个阶段:1) 溢出分析:对模型中的每个算子进行溢出分析,确定其累加器的精度需求。2) 量化参数调整:根据溢出分析的结果,调整权重和激活的量化参数,以满足累加器的精度需求。3) 多阶段累加支持:AXE支持多阶段累加,允许将计算过程分解为多个阶段,每个阶段使用不同的累加器精度,从而实现更细粒度的优化。4) 集成现有PTQ算法:AXE可以很容易地集成到现有的PTQ算法中,例如GPFQ和OPTQ,从而增强这些算法的溢出避免能力。
关键创新:AXE最重要的技术创新点在于它是第一个专门为PTQ算法提供溢出避免保证的累加器感知量化框架。与现有的PTQ方法相比,AXE能够显式地考虑累加器的精度限制,并在量化过程中避免溢出,从而提高模型的准确性和稳定性。此外,AXE还支持多阶段累加,允许更细粒度的优化,进一步提升性能。
关键设计:AXE的关键设计包括:1) 溢出分析方法:论文提出了一种基于理论分析的溢出分析方法,能够准确地确定每个算子的累加器精度需求。2) 量化参数调整策略:论文设计了一种量化参数调整策略,能够根据溢出分析的结果,调整权重和激活的量化参数,以满足累加器的精度需求。3) 多阶段累加实现:论文详细描述了如何实现多阶段累加,并给出了具体的代码示例。
🖼️ 关键图片
📊 实验亮点
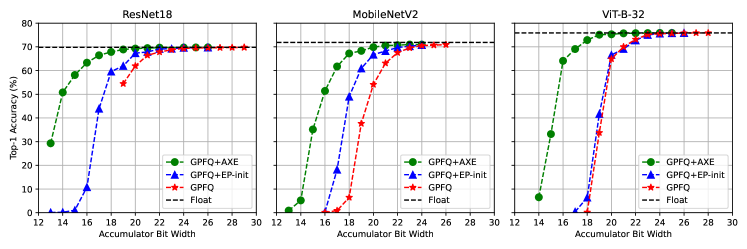
实验结果表明,在使用AXE量化Llama3 8B模型时,对于16位多阶段累加数据路径,AXE能够保持高达98%的FP16困惑度,相比于朴素的位宽操作,性能提升高达15%。这表明AXE在保证模型精度的同时,能够有效地利用低精度累加带来的性能优势。
🎯 应用场景
该研究成果可广泛应用于大语言模型的部署和推理加速,尤其是在资源受限的边缘设备上。通过降低计算精度和优化数据路径,AXE能够显著提升模型的推理速度和能效,从而降低部署成本,并为更广泛的应用场景提供可能性。未来,该技术有望推动大语言模型在移动设备、物联网设备等领域的普及。
📄 摘要(原文)
When quantizing weights and activations to increasingly narrower representations, the cost of additions begins to dominate that of multiplications in multiply-accumulate (MAC) units. Recent studies show that reducing addition costs via low-precision accumulation improves throughput, power, and area across inference platforms, albeit with an increased risk of overflow. Accumulator-aware quantization research has so far only considered the quantization-aware training (QAT) paradigm, in which models are fine-tuned or trained from scratch with quantization in the loop. As models and datasets continue to grow in size, QAT techniques become increasingly more expensive, which has motivated the recent surge in post-training quantization (PTQ) research. To bridge this gap, we introduce AXE, the first accumulator-aware quantization framework explicitly designed to endow overflow avoidance guarantees to PTQ algorithms. We present theoretical motivation for AXE and demonstrate its flexibility by implementing it on top of two existing algorithms: GPFQ and OPTQ. We design AXE to support multi-stage accumulation, opening the door to full datapath optimization for the first time. We evaluate AXE using recent language generation models; when quantizing Llama3 8B for a 16-bit multi-stage accumulation datapath, AXE maintains up to 98% of the FP16 perplexity, surpassing naive bit width manipulation by up to 15%.