Revisiting Space Mission Planning: A Reinforcement Learning-Guided Approach for Multi-Debris Rendezvous
作者: Agni Bandyopadhyay, Guenther Waxenegger-Wilfing
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-09-25
备注: Accepted for publication at the 2024 International Conference on Space Robotics (iSpaRo)
💡 一句话要点
提出基于强化学习的多碎片空间任务规划方法,优化交会序列
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 空间任务规划 强化学习 近端策略优化 空间碎片清除 序列决策
📋 核心要点
- 现有空间任务规划方法在处理多碎片交会问题时,难以找到最优的访问序列,导致任务总时间较长。
- 论文提出使用带掩码的近端策略优化(PPO)算法,训练神经网络策略,学习最优的碎片访问序列。
- 实验结果表明,该方法在规划效率上显著优于遗传算法和贪婪算法,平均减少任务时间10.96%和13.66%。
📝 摘要(中文)
本研究提出了一种深度强化学习中带掩码的近端策略优化(PPO)算法的新应用,用于确定空间碎片访问的最有效序列,并利用Izzo改进的Lambert求解器进行单独交会。目标是优化所有给定碎片被访问的顺序,以使整个任务的交会总时间最短。开发了一个神经网络(NN)策略,并在具有不同碎片场的模拟空间任务上进行训练。训练后,神经网络使用Izzo改进的Lambert算法计算近似最优路径。通过与任务规划中的标准启发式算法进行比较来评估性能。强化学习方法通过优化碎片交会的顺序,显著提高了规划效率,与遗传算法和贪婪算法相比,总任务时间平均分别减少了约10.96%和13.66%。该模型平均能够识别各种模拟场景中最省时的碎片访问序列,并且计算速度最快。这种方法标志着在增强空间碎片清除的任务规划策略方面向前迈进了一步。
🔬 方法详解
问题定义:论文旨在解决空间碎片清除任务中,如何确定最优的空间碎片访问序列,以最小化总任务时间的问题。现有方法,如遗传算法和贪婪算法,在面对复杂的多碎片场景时,难以找到全局最优解,导致任务效率低下。
核心思路:论文的核心思路是利用强化学习,将空间任务规划问题建模为一个序列决策问题。通过训练一个神经网络策略,使其能够根据当前状态(碎片位置、飞船状态等)选择下一个要访问的碎片,从而学习到最优的访问序列。这种方法能够有效地探索搜索空间,找到比传统启发式算法更优的解决方案。
技术框架:整体框架包括以下几个主要模块:1) 环境建模:模拟空间碎片分布和飞船运动;2) 状态表示:将当前任务状态编码为神经网络的输入;3) 动作空间:定义飞船可以执行的动作,即选择下一个要访问的碎片;4) 奖励函数:设计奖励函数,鼓励飞船尽快完成任务;5) 强化学习算法:使用带掩码的PPO算法训练神经网络策略。
关键创新:该论文的关键创新在于将强化学习应用于空间任务规划,并使用带掩码的PPO算法来处理动作空间中无效动作的问题。掩码机制可以避免神经网络选择已经访问过的碎片,从而提高训练效率和性能。此外,论文还结合了Izzo改进的Lambert求解器,用于计算飞船在不同碎片之间的转移轨道。
关键设计:论文使用了神经网络作为策略函数,输入是当前任务状态的编码,输出是每个碎片的访问概率。损失函数是PPO算法的标准损失函数,包括策略梯度项、裁剪项和价值函数项。掩码机制通过将已访问碎片的访问概率设置为零来实现。具体参数设置未知。
🖼️ 关键图片

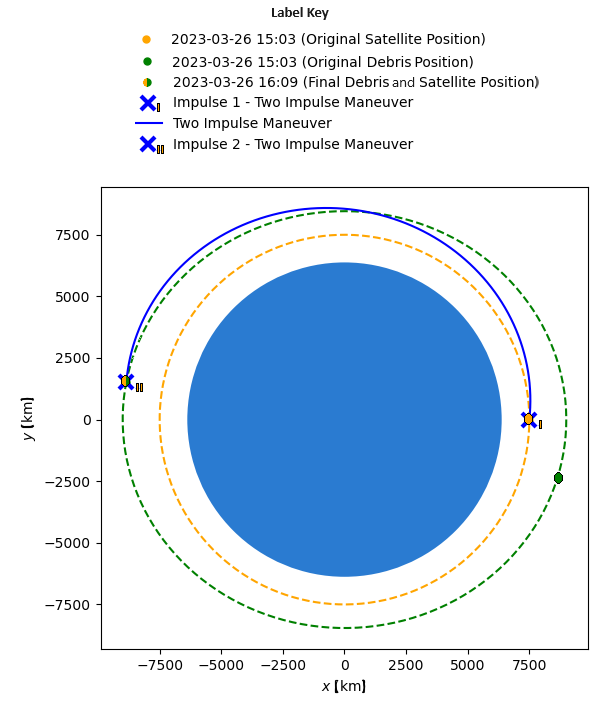

📊 实验亮点
实验结果表明,该方法在规划效率上显著优于遗传算法和贪婪算法。与遗传算法相比,总任务时间平均减少了约10.96%;与贪婪算法相比,总任务时间平均减少了约13.66%。此外,该方法在各种模拟场景中都能快速找到最优的碎片访问序列,具有较高的计算效率。
🎯 应用场景
该研究成果可应用于空间碎片清除、卫星维护、空间资源探测等领域。通过优化任务规划,可以显著降低任务成本,提高任务效率,并减少空间碎片对在轨航天器的威胁。未来,该方法有望推广到更复杂的空间任务规划问题,例如多航天器协同任务规划。
📄 摘要(原文)
This research introduces a novel application of a masked Proximal Policy Optimization (PPO) algorithm from the field of deep reinforcement learning (RL), for determining the most efficient sequence of space debris visitation, utilizing the Lambert solver as per Izzo's adaptation for individual rendezvous. The aim is to optimize the sequence in which all the given debris should be visited to get the least total time for rendezvous for the entire mission. A neural network (NN) policy is developed, trained on simulated space missions with varying debris fields. After training, the neural network calculates approximately optimal paths using Izzo's adaptation of Lambert maneuvers. Performance is evaluated against standard heuristics in mission planning. The reinforcement learning approach demonstrates a significant improvement in planning efficiency by optimizing the sequence for debris rendezvous, reducing the total mission time by an average of approximately {10.96\%} and {13.66\%} compared to the Genetic and Greedy algorithms, respectively. The model on average identifies the most time-efficient sequence for debris visitation across various simulated scenarios with the fastest computational speed. This approach signifies a step forward in enhancing mission planning strategies for space debris clearance.