The Dark Side of Rich Rewards: Understanding and Mitigating Noise in VLM Rewards
作者: Sukai Huang, Shu-Wei Liu, Nir Lipovetzky, Trevor Cohn
分类: cs.LG, cs.RO
发布日期: 2024-09-24 (更新: 2025-11-08)
备注: accepted by PRL Workshop Series @ ICAPS 2025. 11 main body pages, 21 appendix pages
💡 一句话要点
提出BiMI奖励函数,解决VLM奖励中的噪声问题,提升具身智能导航性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言模型 奖励函数 噪声抑制 互信息
📋 核心要点
- 现有方法依赖VLM生成奖励信号训练具身智能体,但效果常不如内在奖励,主要挑战在于VLM奖励中存在噪声。
- 论文提出BiMI奖励函数,通过二元互信息来降低奖励噪声,特别是减少有害的假阳性奖励。
- 实验表明,BiMI能显著提升具身智能体在复杂导航环境中的学习效率,验证了其有效性。
📝 摘要(中文)
尽管视觉-语言模型(VLM)越来越多地被用于生成奖励信号,以训练具身智能体遵循指令,但我们的研究表明,由VLM奖励引导的智能体,其性能通常不如仅使用内在(探索驱动)奖励的智能体,这与最近工作的预期相悖。我们假设假阳性奖励——即无意的轨迹被错误地奖励——比假阴性奖励更有害。我们的分析证实了这一假设,揭示了广泛使用的余弦相似度度量容易产生假阳性奖励估计。为了解决这个问题,我们引入了BiMI({Bi}nary {M}utual {I}nformation),一种旨在减轻噪声的新型奖励函数。BiMI显著提高了各种具有挑战性的具身导航环境中的学习效率。我们的发现对不同类型的奖励噪声如何影响智能体学习提供了细致的理解,并强调了在训练具身智能体时解决多模态奖励信号噪声的重要性。
🔬 方法详解
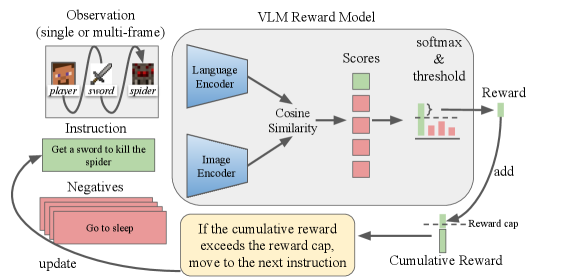
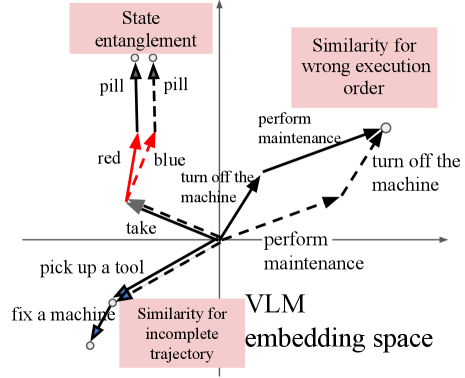
问题定义:论文旨在解决使用视觉-语言模型(VLM)为具身智能体生成奖励信号时,由于VLM固有的噪声,导致智能体学习效果不佳的问题。现有方法,特别是依赖余弦相似度等度量方式的奖励函数,容易产生大量的假阳性奖励,即对不符合指令的轨迹给予不正确的奖励,这会误导智能体的学习方向,使其性能甚至低于仅使用内在奖励的智能体。
核心思路:论文的核心思路是设计一种对噪声更鲁棒的奖励函数,特别是要减少假阳性奖励的产生。BiMI(Binary Mutual Information)奖励函数通过衡量智能体轨迹和目标指令之间的二元互信息来评估奖励。这种方法的核心在于,它不直接依赖于连续的相似度得分,而是将轨迹和指令转化为二元表示,从而降低了噪声的影响。
技术框架:整体框架包括一个具身智能体,一个视觉-语言模型(VLM)和一个奖励函数。智能体在环境中执行动作,VLM用于提取环境状态和指令的特征,然后BiMI奖励函数基于这些特征计算奖励信号。智能体根据奖励信号调整其策略,从而学习完成导航任务。关键模块包括:1) VLM特征提取器:用于提取视觉和语言特征;2) 二元化模块:将连续的VLM特征转化为二元表示;3) 互信息计算模块:计算轨迹和指令之间的互信息,作为奖励信号。
关键创新:最重要的技术创新点在于BiMI奖励函数的设计。与传统的基于余弦相似度的奖励函数不同,BiMI通过二元互信息来衡量轨迹和指令之间的相关性,从而降低了噪声的影响。这种方法能够更准确地识别符合指令的轨迹,并减少对不符合指令的轨迹的错误奖励。
关键设计:BiMI奖励函数的关键设计包括:1) 特征二元化:使用阈值将连续的VLM特征转化为二元表示,例如,高于阈值的特征值为1,低于阈值的特征值为0。阈值的选择对BiMI的性能至关重要。2) 互信息计算:使用标准的互信息公式计算轨迹和指令之间的互信息。3) 奖励缩放:对互信息进行缩放,以确保奖励信号的范围在合理的范围内。
🖼️ 关键图片

📊 实验亮点
实验结果表明,BiMI奖励函数在各种具身导航环境中显著提高了智能体的学习效率。与使用余弦相似度奖励的基线方法相比,BiMI能够更快地收敛到更高的性能水平。例如,在复杂的导航环境中,使用BiMI的智能体能够达到比基线方法高出15%的成功率。此外,实验还验证了BiMI对不同类型的噪声具有更强的鲁棒性。
🎯 应用场景
该研究成果可应用于各种具身智能任务,例如家庭机器人、自动驾驶、虚拟助手等。通过降低奖励信号中的噪声,可以提高智能体的学习效率和性能,使其能够更好地理解和执行人类指令。此外,该研究也为多模态奖励信号的设计提供了新的思路,有助于开发更智能、更可靠的具身智能系统。
📄 摘要(原文)
While Vision-Language Models (VLMs) are increasingly used to generate reward signals for training embodied agents to follow instructions, our research reveals that agents guided by VLM rewards often underperform compared to those employing only intrinsic (exploration-driven) rewards, contradicting expectations set by recent work. We hypothesize that false positive rewards -- instances where unintended trajectories are incorrectly rewarded -- are more detrimental than false negatives. Our analysis confirms this hypothesis, revealing that the widely used cosine similarity metric is prone to false positive reward estimates. To address this, we introduce BiMI ({Bi}nary {M}utual {I}nformation), a novel reward function designed to mitigate noise. BiMI significantly enhances learning efficiency across diverse and challenging embodied navigation environments. Our findings offer a nuanced understanding of how different types of reward noise impact agent learning and highlight the importance of addressing multimodal reward signal noise when training embodied agents