COSBO: Conservative Offline Simulation-Based Policy Optimization
作者: Eshagh Kargar, Ville Kyrki
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-09-22
💡 一句话要点
提出COSBO,结合离线数据与保守策略优化解决强化学习中的模拟-真实差距。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 模拟-真实差距 保守策略优化 策略优化 机器人控制
📋 核心要点
- 离线强化学习受限于训练数据质量,难以泛化到未见过的状态和动作。
- COSBO结合不完美的模拟环境和真实环境数据,利用保守策略优化弥补模拟-真实差距。
- 实验表明,COSBO在复杂动态环境中优于CQL、MOPO和COMBO等先进方法,表现出更强的鲁棒性。
📝 摘要(中文)
离线强化学习允许在来自真实环境部署的数据上训练强化学习模型。然而,它仅限于选择训练数据中存在的最佳行为组合。相比之下,尝试复制真实环境的模拟环境可以代替真实数据,但这种方法受到模拟-真实差距的限制,导致偏差。为了兼顾两者的优点,我们提出了一种方法,该方法结合了不完善的模拟环境和来自目标环境的数据,以训练离线强化学习策略。我们的实验表明,所提出的方法优于最先进的方法CQL、MOPO和COMBO,尤其是在具有多样化和挑战性动态的场景中,并在各种实验条件下表现出稳健的行为。结果表明,当无法与真实世界直接交互时,使用模拟器生成的数据可以有效地增强离线策略学习,即使存在模拟-真实差距。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集训练策略,避免与真实环境的交互。然而,当模拟环境存在偏差(即模拟-真实差距)时,直接在模拟环境中训练的策略难以在真实环境中取得良好效果。现有方法要么完全依赖离线数据,受限于数据质量,要么忽略模拟环境的潜在价值。
核心思路:COSBO的核心思路是结合离线数据集和模拟环境数据,同时采用保守策略优化方法。通过利用模拟环境生成更多样化的数据,并结合真实环境数据进行训练,可以提高策略的泛化能力。保守策略优化则用于约束策略的行为,避免过度依赖模拟环境数据带来的偏差。
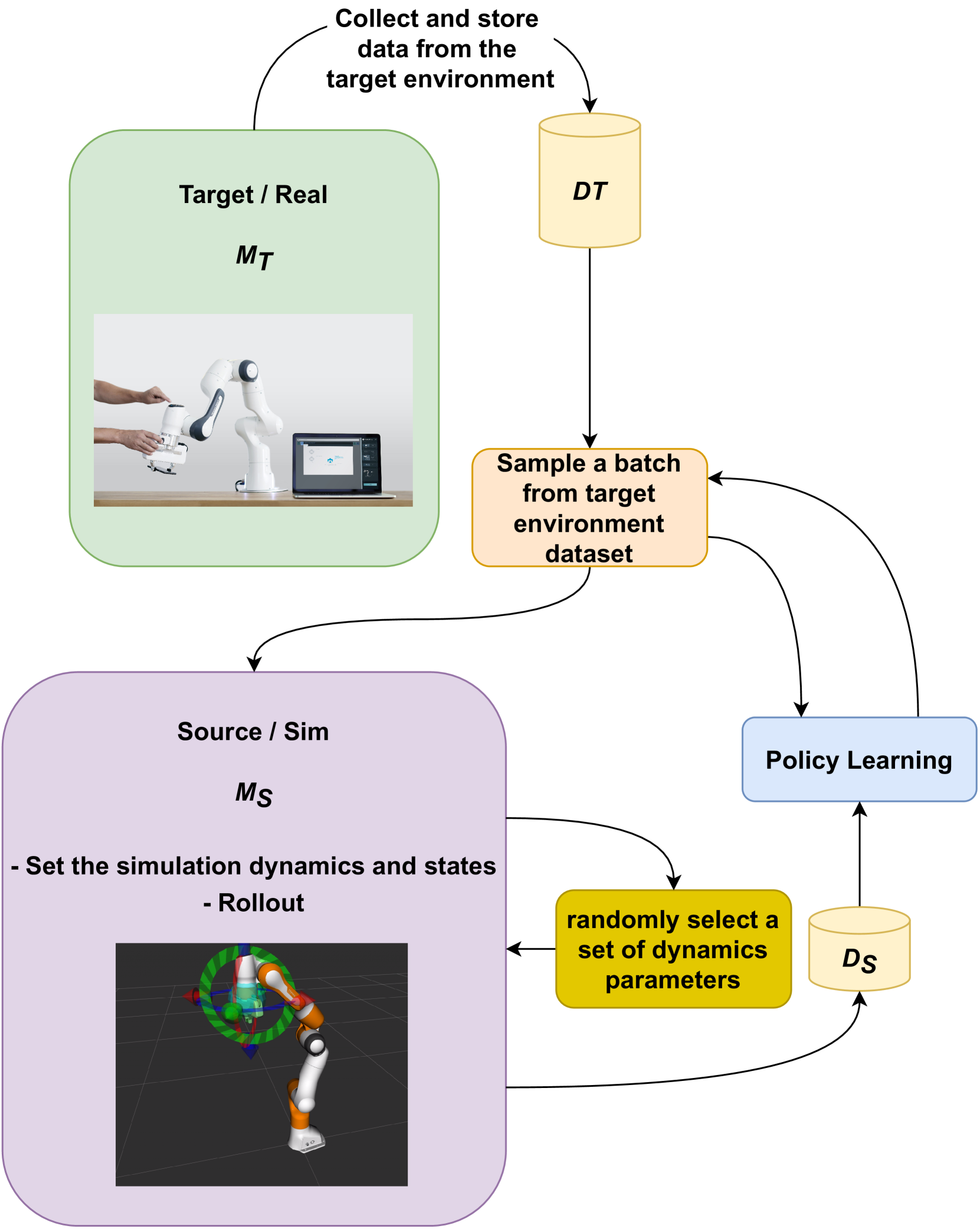
技术框架:COSBO的整体框架包含以下几个主要步骤:1) 利用模拟环境生成一定量的数据;2) 将模拟环境数据与离线数据集混合;3) 使用混合数据集训练策略,训练过程中采用保守策略优化方法,例如通过添加约束项,限制策略输出的动作与离线数据集中的动作之间的差异;4) 在真实环境中评估训练好的策略。
关键创新:COSBO的关键创新在于:1) 结合了模拟环境数据和离线数据集,充分利用了两种数据源的优势;2) 采用了保守策略优化方法,有效缓解了模拟-真实差距带来的问题,避免策略过度依赖模拟环境数据;3) 提出了一种新的损失函数,用于平衡策略的探索性和保守性。
关键设计:COSBO的关键设计包括:1) 使用KL散度作为保守策略优化的约束项,限制策略输出的动作分布与离线数据集中的动作分布之间的差异;2) 设计了一个可调节的参数,用于控制保守策略优化的强度;3) 使用了Actor-Critic框架,其中Actor网络负责生成策略,Critic网络负责评估策略的价值。
🖼️ 关键图片


📊 实验亮点
实验结果表明,COSBO在多个benchmark任务上优于CQL、MOPO和COMBO等先进的离线强化学习算法。尤其是在具有挑战性的动态环境中,COSBO的性能提升更为显著。例如,在某个机器人控制任务中,COSBO的平均回报比CQL提高了20%以上,表明COSBO能够更有效地利用模拟环境数据,并缓解模拟-真实差距带来的问题。
🎯 应用场景
COSBO可应用于机器人控制、自动驾驶、游戏AI等领域,尤其适用于难以进行在线交互或成本高昂的场景。例如,在机器人控制中,可以利用模拟环境生成大量训练数据,并结合少量真实环境数据进行训练,从而降低训练成本并提高策略的泛化能力。在自动驾驶领域,可以利用模拟器进行危险场景的训练,并结合真实驾驶数据进行微调,提高自动驾驶系统的安全性。
📄 摘要(原文)
Offline reinforcement learning allows training reinforcement learning models on data from live deployments. However, it is limited to choosing the best combination of behaviors present in the training data. In contrast, simulation environments attempting to replicate the live environment can be used instead of the live data, yet this approach is limited by the simulation-to-reality gap, resulting in a bias. In an attempt to get the best of both worlds, we propose a method that combines an imperfect simulation environment with data from the target environment, to train an offline reinforcement learning policy. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches CQL, MOPO, and COMBO, especially in scenarios with diverse and challenging dynamics, and demonstrates robust behavior across a variety of experimental conditions. The results highlight that using simulator-generated data can effectively enhance offline policy learning despite the sim-to-real gap, when direct interaction with the real-world is not possible.