Efficient Training of Deep Neural Operator Networks via Randomized Sampling
作者: Sharmila Karumuri, Lori Graham-Brady, Somdatta Goswami
分类: cs.LG, physics.data-an, stat.ML
发布日期: 2024-09-20 (更新: 2025-06-01)
💡 一句话要点
提出基于随机采样的DeepONet训练方法,提升泛化能力并加速复杂动力学预测。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 神经算子 DeepONet 随机采样 深度学习 函数空间 复杂动力学 泛化能力 高效训练
📋 核心要点
- 传统DeepONet训练采用均匀网格采样,导致batch size过大,泛化能力差,内存需求高。
- 提出在DeepONet的trunk网络输入端进行随机采样,降低计算负担,提升模型泛化性。
- 实验表明,该方法在保证或降低测试误差的同时,显著减少了训练时间,提升了模型鲁棒性。
📝 摘要(中文)
本文提出了一种随机采样技术,用于提升深度算子网络(DeepONet)的训练效率和泛化能力。DeepONet是一种流行的神经算子架构,已成功应用于各种科学和工程应用中的复杂动力学实时预测。该方法主要针对DeepONet的trunk网络,该网络输出与物理系统定义域的时空位置相对应的基函数。传统的DeepONet训练在构建损失函数时,对每个迭代都考虑时空点的均匀网格,导致较大的batch size,泛化能力差,且由于随机梯度下降(SGD)优化器的限制,内存需求增加。所提出的trunk网络输入随机采样缓解了这些挑战,提高了泛化能力,降低了训练期间的内存需求,从而显著提高了计算效率。通过三个基准示例验证了该假设,结果表明,相对于传统的训练方法,在实现相当或更低的总体测试误差的同时,训练时间显著减少。结果表明,在训练期间将随机化引入trunk网络输入可以增强DeepONet的效率和鲁棒性,为提高该框架在复杂物理系统建模中的性能提供了一条有希望的途径。
🔬 方法详解
问题定义:DeepONet在训练过程中,为了学习无限维函数空间之间的映射关系,需要对输入函数进行离散化。传统方法采用均匀网格采样,这导致了两个主要问题:一是batch size过大,增加了计算负担和内存需求;二是均匀采样可能无法充分捕捉到函数的重要特征,从而影响模型的泛化能力。
核心思路:本文的核心思路是在DeepONet的trunk网络输入端引入随机采样。通过随机选择时空点,可以有效地减小batch size,降低计算复杂度。同时,随机采样可以增加训练数据的多样性,提高模型对未见数据的泛化能力。
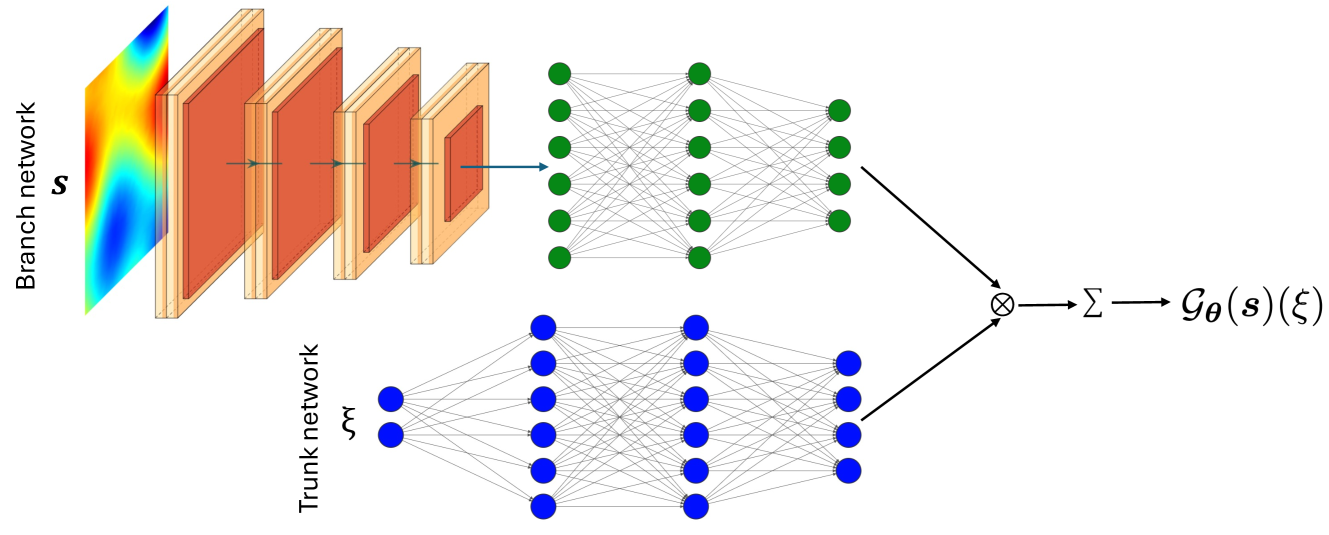
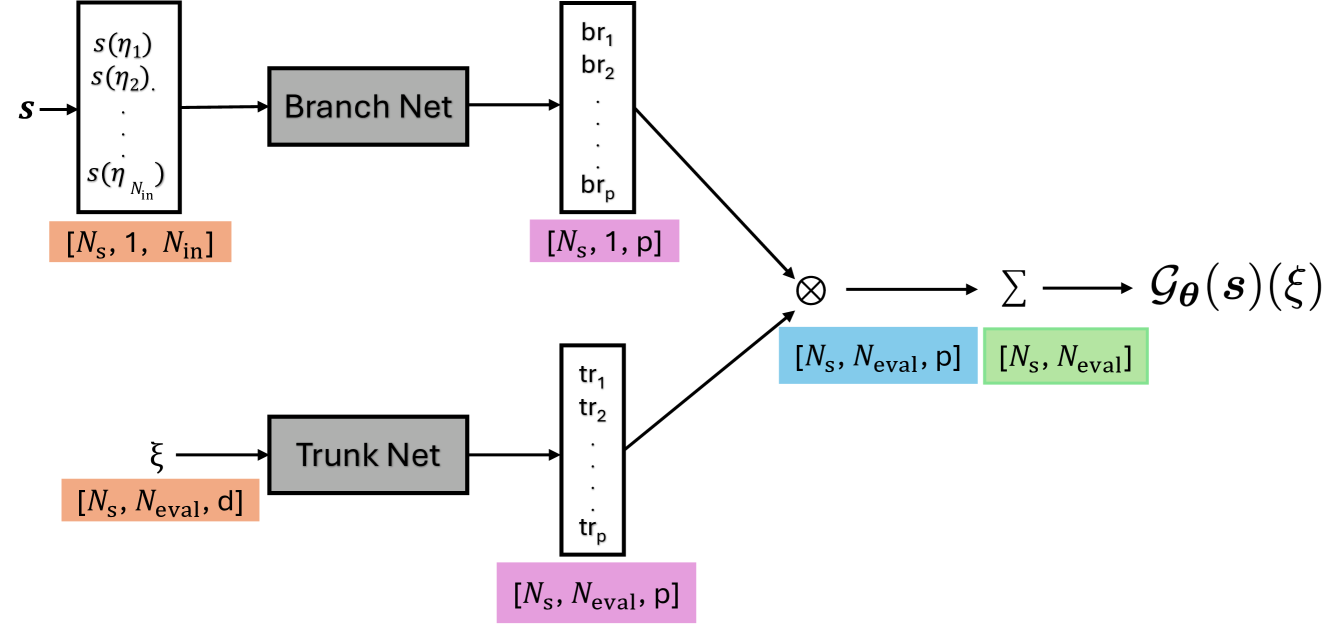
技术框架:该方法主要针对DeepONet的trunk网络进行改进。DeepONet由trunk网络和branch网络组成,trunk网络负责处理输出空间的坐标信息,branch网络负责处理输入函数的信息。在训练过程中,对trunk网络的输入(即时空坐标)进行随机采样,然后将采样后的数据输入到trunk网络中,得到基函数。最后,将trunk网络和branch网络的输出进行组合,得到最终的预测结果。
关键创新:该方法最重要的创新点在于将随机采样引入到DeepONet的trunk网络输入端。与传统的均匀采样方法相比,随机采样可以有效地减小batch size,降低计算复杂度,并提高模型的泛化能力。此外,该方法不需要对DeepONet的整体架构进行修改,易于实现和应用。
关键设计:在具体实现中,需要确定随机采样的策略,例如采样点的数量和分布。论文中可能采用了均匀分布或重要性采样等策略。此外,损失函数的设计也至关重要。论文中可能采用了均方误差(MSE)等常用的损失函数,并根据具体问题进行了调整。
🖼️ 关键图片

📊 实验亮点
论文通过三个基准示例验证了所提出方法的有效性。实验结果表明,与传统的均匀采样方法相比,该方法可以在显著减少训练时间的同时,达到相当甚至更低的测试误差。具体的性能提升数据需要在论文中查找,例如训练时间减少的百分比,测试误差降低的幅度等。这些结果表明,随机采样可以有效地提升DeepONet的训练效率和泛化能力。
🎯 应用场景
该研究成果可广泛应用于科学和工程领域中复杂动力系统的建模与预测,例如流体动力学、热传导、结构力学等。通过提升DeepONet的训练效率和泛化能力,可以实现对这些系统更准确、更快速的预测,从而为相关领域的决策提供支持,例如优化设计、故障诊断和实时控制。
📄 摘要(原文)
Neural operators (NOs) employ deep neural networks to learn mappings between infinite-dimensional function spaces. Deep operator network (DeepONet), a popular NO architecture, has demonstrated success in the real-time prediction of complex dynamics across various scientific and engineering applications. In this work, we introduce a random sampling technique to be adopted during the training of DeepONet, aimed at improving the generalization ability of the model, while significantly reducing the computational time. The proposed approach targets the trunk network of the DeepONet model that outputs the basis functions corresponding to the spatiotemporal locations of the bounded domain on which the physical system is defined. While constructing the loss function, DeepONet training traditionally considers a uniform grid of spatiotemporal points at which all the output functions are evaluated for each iteration. This approach leads to a larger batch size, resulting in poor generalization and increased memory demands, due to the limitations of the stochastic gradient descent (SGD) optimizer. The proposed random sampling over the inputs of the trunk net mitigates these challenges, improving generalization and reducing memory requirements during training, resulting in significant computational gains. We validate our hypothesis through three benchmark examples, demonstrating substantial reductions in training time while achieving comparable or lower overall test errors relative to the traditional training approach. Our results indicate that incorporating randomization in the trunk network inputs during training enhances the efficiency and robustness of DeepONet, offering a promising avenue for improving the framework's performance in modeling complex physical systems.