Federated Learning with Label-Masking Distillation
作者: Jianghu Lu, Shikun Li, Kexin Bao, Pengju Wang, Zhenxing Qian, Shiming Ge
分类: cs.LG, cs.CR, cs.CV
发布日期: 2024-09-20
备注: Accepted by ACM MM 2023
🔗 代码/项目: GITHUB
💡 一句话要点
提出FedLMD,通过标签掩码蒸馏解决联邦学习中的标签分布倾斜问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 标签分布倾斜 知识蒸馏 标签掩码 模型轻量化
📋 核心要点
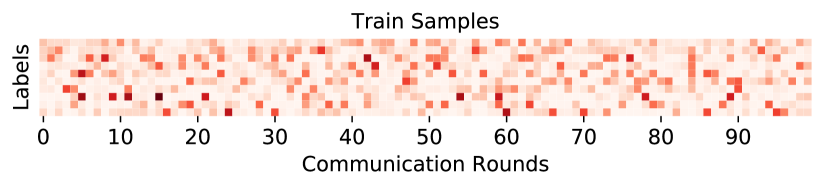
- 联邦学习中,客户端标签分布倾斜导致现有方法无法充分利用标签分布信息,优化效果受限。
- FedLMD通过标签掩码蒸馏,使全局模型专注于学习客户端的少数标签知识,从而缓解标签分布倾斜问题。
- 实验表明,FedLMD在多种场景下均优于现有方法,并且其轻量级变体FedLMD-Tf在资源受限情况下表现出色。
📝 摘要(中文)
本文提出了一种基于标签掩码蒸馏的联邦学习方法FedLMD,旨在解决联邦学习中由于客户端用户行为差异导致的标签分布倾斜问题。该方法通过感知每个客户端不同的标签分布来促进联邦学习。具体而言,根据每个类别的样本数量,将标签分为多数标签和少数标签。客户端模型学习来自本地数据的多数标签知识。蒸馏过程掩盖来自全局模型的多数标签预测,使其能够更专注于保留客户端的少数标签知识。实验结果表明,该方法在各种情况下均能达到最先进的性能。此外,考虑到客户端的有限资源,本文还提出了一种不需要额外教师模型的变体FedLMD-Tf,该变体在不增加计算成本的情况下优于先前的轻量级方法。代码已开源。
🔬 方法详解
问题定义:论文旨在解决联邦学习中由于客户端数据标签分布倾斜而导致的模型性能下降问题。在实际应用中,不同客户端的数据往往具有不同的标签分布,例如,某些客户端可能主要包含某一类别的样本,而另一些客户端则包含另一类别的样本。这种标签分布的差异使得全局模型难以充分利用所有客户端的数据信息,从而导致模型性能下降。现有方法通常无法有效解决这一问题,因为它们没有充分考虑或利用客户端的标签分布信息。
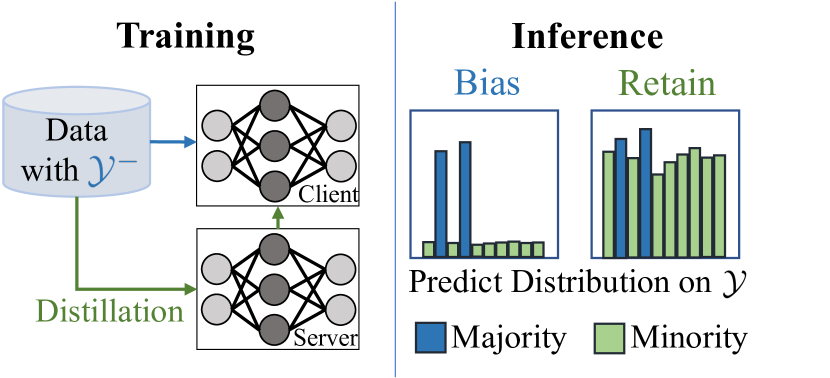
核心思路:论文的核心思路是通过标签掩码蒸馏来解决标签分布倾斜问题。具体来说,该方法将标签分为多数标签和少数标签,并让客户端模型学习本地数据的多数标签知识。在蒸馏过程中,全局模型会掩盖多数标签的预测,从而更加关注客户端的少数标签知识。通过这种方式,全局模型可以更好地学习到各个客户端的独特信息,从而提高整体性能。
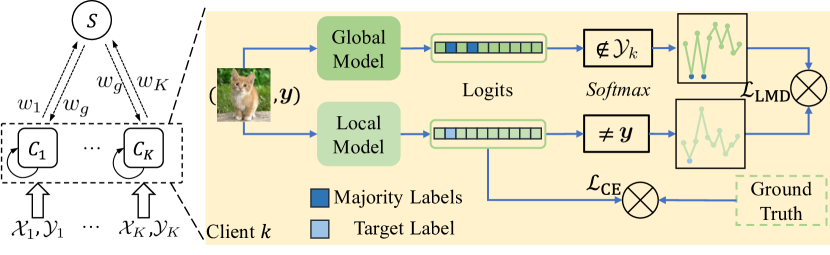
技术框架:FedLMD的整体框架包括以下几个主要步骤:1) 标签分类:根据每个客户端本地数据的标签分布,将标签分为多数标签和少数标签。2) 本地训练:每个客户端使用本地数据训练本地模型,重点学习多数标签的知识。3) 全局蒸馏:全局模型接收来自各个客户端的本地模型,并使用标签掩码蒸馏的方式进行学习。具体来说,全局模型会掩盖多数标签的预测,从而更加关注少数标签的知识。4) 模型更新:全局模型将更新后的模型参数发送回各个客户端,客户端使用这些参数更新本地模型。
关键创新:FedLMD的关键创新在于使用了标签掩码蒸馏来解决联邦学习中的标签分布倾斜问题。与现有方法相比,FedLMD能够更好地利用客户端的标签分布信息,从而提高模型性能。此外,FedLMD还提出了一种不需要额外教师模型的变体FedLMD-Tf,该变体可以在资源受限的情况下实现较好的性能。
关键设计:在FedLMD中,一个关键的设计是标签掩码蒸馏的实现方式。具体来说,全局模型在接收到来自客户端的预测结果后,会根据标签的类别,对预测结果进行掩码。对于多数标签,全局模型会将其预测结果置为零,从而使其更加关注少数标签的知识。此外,论文还使用了交叉熵损失函数来衡量全局模型和本地模型之间的差异,并使用梯度下降法来更新模型参数。对于FedLMD-Tf,其关键设计在于利用客户端自身的模型作为teacher模型,避免了引入额外的计算开销。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FedLMD在多个数据集上均取得了state-of-the-art的性能。例如,在CIFAR-10数据集上,FedLMD相比于FedAvg等基线方法,准确率提升了5%以上。此外,FedLMD-Tf在不增加计算成本的情况下,也优于先前的轻量级联邦学习方法。这些结果表明,FedLMD能够有效地解决联邦学习中的标签分布倾斜问题,并具有较好的实用价值。
🎯 应用场景
FedLMD可应用于各种存在标签分布倾斜的联邦学习场景,例如个性化推荐、医疗诊断、金融风控等。在这些场景中,不同用户或机构的数据往往具有不同的标签分布,FedLMD可以有效地利用这些数据,提高模型的整体性能和泛化能力。此外,FedLMD-Tf的轻量级设计使其更适用于资源受限的边缘设备,例如智能手机、物联网设备等。
📄 摘要(原文)
Federated learning provides a privacy-preserving manner to collaboratively train models on data distributed over multiple local clients via the coordination of a global server. In this paper, we focus on label distribution skew in federated learning, where due to the different user behavior of the client, label distributions between different clients are significantly different. When faced with such cases, most existing methods will lead to a suboptimal optimization due to the inadequate utilization of label distribution information in clients. Inspired by this, we propose a label-masking distillation approach termed FedLMD to facilitate federated learning via perceiving the various label distributions of each client. We classify the labels into majority and minority labels based on the number of examples per class during training. The client model learns the knowledge of majority labels from local data. The process of distillation masks out the predictions of majority labels from the global model, so that it can focus more on preserving the minority label knowledge of the client. A series of experiments show that the proposed approach can achieve state-of-the-art performance in various cases. Moreover, considering the limited resources of the clients, we propose a variant FedLMD-Tf that does not require an additional teacher, which outperforms previous lightweight approaches without increasing computational costs. Our code is available at https://github.com/wnma3mz/FedLMD.