Assessing the Zero-Shot Capabilities of LLMs for Action Evaluation in RL
作者: Eduardo Pignatelli, Johan Ferret, Tim Rockäschel, Edward Grefenstette, Davide Paglieri, Samuel Coward, Laura Toni
分类: cs.LG, cs.AI
发布日期: 2024-09-19
备注: 9 pages
💡 一句话要点
提出CALM框架,利用LLM零样本能力解决强化学习中的动作评估问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 信用分配 大型语言模型 零样本学习 奖励塑造 选项发现 MiniHack
📋 核心要点
- 强化学习中,稀疏和延迟奖励使得动作评估困难,传统方法依赖人工设计,泛化性差。
- CALM框架利用LLM将任务分解为子目标,并评估动作对子目标达成的贡献,从而进行奖励塑造。
- 在MiniHack数据集上的初步实验表明,LLM可以在零样本设置下有效分配信用,提升学习效率。
📝 摘要(中文)
时间信用分配问题是强化学习(RL)中的一个核心挑战,它关注于如何评估轨迹中每个动作对实现目标的贡献。当反馈延迟且稀疏时,学习信号较弱,动作评估变得更加困难。传统的解决方案,如奖励塑造和选项,需要大量的领域知识和人工干预,限制了它们的可扩展性和适用性。本文提出了基于语言模型的信用分配(CALM)框架,该方法利用大型语言模型(LLM)通过奖励塑造和选项发现来自动进行信用分配。CALM使用LLM将任务分解为基本子目标,并评估状态-动作转移中这些子目标的实现情况。每次选项终止时,一个子目标就实现了,CALM提供一个辅助奖励。当任务奖励稀疏且延迟时,这种额外的奖励信号可以增强学习过程,而无需人工设计的奖励。我们使用来自MiniHack的人工标注演示数据集对CALM进行了初步评估,结果表明LLM可以在零样本设置中有效地分配信用,无需示例或LLM微调。初步结果表明,LLM的知识是RL中信用分配的一个有希望的先验,有助于将人类知识转移到价值函数中。
🔬 方法详解
问题定义:强化学习中的时间信用分配问题,即如何评估每个动作对最终目标达成的贡献。当奖励稀疏且延迟时,很难判断哪些动作是有效的,导致学习效率低下。现有的奖励塑造和选项方法需要大量人工干预和领域知识,难以扩展到复杂任务。
核心思路:利用大型语言模型(LLM)的知识和推理能力,将复杂任务分解为一系列易于评估的子目标。通过评估状态-动作转移对子目标达成的贡献,自动生成辅助奖励信号,从而改善信用分配,加速学习过程。核心在于利用LLM的零样本能力,无需针对特定任务进行微调。
技术框架:CALM框架包含以下主要步骤:1) 使用LLM将任务分解为一系列子目标。2) 在每个状态-动作转移后,使用LLM评估该转移对子目标达成的贡献。3) 根据LLM的评估结果,生成辅助奖励信号。4) 将辅助奖励信号与环境奖励结合,用于训练强化学习智能体。框架的关键在于LLM作为信用分配的先验知识来源。
关键创新:核心创新在于利用LLM的零样本能力进行自动信用分配,无需人工设计奖励函数或选项。这使得该方法具有更强的通用性和可扩展性。与传统的奖励塑造方法相比,CALM可以自动发现有用的子目标,并根据环境动态调整奖励信号。
关键设计:论文中使用了MiniHack环境进行实验,并使用人工标注的数据集来评估LLM的评估能力。具体的技术细节包括:如何使用LLM进行子目标分解,如何设计LLM的提示语(prompt),以及如何将LLM的评估结果转化为奖励信号。奖励信号的设计需要平衡探索和利用,避免过度塑造奖励导致次优策略。
🖼️ 关键图片
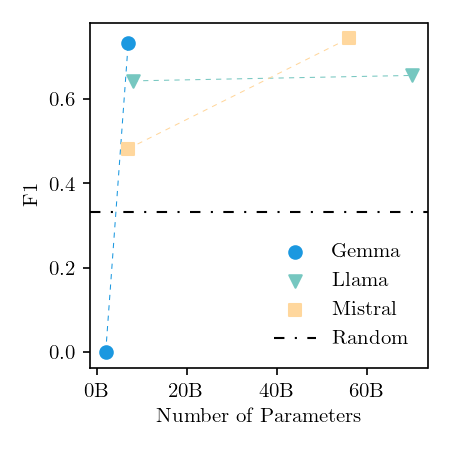


📊 实验亮点
论文在MiniHack数据集上进行了初步评估,结果表明LLM可以在零样本设置下有效地分配信用。虽然没有提供具体的性能数据和对比基线,但实验结果表明,利用LLM的知识可以改善强化学习的效率。该研究为利用LLM解决强化学习中的信用分配问题提供了一个有希望的方向。
🎯 应用场景
该研究成果可应用于各种需要稀疏或延迟奖励的强化学习任务,例如机器人导航、游戏AI和自动驾驶。通过利用LLM的知识,可以减少人工干预,提高强化学习算法的效率和泛化能力。未来,该方法可以扩展到更复杂的任务和环境,并与其他强化学习技术相结合,例如模仿学习和元学习。
📄 摘要(原文)
The temporal credit assignment problem is a central challenge in Reinforcement Learning (RL), concerned with attributing the appropriate influence to each actions in a trajectory for their ability to achieve a goal. However, when feedback is delayed and sparse, the learning signal is poor, and action evaluation becomes harder. Canonical solutions, such as reward shaping and options, require extensive domain knowledge and manual intervention, limiting their scalability and applicability. In this work, we lay the foundations for Credit Assignment with Language Models (CALM), a novel approach that leverages Large Language Models (LLMs) to automate credit assignment via reward shaping and options discovery. CALM uses LLMs to decompose a task into elementary subgoals and assess the achievement of these subgoals in state-action transitions. Every time an option terminates, a subgoal is achieved, and CALM provides an auxiliary reward. This additional reward signal can enhance the learning process when the task reward is sparse and delayed without the need for human-designed rewards. We provide a preliminary evaluation of CALM using a dataset of human-annotated demonstrations from MiniHack, suggesting that LLMs can be effective in assigning credit in zero-shot settings, without examples or LLM fine-tuning. Our preliminary results indicate that the knowledge of LLMs is a promising prior for credit assignment in RL, facilitating the transfer of human knowledge into value functions.