Is Tokenization Needed for Masked Particle Modelling?
作者: Matthew Leigh, Samuel Klein, François Charton, Tobias Golling, Lukas Heinrich, Michael Kagan, Inês Ochoa, Margarita Osadchy
分类: hep-ph, cs.LG
发布日期: 2024-09-19 (更新: 2024-10-01)
💡 一句话要点
改进掩码粒子建模,无需tokenization即可实现高能物理基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 掩码粒子建模 自监督学习 高能物理 喷注物理 条件生成模型
📋 核心要点
- 现有MPM方法在实现效率和解码器能力上存在不足,限制了其在高能物理领域的应用。
- 论文提出通过优化实现、引入更强大的解码器以及采用无需tokenization的条件生成模型来改进MPM。
- 实验表明,改进后的MPM在喷注物理的各种下游任务中,性能优于原始MPM的tokenized学习目标。
📝 摘要(中文)
本文显著增强了掩码粒子建模(MPM),这是一种自监督学习方案,用于构建高表达能力的无序集合表示,该表示与开发高能物理基础模型相关。在MPM中,模型被训练以恢复集合中缺失的元素,这种学习目标不需要标签,可以直接应用于实验数据。通过解决实现中的低效率问题并结合更强大的解码器,我们实现了相对于先前MPM工作的显著性能改进。我们比较了几个预训练任务,并引入了新的重建方法,该方法利用条件生成模型,无需数据tokenization或离散化。我们表明,这些新方法在用于喷注基础模型的新测试平台上优于原始MPM中的tokenized学习目标,该测试平台包括使用与喷注物理相关的各种下游任务,例如分类、二级顶点查找和径迹识别。
🔬 方法详解
问题定义:论文旨在解决高能物理领域中,如何更有效地学习无序粒子集合的表达问题。现有的掩码粒子建模(MPM)方法虽然能够进行自监督学习,但其实现效率较低,解码器能力有限,并且依赖于数据tokenization,这可能会引入额外的误差和计算开销。
核心思路:论文的核心思路是通过优化MPM的实现,引入更强大的解码器,并探索无需tokenization的条件生成模型,从而提高MPM的性能和效率。通过直接在连续空间中进行重建,避免了tokenization带来的信息损失。
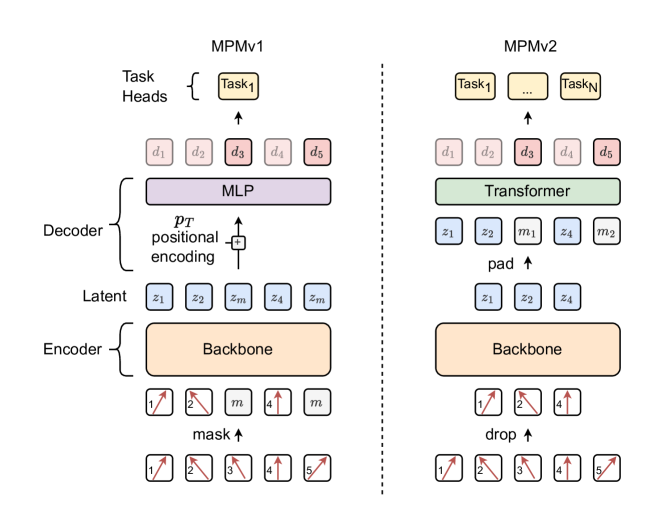
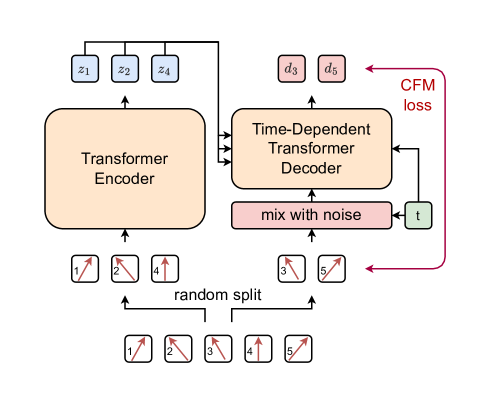
技术框架:整体框架包括以下几个主要模块:1) 编码器:将输入的粒子集合编码成潜在表示;2) 掩码模块:随机掩盖部分粒子;3) 解码器:基于编码后的潜在表示和剩余的粒子,重建被掩盖的粒子。论文探索了不同的解码器结构,并引入了条件生成模型。预训练阶段使用自监督的掩码重建任务,下游任务则利用预训练得到的编码器进行特征提取。
关键创新:最重要的技术创新点在于引入了无需tokenization的条件生成模型进行粒子重建。与原始MPM中使用的tokenized学习目标相比,这种方法可以直接在连续空间中进行重建,避免了离散化带来的信息损失。此外,论文还通过优化实现和引入更强大的解码器,提高了MPM的整体性能。
关键设计:论文探索了多种解码器结构,包括基于Transformer的解码器和条件生成模型。条件生成模型的设计需要仔细考虑如何将编码后的潜在表示和剩余的粒子信息有效地融合到生成过程中。损失函数采用重建误差,例如均方误差(MSE)或交叉熵损失(如果使用tokenization)。掩码比例是一个重要的超参数,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
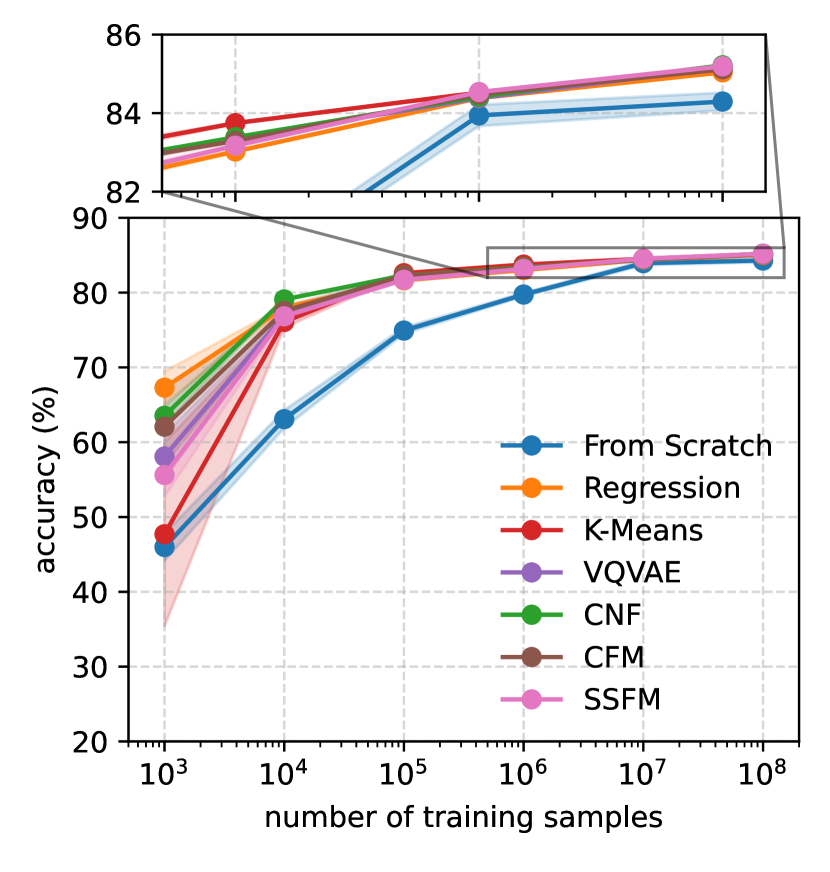
实验结果表明,改进后的MPM在喷注物理的各种下游任务中,性能优于原始MPM的tokenized学习目标。具体而言,在喷注分类任务中,改进后的MPM取得了显著的性能提升。此外,论文还展示了改进后的MPM在二级顶点查找和径迹识别等任务中的有效性,证明了其在高能物理领域的应用潜力。
🎯 应用场景
该研究成果可应用于高能物理领域,例如喷注分类、二级顶点查找和径迹识别等任务。通过学习高质量的粒子集合表示,可以提高这些任务的性能,并为开发高能物理领域的基础模型奠定基础。此外,该方法也可以推广到其他需要处理无序集合数据的领域,例如点云处理、社交网络分析等。
📄 摘要(原文)
In this work, we significantly enhance masked particle modeling (MPM), a self-supervised learning scheme for constructing highly expressive representations of unordered sets relevant to developing foundation models for high-energy physics. In MPM, a model is trained to recover the missing elements of a set, a learning objective that requires no labels and can be applied directly to experimental data. We achieve significant performance improvements over previous work on MPM by addressing inefficiencies in the implementation and incorporating a more powerful decoder. We compare several pre-training tasks and introduce new reconstruction methods that utilize conditional generative models without data tokenization or discretization. We show that these new methods outperform the tokenized learning objective from the original MPM on a new test bed for foundation models for jets, which includes using a wide variety of downstream tasks relevant to jet physics, such as classification, secondary vertex finding, and track identification.