Mixture of Diverse Size Experts
作者: Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, Bin Wang
分类: cs.LG, cs.AI
发布日期: 2024-09-18
💡 一句话要点
提出MoDSE:一种混合不同规模专家的MoE架构,提升LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 大型语言模型 模型扩展 稀疏激活 负载均衡
📋 核心要点
- 现有MoE模型专家规模相同,限制了tokens选择合适大小专家的能力,影响生成质量。
- MoDSE架构设计不同规模的专家层,使tokens能根据自身需求选择合适的专家。
- 实验表明,MoDSE在多个基准测试中优于现有MoE模型,且专家路由路径更稳定。
📝 摘要(中文)
稀疏激活的混合专家模型(MoE)在扩展大型语言模型(LLM)方面越来越受欢迎,因为它能在不大幅增加计算成本的情况下提升模型容量。然而,现有的MoE设计面临一个挑战,即所有专家都具有相同的大小,这限制了tokens选择最适合自身大小的专家来生成下一个token的能力。本文提出了一种混合不同规模专家的MoDSE架构,该架构的层被设计为具有不同大小的专家。我们对困难token生成任务的分析表明,各种规模的专家可以实现更好的预测,并且专家的路由路径在训练一段时间后趋于稳定。然而,拥有不同规模的专家可能会导致工作负载分配不均。为了解决这个限制,我们引入了一种专家对分配策略,以在多个GPU上均匀地分配工作负载。在多个基准上的综合评估表明了MoDSE的有效性,因为它通过自适应地将参数预算分配给专家,同时保持相同的总参数大小和专家数量,从而优于现有的MoE。
🔬 方法详解
问题定义:现有稀疏激活的混合专家模型(MoE)在扩展大型语言模型(LLM)时,所有专家都具有相同的大小。这种同质性限制了模型根据输入token的复杂性选择最合适的专家进行处理的能力,导致次优的性能。尤其是在处理需要不同粒度知识的token时,固定大小的专家可能无法提供最佳的表示。
核心思路:MoDSE的核心思路是引入不同大小的专家,允许模型根据输入token的特性,动态地选择最合适的专家进行处理。通过混合不同规模的专家,模型可以更好地适应不同复杂度的token,从而提高整体性能。这种设计旨在解决现有MoE模型中专家规模单一的局限性。
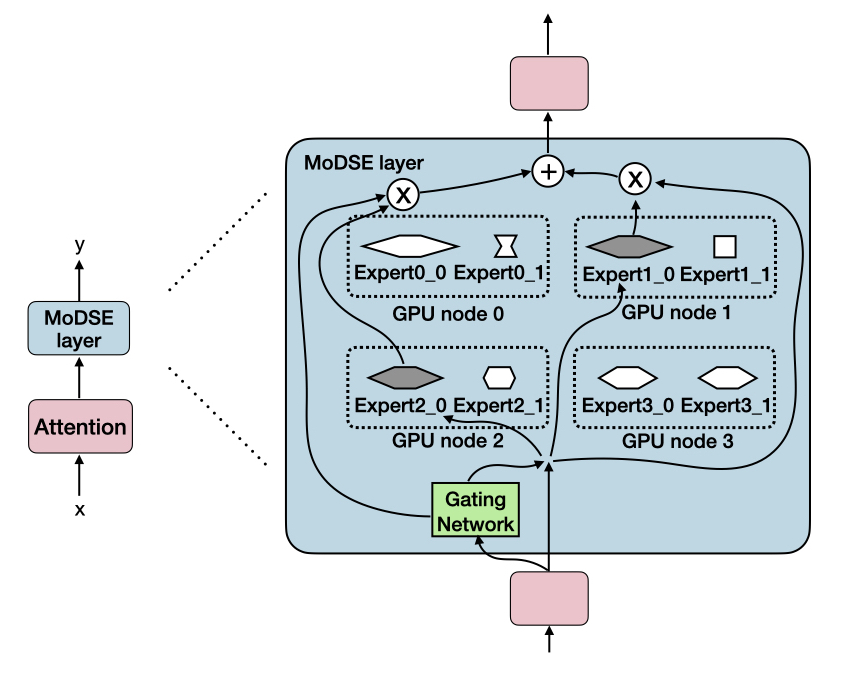
技术框架:MoDSE架构在MoE层中引入了不同大小的专家。整体流程与标准MoE类似,包括:1) 输入token经过embedding层;2) 通过路由网络(Router)决定将token分配给哪些专家;3) 被选中的专家并行处理token;4) 将专家输出的结果通过聚合网络(Combiner)进行加权融合,得到最终输出。关键区别在于,MoDSE的专家层包含多种规模的专家,路由网络需要学习如何将token分配给最合适的专家。
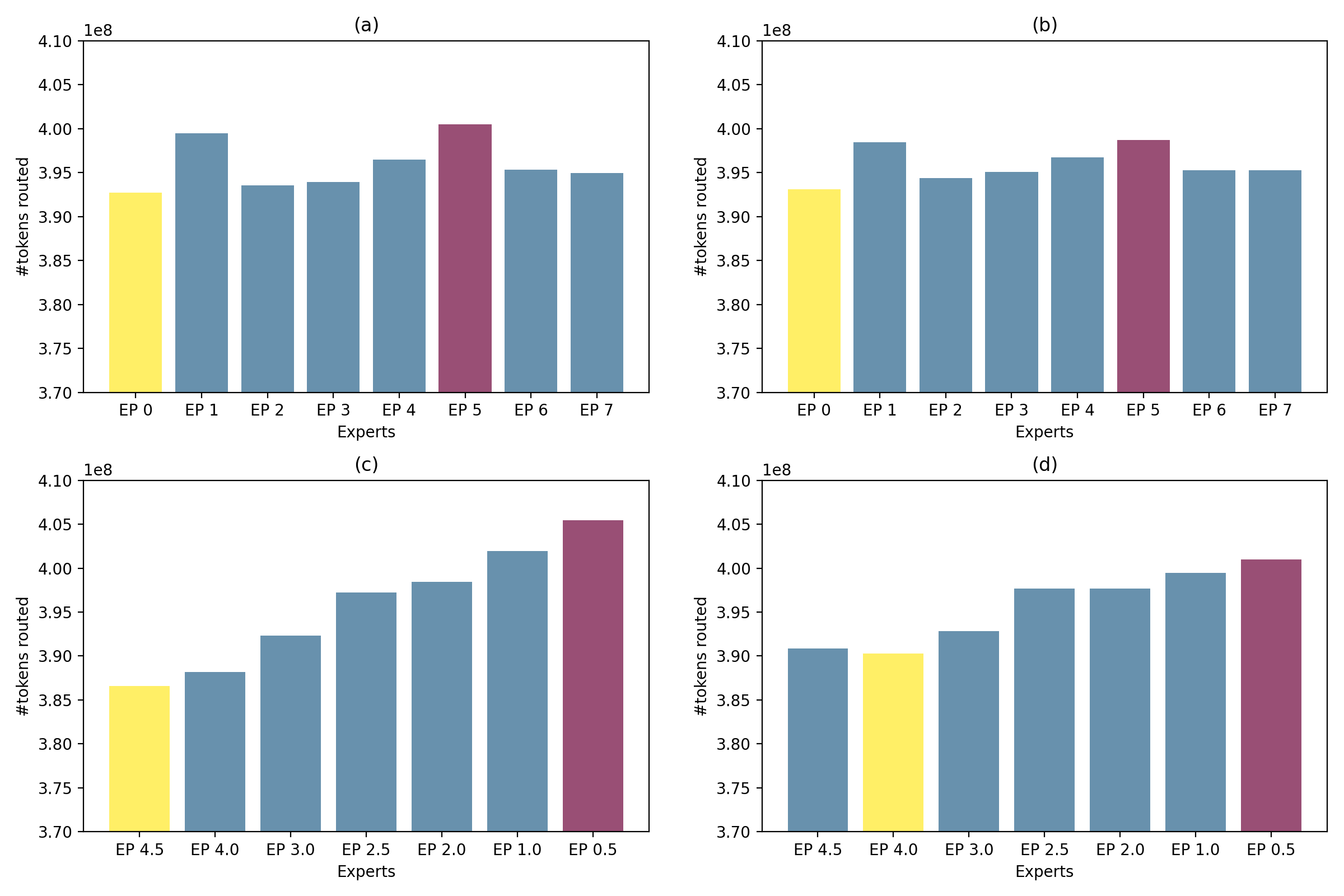
关键创新:MoDSE最重要的创新点在于引入了不同大小的专家。与现有MoE模型中所有专家大小相同不同,MoDSE允许专家具有不同的容量,从而更好地适应不同复杂度的token。此外,论文还提出了专家对分配策略,以解决不同规模专家带来的工作负载不均衡问题。
关键设计:MoDSE的关键设计包括:1) 专家规模的选择:论文中专家规模的选择是预先定义的,例如可以设置小、中、大三种规模的专家。2) 路由网络的设计:路由网络需要学习如何将token分配给不同规模的专家,可以使用标准的Top-K路由策略。3) 专家对分配策略:为了解决不同规模专家带来的工作负载不均衡问题,论文提出了一种专家对分配策略,将专家进行配对,确保每个GPU上的工作负载相对均衡。具体的损失函数和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
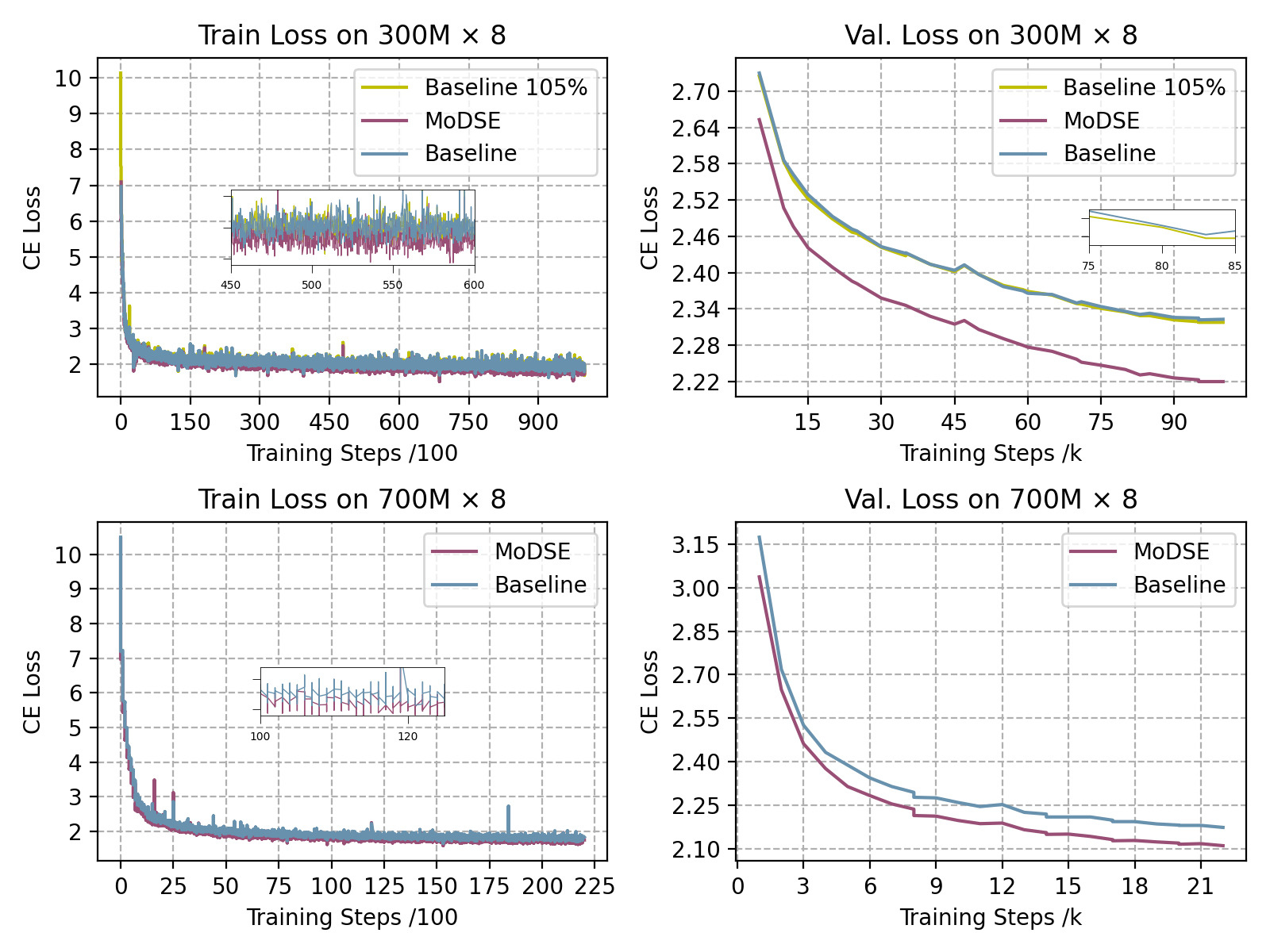
实验结果表明,MoDSE在多个基准测试中优于现有的MoE模型。具体来说,MoDSE在保持相同参数量和专家数量的情况下,能够自适应地将参数预算分配给不同规模的专家,从而提高模型的性能。论文中给出了具体的性能数据,但由于摘要中未提供详细数值,具体提升幅度未知。
🎯 应用场景
MoDSE架构可应用于各种需要大规模语言模型的场景,例如机器翻译、文本生成、对话系统等。通过自适应地分配参数给不同规模的专家,MoDSE可以在保持参数量不变的情况下,提升模型的性能。尤其是在处理复杂、多变的文本数据时,MoDSE的优势更加明显。未来,MoDSE有望成为构建更高效、更强大的大型语言模型的重要技术手段。
📄 摘要(原文)
The Sparsely-Activated Mixture-of-Experts (MoE) has gained increasing popularity for scaling up large language models (LLMs) without exploding computational costs. Despite its success, the current design faces a challenge where all experts have the same size, limiting the ability of tokens to choose the experts with the most appropriate size for generating the next token. In this paper, we propose the Mixture of Diverse Size Experts (MoDSE), a new MoE architecture with layers designed to have experts of different sizes. Our analysis of difficult token generation tasks shows that experts of various sizes achieve better predictions, and the routing path of the experts tends to be stable after a training period. However, having experts of diverse sizes can lead to uneven workload distribution. To tackle this limitation, we introduce an expert-pair allocation strategy to evenly distribute the workload across multiple GPUs. Comprehensive evaluations across multiple benchmarks demonstrate the effectiveness of MoDSE, as it outperforms existing MoEs by allocating the parameter budget to experts adaptively while maintaining the same total parameter size and the number of experts.