Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
作者: Jonas Günster, Puze Liu, Jan Peters, Davide Tateo
分类: cs.LG, cs.RO
发布日期: 2024-09-18 (更新: 2024-09-23)
备注: Preprint version of a paper accepted to the Conference on Robot Learning
💡 一句话要点
提出基于可学习约束的ATACOM扩展方法,解决安全强化学习中的长期安全和不确定性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 可学习约束 长期安全 不确定性处理 机器人控制
📋 核心要点
- 现有安全强化学习方法在复杂现实环境中部署困难,主要原因是缺乏对任务特定安全约束的有效处理。
- 该论文提出一种基于可学习约束的安全探索方法,扩展了ATACOM算法,旨在提升长期安全性和不确定性处理能力。
- 实验结果表明,该方法在最终性能上与现有方法相比具有竞争力或更优越,同时训练过程更加安全。
📝 摘要(中文)
安全是阻碍强化学习技术在现实机器人中部署的关键问题之一。虽然安全强化学习领域的大多数方法不需要约束和机器人运动学的先验知识,并且仅依赖于数据,但通常难以在复杂的现实环境中部署它们。相反,将约束和动力学的先验知识纳入学习框架的基于模型的方法已被证明能够直接在真实机器人上部署学习算法。不幸的是,虽然机器人动力学的近似模型通常是可用的,但安全约束是特定于任务的并且难以获得:它们可能太复杂而无法以分析方式编码,计算成本太高,或者难以先验地设想长期安全要求。在本文中,我们通过使用可学习约束扩展安全探索方法ATACOM来弥合这一差距,特别关注确保长期安全和处理不确定性。我们的方法在最终性能方面与最先进的方法相比具有竞争力或更优越,同时在训练期间保持更安全的行为。
🔬 方法详解
问题定义:现有安全强化学习方法,尤其是在机器人领域,面临着安全约束难以获取和建模的问题。任务相关的安全约束通常过于复杂,难以用解析形式表达,或者计算成本过高。此外,长期安全需求难以预先确定,导致传统方法在实际部署中存在安全风险。
核心思路:该论文的核心思路是将安全约束建模为一个可学习的模块,通过学习的方式来逼近真实的约束条件。同时,扩展现有的安全探索算法ATACOM,使其能够利用学习到的约束进行安全探索,从而在训练过程中避免进入不安全区域。这种方法结合了基于模型的强化学习和数据驱动的学习方法,能够在利用先验知识的同时,适应未知的安全约束。
技术框架:整体框架基于ATACOM算法,主要包含以下几个模块:1)环境模型:用于预测机器人动力学;2)策略学习模块:用于学习控制策略;3)安全约束学习模块:用于学习安全约束条件;4)安全探索模块:利用学习到的约束和环境模型进行安全探索。算法流程大致为:首先,利用少量数据初始化环境模型和安全约束模型;然后,在每个迭代中,利用环境模型和安全约束模型进行策略优化和安全探索;最后,利用新的数据更新环境模型和安全约束模型。
关键创新:该论文的关键创新在于将安全约束建模为一个可学习的模块,并将其集成到安全探索算法中。这种方法能够有效地处理未知的安全约束,并且能够保证长期安全性。与传统方法相比,该方法不需要预先定义安全约束,而是通过学习的方式来逼近真实的约束条件,从而提高了算法的适应性和鲁棒性。
关键设计:安全约束学习模块可以使用各种机器学习模型,例如神经网络、高斯过程等。论文中可能采用了特定的网络结构或损失函数来训练安全约束模型。安全探索模块的设计需要考虑如何平衡探索和利用,以及如何避免进入不安全区域。具体的参数设置和算法细节需要在论文中查找。
🖼️ 关键图片
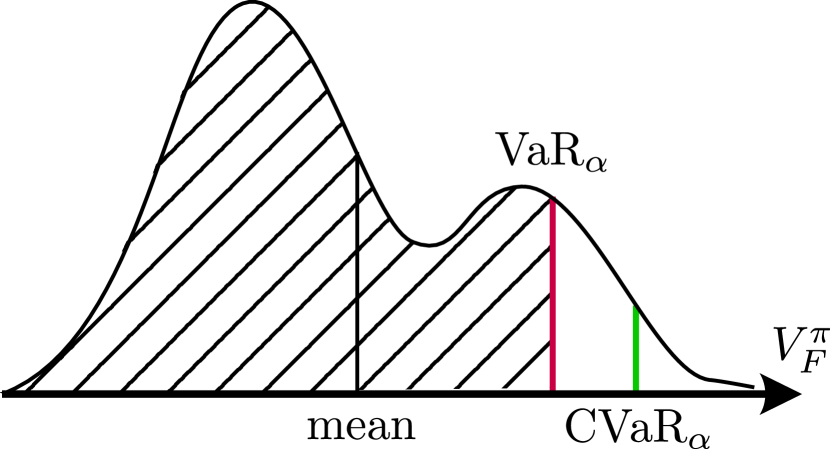
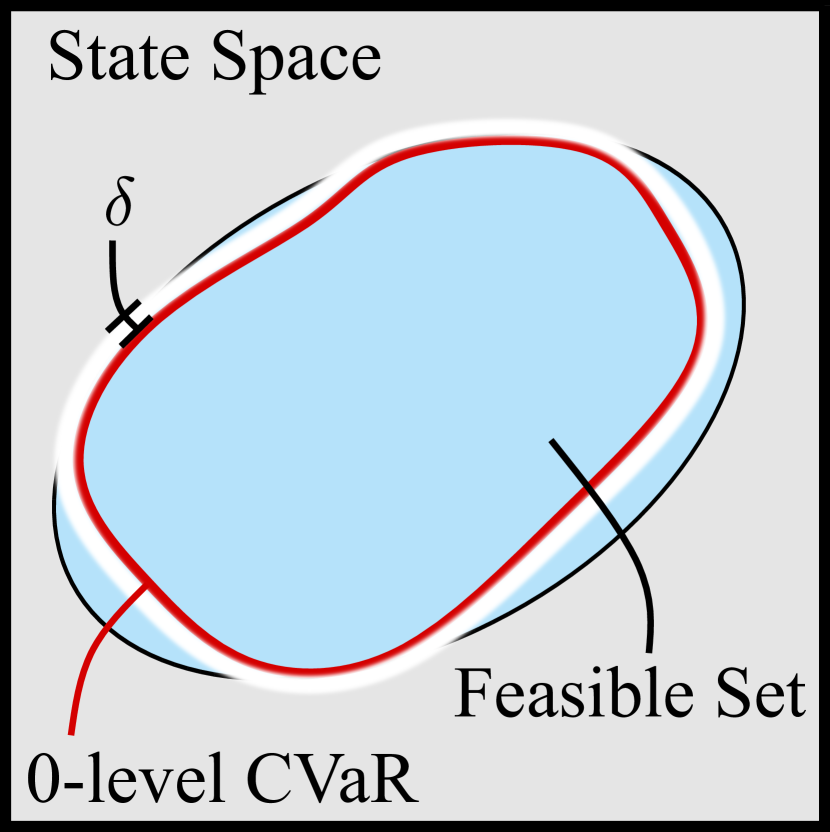
📊 实验亮点
论文提出的方法在实验中表现出优异的性能,与现有最先进的方法相比,在保证安全性的前提下,取得了具有竞争力的甚至更优越的最终性能。这意味着该方法能够在训练过程中更有效地避免进入不安全区域,并且能够学习到更好的控制策略。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要安全保障的机器人应用场景,例如自动驾驶、工业机器人、医疗机器人等。通过学习任务特定的安全约束,机器人能够在复杂环境中安全可靠地完成任务,降低事故发生的风险,提高生产效率。此外,该方法还可以应用于其他安全关键领域,例如金融风控、智能电网等。
📄 摘要(原文)
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.