RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
作者: Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili Qiu
分类: cs.LG, cs.CL
发布日期: 2024-09-16 (更新: 2024-12-31)
备注: 19 pages
💡 一句话要点
RetrievalAttention:通过向量检索加速长文本LLM推理,降低显存占用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 推理加速 向量检索 近似最近邻搜索 显存优化
📋 核心要点
- 长文本LLM推理面临attention计算的平方时间复杂度问题,导致推理速度慢、GPU显存消耗高。
- RetrievalAttention通过构建KV向量的近似最近邻搜索索引,并进行attention感知的向量检索,实现稀疏attention计算。
- 实验表明,该方法在保证精度的前提下,显著降低了推理成本和显存占用,单张4090即可支持8B模型128K上下文。
📝 摘要(中文)
本文提出RetrievalAttention,一种无需训练的方法,旨在加速attention计算并减少GPU内存消耗。该方法利用attention机制的动态稀疏性,在CPU内存中为KV向量构建近似最近邻搜索(ANNS)索引,并在生成过程中通过向量搜索检索最相关的KV向量。针对query向量和key向量之间存在的分布外(OOD)问题,RetrievalAttention设计了一种attention感知的向量搜索算法,使其能够适应query向量的分布。评估表明,RetrievalAttention仅需访问1-3%的数据即可实现接近完整attention的精度,从而显著降低长文本LLM的推理成本,并大幅减少GPU内存占用。例如,RetrievalAttention仅需单张NVIDIA RTX4090 (24GB)即可为具有80亿参数的LLM提供128K tokens的服务,生成一个token仅需0.188秒。
🔬 方法详解
问题定义:现有长文本LLM推理面临的主要问题是attention机制的计算复杂度。由于attention计算的时间复杂度是序列长度的平方,因此处理长文本时,推理速度会显著下降,并且需要大量的GPU内存来缓存key-value (KV)向量。现有方法难以在保证性能的同时,有效降低计算和存储成本。
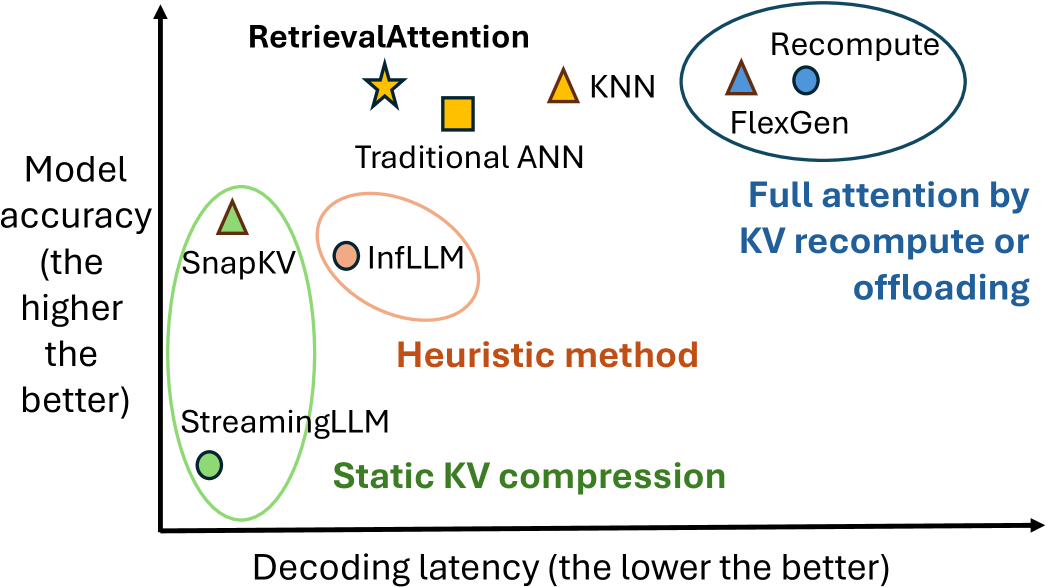
核心思路:RetrievalAttention的核心思路是利用attention机制的动态稀疏性。并非所有KV向量都对当前query向量有同等重要的影响,因此可以通过只关注最相关的KV向量来近似完整的attention计算。通过向量检索的方式,快速找到与当前query向量最相关的KV向量子集,从而减少计算量和内存占用。
技术框架:RetrievalAttention的整体框架包括以下几个主要阶段:1) 索引构建:在CPU内存中为KV向量构建近似最近邻搜索(ANNS)索引。2) 向量检索:在生成过程中,对于每个query向量,使用ANNS索引检索最相关的KV向量。3) Attention计算:仅使用检索到的KV向量子集进行attention计算。4) 结果融合:将稀疏attention的结果与原始query向量进行融合,得到最终的输出。
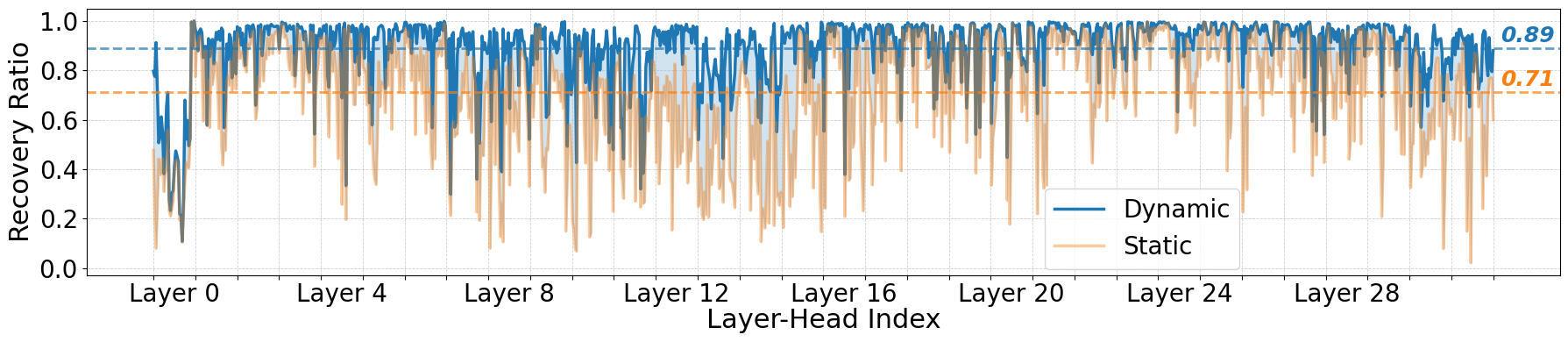
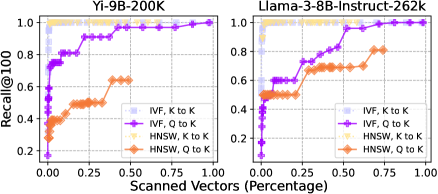
关键创新:RetrievalAttention的关键创新在于其attention感知的向量搜索算法。作者观察到,query向量和key向量之间存在分布外(OOD)问题,导致直接使用现成的ANNS索引效果不佳。为了解决这个问题,RetrievalAttention设计了一种能够适应query向量分布的向量搜索算法,从而提高检索的准确性。
关键设计:RetrievalAttention的关键设计包括:1) 使用CPU内存存储ANNS索引,以减少GPU内存占用。2) 设计attention感知的向量搜索算法,例如通过调整检索策略或引入额外的query向量表示,来适应query向量的分布。3) 通过实验确定合适的检索比例(例如,只检索1-3%的KV向量),以在精度和效率之间取得平衡。
🖼️ 关键图片
📊 实验亮点
RetrievalAttention在长文本LLM推理方面取得了显著的性能提升。实验结果表明,该方法仅需访问1-3%的KV向量即可实现接近完整attention的精度。在具有80亿参数的LLM上,使用RetrievalAttention仅需单张NVIDIA RTX4090 (24GB)即可支持128K tokens的上下文长度,并且生成一个token仅需0.188秒。这表明RetrievalAttention能够有效降低推理成本和显存占用。
🎯 应用场景
RetrievalAttention具有广泛的应用前景,尤其是在需要处理长文本的场景中,例如长文档摘要、代码生成、对话系统等。该方法可以显著降低长文本LLM的推理成本,使其能够在资源受限的设备上运行,并加速在线推理服务。此外,该方法还可以促进更大规模LLM的开发和应用,因为它可以降低训练和部署的显存需求。
📄 摘要(原文)
Transformer-based Large Language Models (LLMs) have become increasingly important. However, due to the quadratic time complexity of attention computation, scaling LLMs to longer contexts incurs extremely slow inference speed and high GPU memory consumption for caching key-value (KV) vectors. This paper proposes RetrievalAttention, a training-free approach to both accelerate attention computation and reduce GPU memory consumption. By leveraging the dynamic sparsity of attention mechanism, RetrievalAttention proposes to build approximate nearest neighbor search (ANNS) indexes for KV vectors in CPU memory and retrieve the most relevant ones through vector search during generation. Unfortunately, we observe that the off-the-shelf ANNS indexes are often ineffective for such retrieval tasks due to the out-of-distribution (OOD) between query vectors and key vectors in the attention mechanism. RetrievalAttention addresses the OOD challenge by designing an attention-aware vector search algorithm that can adapt to the distribution of query vectors. Our evaluation demonstrates that RetrievalAttention achieves near full attention accuracy while only requiring access to 1--3% of the data. This leads to a significant reduction in the inference cost of long-context LLMs, with a much lower GPU memory footprint. In particular, RetrievalAttention only needs a single NVIDIA RTX4090 (24GB) to serve 128K tokens for LLMs with 8B parameters, which is capable of generating one token in 0.188 seconds.