Turbo your multi-modal classification with contrastive learning
作者: Zhiyu Zhang, Da Liu, Shengqiang Liu, Anna Wang, Jie Gao, Yali Li
分类: cs.LG, cs.MM
发布日期: 2024-09-14
💡 一句话要点
提出Turbo对比学习策略,提升多模态分类任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态学习 对比学习 模态内对比 跨模态对比 语音情感识别 音频文本分类 自监督学习
📋 核心要点
- 现有方法侧重跨模态理解,忽略模态内对比学习,限制了各模态的表征能力。
- 提出Turbo对比学习策略,通过联合模态内和跨模态对比学习,提升多模态理解。
- 在音频-文本分类任务上验证有效性,并在语音情感识别数据集上取得SOTA性能。
📝 摘要(中文)
对比学习已成为多模态表征学习中最令人印象深刻的方法之一。然而,以往的多模态工作主要集中于跨模态理解,忽略了模态内对比学习,这限制了每个模态的表征能力。本文提出了一种新的对比学习策略,称为$Turbo$,通过联合模态内和跨模态对比学习来促进多模态理解。具体来说,多模态数据对通过前向传播两次,每次使用不同的隐藏dropout掩码,从而为每个模态获得两个不同的表征。利用这些表征,我们获得了多个模态内和跨模态对比目标用于训练。最后,我们将自监督的Turbo与监督的多模态分类相结合,并在两个音频-文本分类任务上证明了其有效性,在语音情感识别基准数据集上取得了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决多模态分类任务中,如何有效利用对比学习提升模型性能的问题。现有方法主要关注跨模态信息交互,忽略了模态内部的表征学习,导致模型对单个模态的理解不够深入,限制了整体性能的提升。
核心思路:论文的核心思路是通过联合模态内和跨模态对比学习,同时优化模型对单个模态和多个模态之间关系的理解。通过引入模态内对比学习,增强模型对单个模态特征的提取和表征能力,从而提升多模态分类的准确性。
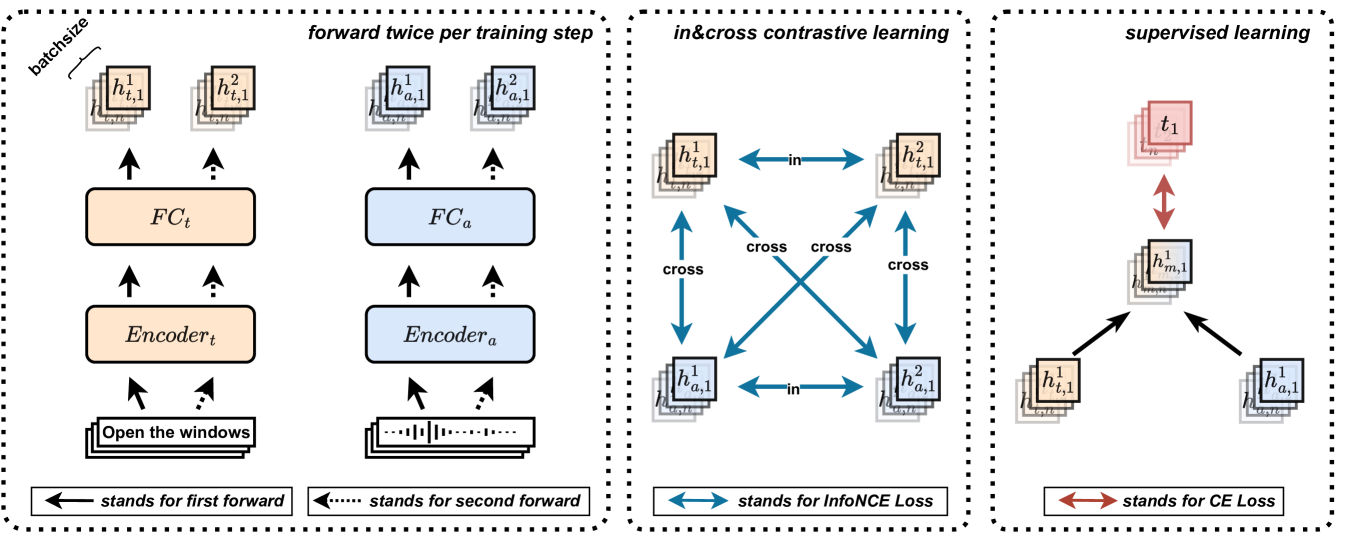
技术框架:Turbo框架主要包含以下几个阶段:1) 对输入的多模态数据(如音频和文本)进行预处理;2) 将数据输入到各自的模态编码器中,得到模态表征;3) 对每个模态的表征,使用不同的dropout掩码进行两次前向传播,得到两组不同的表征;4) 基于这些表征,构建模态内和跨模态的对比学习目标;5) 将对比学习目标与监督分类目标结合,进行联合训练。
关键创新:论文的关键创新在于提出了联合模态内和跨模态对比学习的Turbo策略。与现有方法只关注跨模态对比学习不同,Turbo同时考虑了模态内部的表征学习,从而更全面地提升了多模态表征的质量。通过dropout引入的表征差异,使得对比学习更具挑战性,从而提升了模型的泛化能力。
关键设计:Turbo的关键设计包括:1) 使用不同的dropout掩码生成不同的模态表征;2) 构建模态内对比损失,鼓励同一模态的不同表征尽可能相似;3) 构建跨模态对比损失,鼓励不同模态的表征尽可能相关;4) 将对比学习损失与交叉熵分类损失进行加权求和,得到最终的训练目标。具体的权重参数需要根据实验进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Turbo策略在两个音频-文本分类任务上取得了显著的性能提升。在语音情感识别基准数据集上,Turbo方法达到了state-of-the-art的水平,相较于之前的最佳方法,性能提升了超过2%。这验证了Turbo策略在多模态表征学习方面的有效性。
🎯 应用场景
该研究成果可广泛应用于多模态信息处理领域,例如语音情感识别、视频内容理解、多模态对话系统等。通过提升模型对多模态数据的理解能力,可以改善人机交互体验,提高信息检索效率,并为智能决策提供更准确的依据。未来,该方法有望扩展到更多模态组合和更复杂的应用场景。
📄 摘要(原文)
Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.