Exploring Graph Structure Comprehension Ability of Multimodal Large Language Models: Case Studies
作者: Zhiqiang Zhong, Davide Mottin
分类: cs.LG, cs.AI
发布日期: 2024-09-13
💡 一句话要点
探索多模态大语言模型图结构理解能力:案例研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图神经网络 大语言模型 图可视化 知识图谱
📋 核心要点
- 现有图表示方法主要依赖文本编码,忽略了图的视觉信息,限制了LLM对图结构的全面理解。
- 该研究探索了多模态LLM利用图可视化的能力,旨在提升LLM在图结构理解任务中的性能。
- 实验对比了多模态与纯文本方法在节点、边和图级别任务上的表现,揭示了视觉模态的优势与不足。
📝 摘要(中文)
大型语言模型(LLM)在处理包括图在内的各种数据结构方面表现出了卓越的能力。虽然之前的研究主要集中在开发用于图表示的文本编码方法,但多模态LLM的出现为图理解开辟了一个新的前沿。这些能够处理文本和图像的先进模型,通过结合视觉表示和传统的文本数据,为改进图理解提供了潜在的可能性。本研究调查了图可视化对LLM在节点、边和图级别的一系列基准任务上的性能的影响。我们的实验比较了多模态方法与纯文本图表示的有效性。结果为利用视觉图模态来增强LLM的图结构理解能力的潜力和局限性提供了有价值的见解。
🔬 方法详解
问题定义:论文旨在研究多模态大语言模型(MLLM)在理解图结构方面的能力。现有方法主要依赖于文本编码来表示图,这种方法忽略了图的视觉信息,可能导致LLM无法充分理解图的结构和关系。因此,如何有效地利用图的视觉信息来增强LLM的图理解能力是一个关键问题。
核心思路:论文的核心思路是探索将图的视觉表示(即图的可视化图像)与文本表示相结合,输入到多模态LLM中,从而提升LLM对图结构的理解能力。通过让LLM同时处理图的文本描述和视觉呈现,模型可以更全面地捕捉图的特征,从而在各种图相关的任务中表现更好。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择或构建图数据集,包含节点、边和图级别的任务;2) 将图数据转换为文本表示和视觉表示(图可视化);3) 使用多模态LLM(例如,能够同时处理文本和图像的模型)作为核心模型;4) 将文本表示和视觉表示输入到多模态LLM中进行训练或评估;5) 对比多模态方法与纯文本方法在各种图任务上的性能。
关键创新:该研究的关键创新在于探索了多模态LLM在图结构理解方面的潜力,并验证了图可视化在增强LLM图理解能力方面的有效性。与以往主要关注文本编码的方法不同,该研究将视觉信息引入到图表示中,为LLM提供了更丰富的图结构信息。
关键设计:具体的技术细节可能包括:1) 图可视化的方法选择(例如,节点链接图、邻接矩阵可视化等);2) 多模态LLM的选择和配置(例如,选择具有图像编码能力的LLM,并调整其参数以适应图任务);3) 文本表示的设计(例如,使用节点属性、边关系等信息生成文本描述);4) 实验评估指标的选择(例如,节点分类准确率、边预测准确率、图分类准确率等)。具体的损失函数和网络结构取决于所使用的多模态LLM。
🖼️ 关键图片

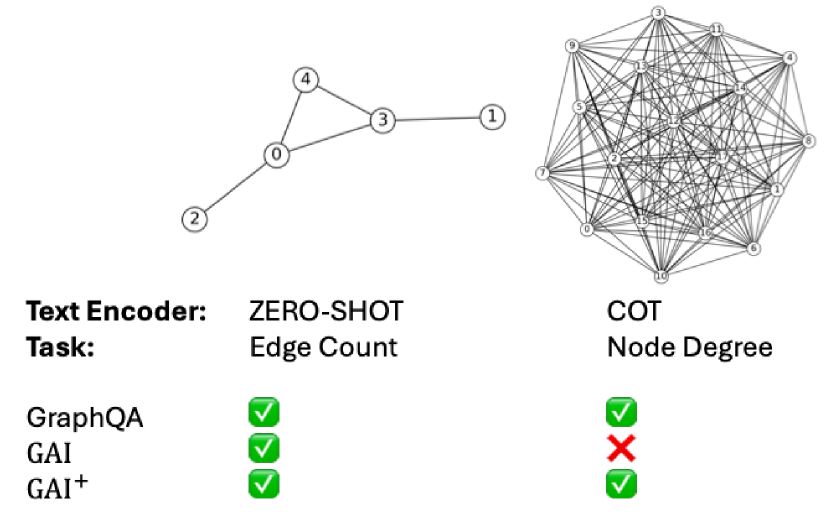
📊 实验亮点
实验结果表明,在某些图任务中,多模态LLM结合图可视化能够显著提升性能,尤其是在需要理解图结构的任务上。与纯文本方法相比,多模态方法在节点分类、边预测和图分类等任务上均取得了一定的提升。具体的性能提升幅度取决于数据集和任务的复杂度,但整体趋势表明视觉信息对于图理解是有益的。
🎯 应用场景
该研究成果可应用于知识图谱问答、社交网络分析、生物信息学等领域。通过提升LLM对图结构的理解能力,可以更有效地从复杂网络中提取信息,辅助决策,并加速相关领域的研究进展。未来,该方法有望应用于更复杂的图结构和更大规模的数据集。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in processing various data structures, including graphs. While previous research has focused on developing textual encoding methods for graph representation, the emergence of multimodal LLMs presents a new frontier for graph comprehension. These advanced models, capable of processing both text and images, offer potential improvements in graph understanding by incorporating visual representations alongside traditional textual data. This study investigates the impact of graph visualisations on LLM performance across a range of benchmark tasks at node, edge, and graph levels. Our experiments compare the effectiveness of multimodal approaches against purely textual graph representations. The results provide valuable insights into both the potential and limitations of leveraging visual graph modalities to enhance LLMs' graph structure comprehension abilities.