Generated Data with Fake Privacy: Hidden Dangers of Fine-tuning Large Language Models on Generated Data
作者: Atilla Akkus, Masoud Poorghaffar Aghdam, Mingjie Li, Junjie Chu, Michael Backes, Yang Zhang, Sinem Sav
分类: cs.CR, cs.LG
发布日期: 2024-09-12 (更新: 2025-01-29)
备注: Accepted at 34th USENIX Security Symposium, 2025
💡 一句话要点
揭示微调LLM生成数据带来的隐私风险:PII泄露与成员推断攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私风险 生成数据 微调 成员推断攻击
📋 核心要点
- 现有方法依赖合成数据微调LLM以规避隐私风险,但LLM生成数据与真实数据日益接近,其隐私风险未被充分评估。
- 该研究通过分析LLM生成数据的结构特征,评估使用其进行监督微调(SFT)和自指令调优的隐私风险。
- 实验表明,使用LLM生成数据微调后,PII泄露率显著增加,成员推断攻击成功率也大幅提升,揭示了潜在的隐私风险。
📝 摘要(中文)
大型语言模型(LLM)在各种特定领域任务中表现出显著的成功,并且在微调后性能通常会得到大幅提升。然而,使用真实数据进行微调会引入隐私风险。为了降低这些风险,开发者越来越多地依赖于合成数据生成,因为传统模型生成的数据被认为与真实数据不同。但是,随着LLM的先进能力,真实数据和LLM生成数据之间的区别几乎变得无法区分。这种融合为生成数据带来了与真实数据相关的类似隐私风险。本研究调查了使用LLM生成数据进行微调是否真正增强了隐私,或者通过检查LLM生成数据的结构特征引入了额外的隐私风险,重点关注两种主要的微调方法:使用非结构化(纯文本)生成数据的监督微调(SFT)和自指令调优。在SFT场景中,数据被放入先前研究使用的特定指令调优格式中。我们使用个人信息标识符(PII)泄露和Pythia模型套件及Open Pre-trained Transformer(OPT)上的成员推断攻击(MIA)来衡量隐私风险。值得注意的是,在使用非结构化生成数据进行微调后,Pythia成功提取PII的比率增加了20%以上,突显了这种方法的潜在隐私影响。此外,自指令调优后,Pythia-6.9b(该套件中第二大的模型)的MIA的ROC-AUC得分提高了40%以上。我们的结果表明了使用生成数据微调LLM相关的潜在隐私风险,强调需要在这种方法中仔细考虑隐私保护措施。
🔬 方法详解
问题定义:论文旨在研究使用大型语言模型(LLM)生成的合成数据进行微调是否会引入隐私风险。现有方法认为合成数据可以避免真实数据带来的隐私问题,但随着LLM生成能力增强,合成数据与真实数据越来越难以区分,其潜在的隐私风险尚未得到充分评估。
核心思路:论文的核心思路是通过分析LLM生成数据的结构特征,评估使用这些数据进行微调后,模型是否更容易泄露个人信息(PII)或受到成员推断攻击(MIA)。通过量化这些隐私风险,揭示使用LLM生成数据微调的潜在问题。
技术框架:论文主要采用两种微调方法进行实验:监督微调(SFT)和自指令调优。SFT使用非结构化的LLM生成数据,并将其转换为特定的指令调优格式。自指令调优则利用LLM自身生成指令和数据进行微调。然后,使用PII泄露率和MIA的ROC-AUC得分作为指标,评估微调后模型的隐私风险。实验对象包括Pythia模型套件和Open Pre-trained Transformer (OPT)。
关键创新:该研究的关键创新在于揭示了使用LLM生成数据进行微调可能带来的隐私风险。与传统观念认为合成数据可以保护隐私不同,该研究表明,由于LLM生成数据与真实数据的相似性,使用其进行微调反而可能增加隐私泄露的风险。
关键设计:在SFT中,论文采用了标准的指令调优格式。在MIA中,使用了ROC-AUC作为评估指标,以衡量攻击者区分训练集和非训练集数据的能力。具体参数设置和模型结构遵循Pythia和OPT的默认配置,重点关注微调数据对隐私风险的影响。
🖼️ 关键图片

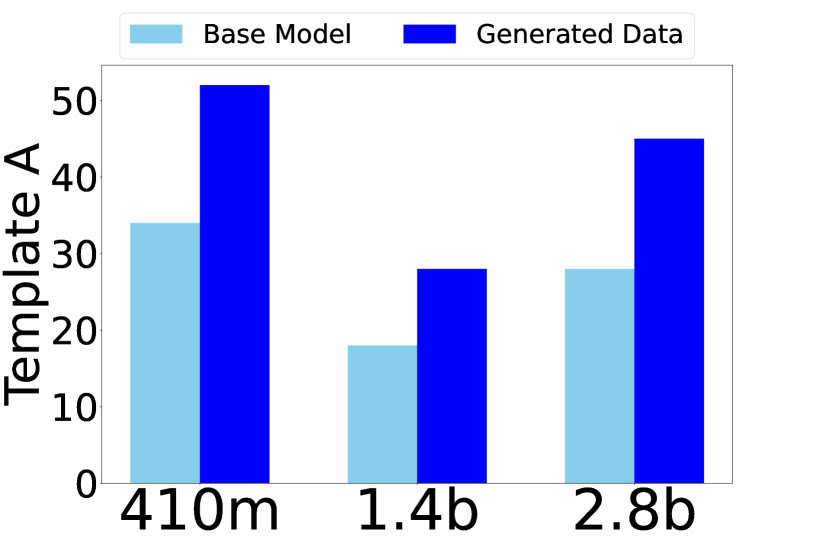

📊 实验亮点
实验结果表明,使用非结构化生成数据进行微调后,Pythia模型成功提取PII的比率增加了20%以上。此外,自指令调优后,Pythia-6.9b模型的MIA的ROC-AUC得分提高了40%以上。这些数据清晰地表明,使用LLM生成数据进行微调可能会显著增加模型的隐私风险。
🎯 应用场景
该研究结果对LLM的开发和应用具有重要意义。在需要保护用户隐私的场景下,例如医疗、金融等领域,开发者需要谨慎评估使用LLM生成数据进行微调的风险,并采取相应的隐私保护措施,例如差分隐私、对抗训练等。该研究也为未来研究LLM隐私风险提供了新的思路和方法。
📄 摘要(原文)
Large language models (LLMs) have demonstrated significant success in various domain-specific tasks, with their performance often improving substantially after fine-tuning. However, fine-tuning with real-world data introduces privacy risks. To mitigate these risks, developers increasingly rely on synthetic data generation as an alternative to using real data, as data generated by traditional models is believed to be different from real-world data. However, with the advanced capabilities of LLMs, the distinction between real data and data generated by these models has become nearly indistinguishable. This convergence introduces similar privacy risks for generated data to those associated with real data. Our study investigates whether fine-tuning with LLM-generated data truly enhances privacy or introduces additional privacy risks by examining the structural characteristics of data generated by LLMs, focusing on two primary fine-tuning approaches: supervised fine-tuning (SFT) with unstructured (plain-text) generated data and self-instruct tuning. In the scenario of SFT, the data is put into a particular instruction tuning format used by previous studies. We use Personal Information Identifier (PII) leakage and Membership Inference Attacks (MIAs) on the Pythia Model Suite and Open Pre-trained Transformer (OPT) to measure privacy risks. Notably, after fine-tuning with unstructured generated data, the rate of successful PII extractions for Pythia increased by over 20%, highlighting the potential privacy implications of such approaches. Furthermore, the ROC-AUC score of MIAs for Pythia-6.9b, the second biggest model of the suite, increases over 40% after self-instruct tuning. Our results indicate the potential privacy risks associated with fine-tuning LLMs using generated data, underscoring the need for careful consideration of privacy safeguards in such approaches.