DiReDi: Distillation and Reverse Distillation for AIoT Applications
作者: Chen Sun, Qing Tong, Wenshuang Yang, Wenqi Zhang
分类: cs.LG, cs.AI, cs.DC
发布日期: 2024-09-12
💡 一句话要点
提出DiReDi框架,通过知识蒸馏与反向蒸馏实现AIoT边缘模型自适应更新与用户隐私保护。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: AIoT 边缘计算 知识蒸馏 反向蒸馏 模型更新 隐私保护 联邦学习
📋 核心要点
- 边缘AI模型难以针对每个用户的特定应用进行定制,且扩展到新的应用场景面临挑战,不当的本地训练可能导致模型故障。
- DiReDi框架通过知识蒸馏和反向蒸馏,在保护用户隐私的前提下,使云端模型能够学习用户数据中的知识,并更新边缘模型。
- 仿真结果表明,DiReDi框架能够利用用户私有数据学习新知识,更新用户模型,并减少了初始冗余知识。
📝 摘要(中文)
本文提出了一种名为“DiReDi”的创新框架,该框架结合了知识蒸馏(KD)和反向蒸馏(RD)技术,旨在解决AIoT应用中边缘AI模型定制化和更新的难题。首先,边缘AI模型使用预设数据进行训练,并通过云服务器上的大型AI模型进行知识蒸馏。然后,将该边缘AI模型部署到用户的边缘设备上进行推理。当用户需要更新模型以适应实际场景时,采用反向蒸馏过程,从边缘AI模型中提取用户偏好与制造商预设之间的知识差异,并仅将提取的知识报告回云服务器,从而保护用户隐私。更新后的云AI模型可以利用扩展的知识来更新边缘AI模型。仿真结果表明,DiReDi框架允许制造商通过学习用户实际场景中的新知识来更新用户模型,同时保护用户私有数据。由于重新训练侧重于用户私有数据,因此减少了初始冗余知识。
🔬 方法详解
问题定义:现有边缘AI模型难以针对用户特定场景进行定制和更新,用户本地训练存在模型失效风险,同时用户数据隐私难以保障。现有方法无法在保护用户隐私的前提下,使云端模型学习用户数据中的知识,并更新边缘模型。
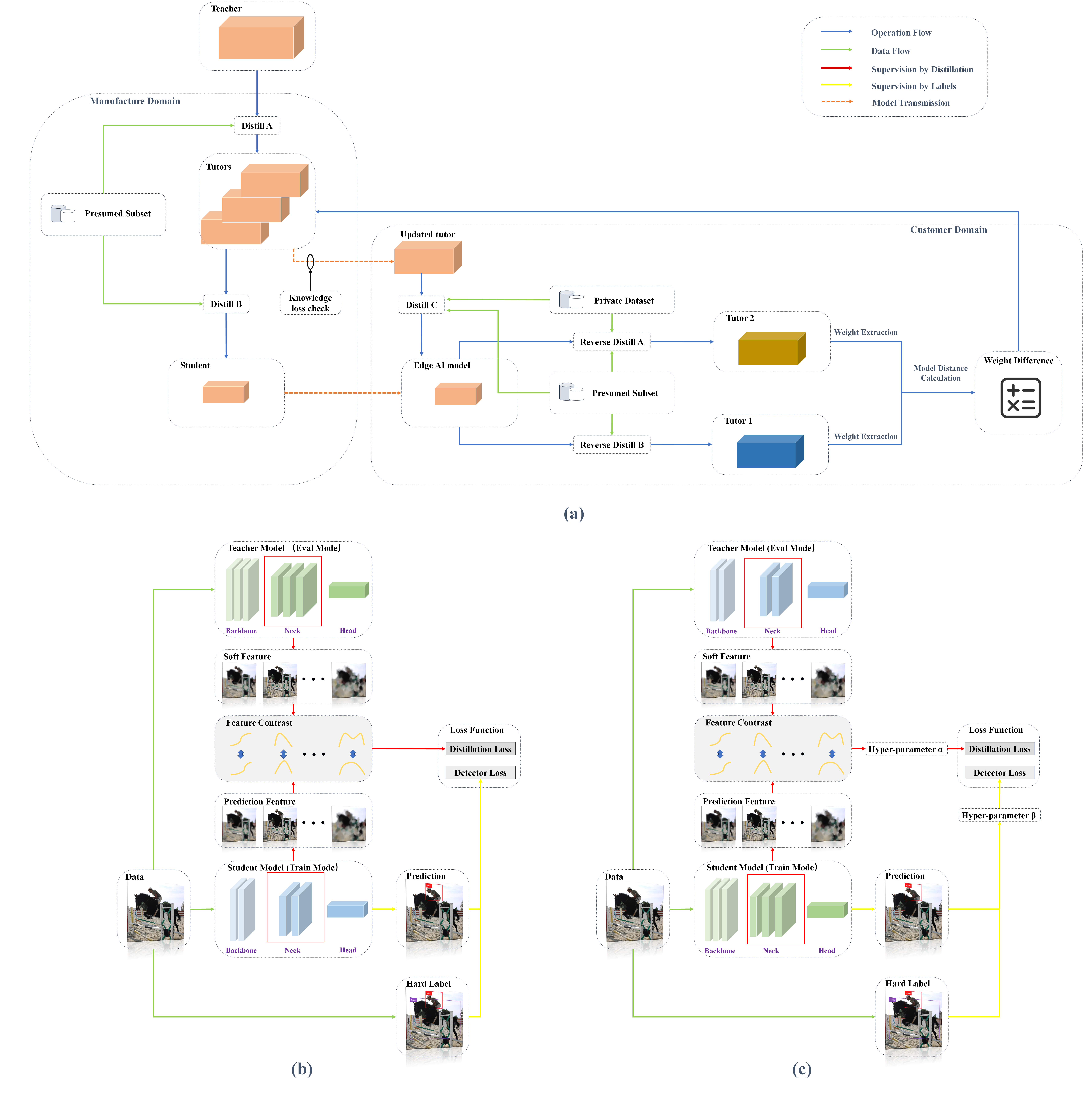
核心思路:利用知识蒸馏(KD)将云端模型的知识迁移到边缘模型,实现模型的初始化。通过反向蒸馏(RD)提取边缘模型中蕴含的用户特定知识,并将该知识安全地传递回云端模型,从而实现模型的自适应更新,同时避免直接上传用户数据,保护用户隐私。
技术框架:DiReDi框架包含以下几个主要阶段:1) 边缘模型初始化:使用预设数据训练边缘模型,并通过云端模型进行知识蒸馏。2) 边缘推理:将边缘模型部署到用户设备上进行推理。3) 反向蒸馏:从边缘模型中提取用户特定知识。4) 云端模型更新:利用提取的知识更新云端模型。5) 边缘模型更新:将更新后的云端模型知识蒸馏到边缘模型。
关键创新:DiReDi框架的关键创新在于反向蒸馏(RD)过程,它能够在不直接访问用户数据的情况下,提取边缘模型中蕴含的用户特定知识。与传统的联邦学习方法相比,DiReDi框架无需在边缘设备上进行模型训练,降低了计算资源需求,并进一步提升了隐私保护水平。
关键设计:反向蒸馏的具体实现方式未知,论文中未详细描述。可能涉及设计特定的损失函数,以鼓励边缘模型学习用户数据中的独特模式,并将这些模式编码到可传递的知识表示中。云端模型更新的具体策略也未知,可能采用增量学习或元学习等方法,以有效地融合从边缘模型提取的知识。
🖼️ 关键图片

📊 实验亮点
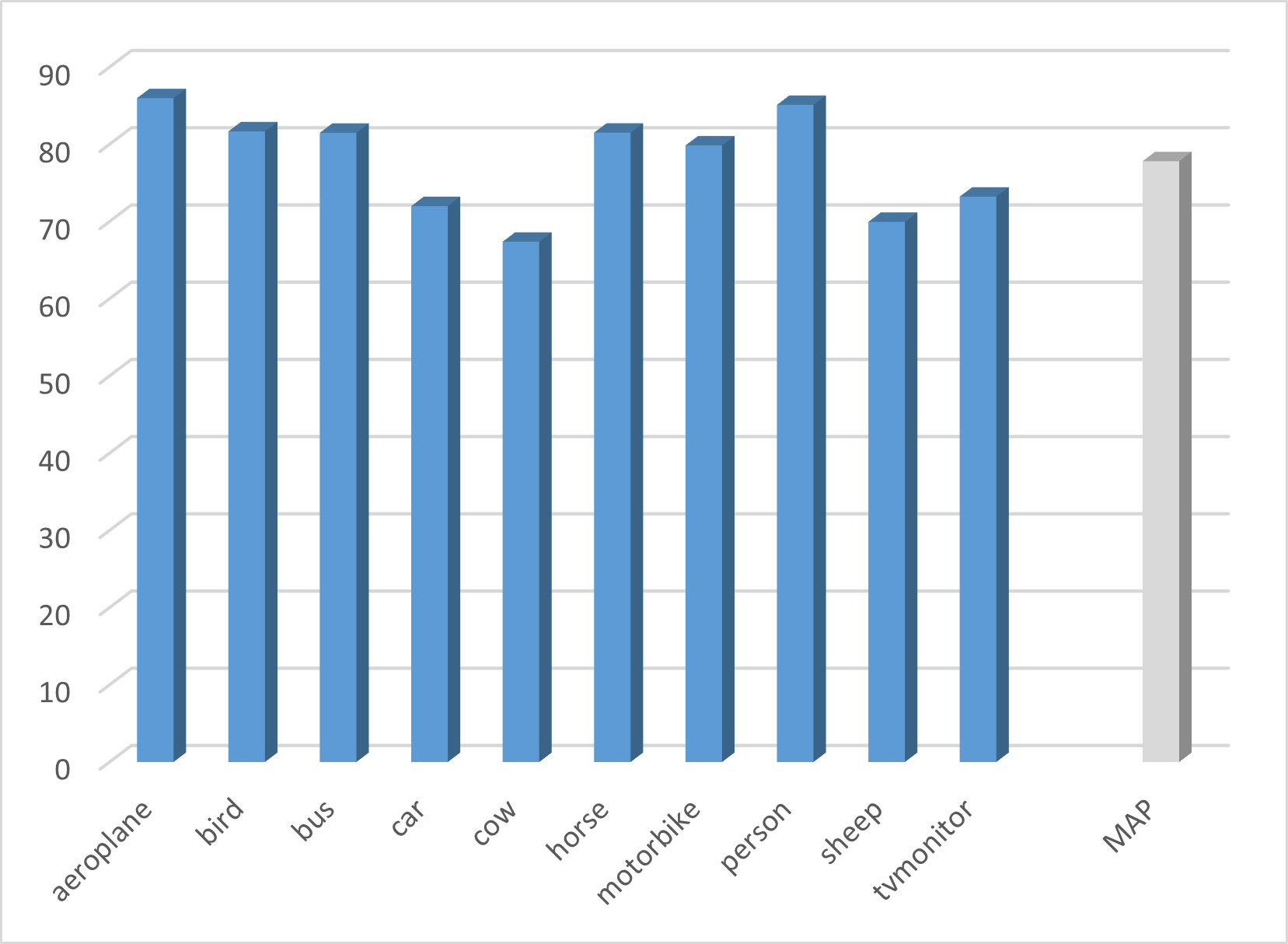
论文通过仿真实验验证了DiReDi框架的有效性。具体性能数据未知,但结果表明该框架能够在保护用户隐私的前提下,利用用户私有数据学习新知识,更新用户模型,并减少了初始冗余知识。与没有反向蒸馏的基线方法相比,DiReDi框架能够更好地适应用户特定场景。
🎯 应用场景
DiReDi框架可应用于各种AIoT场景,例如智能家居、智能制造、智慧医疗等。它能够使边缘设备在保护用户隐私的前提下,不断适应新的应用场景和用户需求,提升用户体验,并降低维护成本。该框架还有助于解决数据孤岛问题,促进AI技术的普及和应用。
📄 摘要(原文)
Typically, the significant efficiency can be achieved by deploying different edge AI models in various real world scenarios while a few large models manage those edge AI models remotely from cloud servers. However, customizing edge AI models for each user's specific application or extending current models to new application scenarios remains a challenge. Inappropriate local training or fine tuning of edge AI models by users can lead to model malfunction, potentially resulting in legal issues for the manufacturer. To address aforementioned issues, this paper proposes an innovative framework called "DiReD", which involves knowledge DIstillation & REverse DIstillation. In the initial step, an edge AI model is trained with presumed data and a KD process using the cloud AI model in the upper management cloud server. This edge AI model is then dispatched to edge AI devices solely for inference in the user's application scenario. When the user needs to update the edge AI model to better fit the actual scenario, the reverse distillation (RD) process is employed to extract the knowledge: the difference between user preferences and the manufacturer's presumptions from the edge AI model using the user's exclusive data. Only the extracted knowledge is reported back to the upper management cloud server to update the cloud AI model, thus protecting user privacy by not using any exclusive data. The updated cloud AI can then update the edge AI model with the extended knowledge. Simulation results demonstrate that the proposed "DiReDi" framework allows the manufacturer to update the user model by learning new knowledge from the user's actual scenario with private data. The initial redundant knowledge is reduced since the retraining emphasizes user private data.