Self-Supervised Learning of Iterative Solvers for Constrained Optimization
作者: Lukas Lüken, Sergio Lucia
分类: cs.LG, math.OC
发布日期: 2024-09-12 (更新: 2025-11-14)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出自监督学习的迭代求解器,加速约束优化问题的实时求解。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 自监督学习 约束优化 迭代求解器 模型预测控制 神经网络 KKT条件 实时优化
📋 核心要点
- 现有参数优化方法难以在满足实时约束的同时保证高精度,尤其是在模型预测控制等领域。
- 论文提出一种基于自监督学习的迭代求解器,通过神经网络预测初始解,并使用学习到的迭代求解器进行优化。
- 实验结果表明,该方法在非凸问题上比传统求解器快一个数量级,精度比其他学习方法高几个数量级。
📝 摘要(中文)
本文提出了一种基于学习的约束优化迭代求解器,旨在实时解决参数优化问题,满足模型预测控制等应用对高精度和实时性的需求。该求解器包含一个神经网络预测器,用于生成初始原始-对偶解估计,以及一个学习到的迭代求解器,用于细化这些估计以达到高精度。我们引入了一种基于Karush-Kuhn-Tucker (KKT) 最优性条件的新型损失函数,实现了完全自监督训练,无需预先采样的优化器解。理论保证确保训练损失函数仅在KKT点达到最小值。凸化过程使得该方法能够应用于非凸问题,同时保持这些保证。在两个非凸案例研究上的实验表明,与IPOPT等最先进的求解器相比,速度提高了高达一个数量级,同时比同类基于学习的方法实现了高几个数量级的精度。
🔬 方法详解
问题定义:论文旨在解决参数约束优化问题,特别是在需要实时性和高精度的场景下,例如模型预测控制。传统的优化求解器,如IPOPT,可能无法在严格的实时约束下提供足够的性能。而现有的基于学习的方法,虽然速度快,但精度往往不足。
核心思路:论文的核心思路是利用神经网络学习一个迭代求解器,该求解器能够快速且精确地找到约束优化问题的解。通过结合神经网络的快速预测能力和迭代求解器的精确优化能力,实现实时性和高精度的平衡。自监督学习的引入避免了对大量预采样数据的依赖。
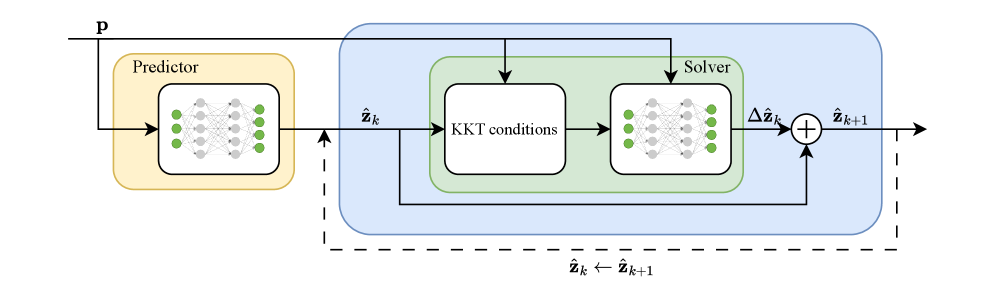
技术框架:整体框架包含两个主要模块:1) 神经网络预测器:用于生成初始的原始-对偶解估计。该预测器接收优化问题的参数作为输入,并输出初始解的估计值。2) 学习到的迭代求解器:用于细化初始解估计,通过迭代的方式逐步逼近最优解。该求解器基于神经网络,并使用自监督学习进行训练。
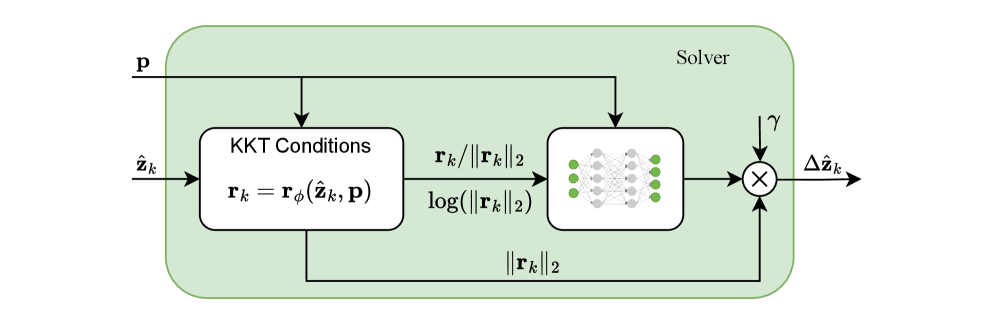
关键创新:最重要的创新点在于提出了基于KKT最优性条件的自监督学习损失函数。该损失函数使得网络可以在没有预采样最优解的情况下进行训练,并且保证了训练过程收敛到KKT点。此外,论文还提出了一种凸化过程,使得该方法可以应用于非凸问题,同时保持理论保证。
关键设计:损失函数的设计是关键。论文使用KKT条件作为损失函数,直接优化解的质量,而非依赖于预先计算好的最优解。具体来说,损失函数包括KKT条件的残差项,例如互补松弛条件、梯度条件等。此外,网络结构的选择也至关重要,需要能够有效地学习优化问题的结构和迭代求解的过程。凸化过程的具体实现方式未知,但其目的是将非凸问题转化为一系列凸子问题进行求解。
🖼️ 关键图片
📊 实验亮点
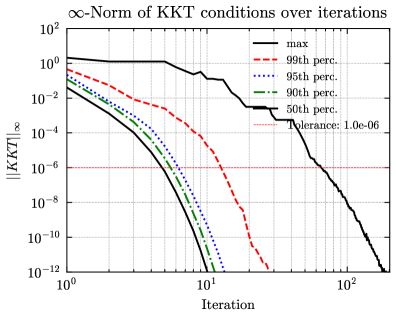
实验结果表明,该方法在两个非凸案例研究中,与最先进的求解器IPOPT相比,速度提高了高达一个数量级,同时比同类基于学习的方法实现了高几个数量级的精度。这表明该方法在实时性和精度方面都具有显著优势。
🎯 应用场景
该研究成果可广泛应用于需要实时约束优化的领域,如模型预测控制、机器人运动规划、资源分配、电力系统优化等。通过加速优化求解过程,可以提高系统的响应速度和控制性能,并降低计算成本。未来,该方法有望应用于更复杂的非线性、非凸优化问题,推动相关领域的发展。
📄 摘要(原文)
The real-time solution of parametric optimization problems is critical for applications that demand high accuracy under tight real-time constraints, such as model predictive control. To this end, this work presents a learning-based iterative solver for constrained optimization, comprising a neural network predictor that generates initial primal-dual solution estimates, followed by a learned iterative solver that refines these estimates to reach high accuracy. We introduce a novel loss function based on Karush-Kuhn-Tucker (KKT) optimality conditions, enabling fully self-supervised training without pre-sampled optimizer solutions. Theoretical guarantees ensure that the training loss function attains minima exclusively at KKT points. A convexification procedure enables application to nonconvex problems while preserving these guarantees. Experiments on two nonconvex case studies demonstrate speedups of up to one order of magnitude compared to state-of-the-art solvers such as IPOPT, while achieving orders of magnitude higher accuracy than competing learning-based approaches.