The Role of Deep Learning Regularizations on Actors in Offline RL
作者: Denis Tarasov, Anja Surina, Caglar Gulcehre
分类: cs.LG, cs.AI
发布日期: 2024-09-11 (更新: 2024-11-21)
备注: https://github.com/DT6A/ActoReg
💡 一句话要点
在离线强化学习中,对Actor网络应用深度学习正则化可显著提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Actor网络 正则化 泛化能力 深度学习
📋 核心要点
- 离线强化学习中Actor网络的泛化能力不足是性能瓶颈,现有方法对此关注较少。
- 该研究的核心思想是将深度学习中常用的正则化方法应用于离线强化学习的Actor网络。
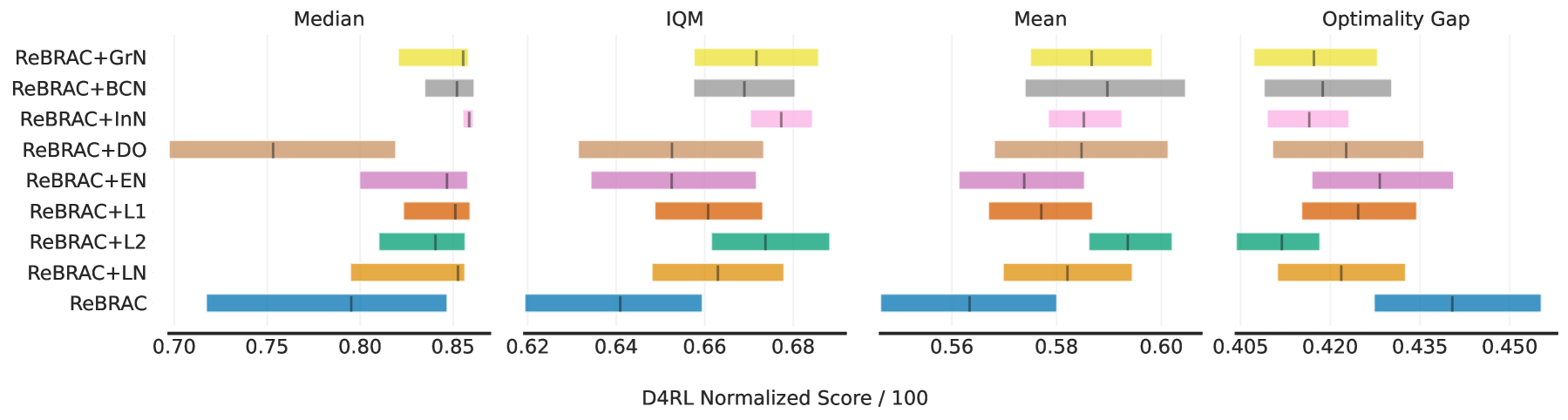
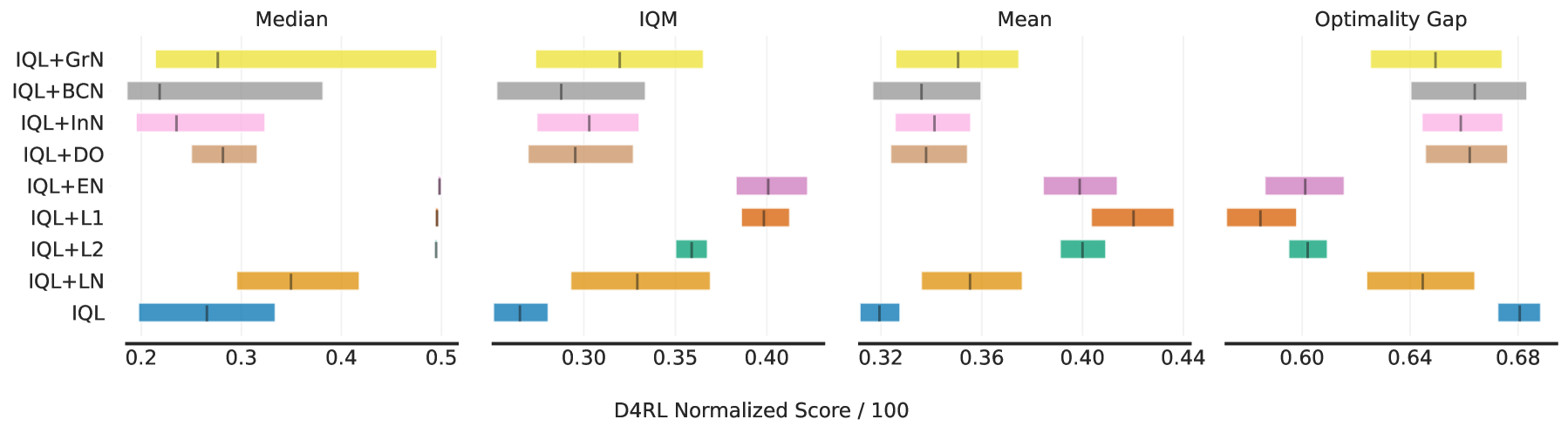
- 实验结果表明,在D4RL数据集上,对Actor网络进行正则化处理后,性能平均提升了6%。
📝 摘要(中文)
深度学习正则化技术,如dropout、层归一化或权重衰减,被广泛应用于构建现代人工神经网络,通常能带来更鲁棒的训练过程和更好的泛化能力。然而,在强化学习(RL)领域,这些技术的应用受到限制,通常只应用于价值函数估计器,并且可能产生不利影响。这个问题在离线强化学习(offline RL)环境中更为突出,因为离线强化学习与监督学习更相似,但受到的关注较少。最近在连续离线强化学习方面的工作表明,虽然我们可以构建足够强大的Critic网络,但Actor网络的泛化仍然是一个瓶颈。本研究通过实验表明,在离线强化学习Actor-Critic算法中,对Actor网络应用标准正则化技术,在两个算法和三个不同的连续D4RL领域中,平均可以提高6%的性能。
🔬 方法详解
问题定义:论文旨在解决离线强化学习中Actor网络泛化能力不足的问题。现有方法通常侧重于Critic网络的优化,而忽略了Actor网络的泛化能力,导致策略性能受限。此外,直接将在线强化学习的经验应用于离线强化学习可能导致性能下降,因为离线强化学习更类似于监督学习,需要更强的泛化能力。
核心思路:论文的核心思路是将深度学习中常用的正则化技术,如dropout、层归一化和权重衰减,应用于离线强化学习的Actor网络。作者认为,通过对Actor网络进行正则化,可以提高其泛化能力,从而改善离线强化学习的整体性能。这种思路借鉴了监督学习中的经验,即正则化可以有效防止过拟合,提高模型的泛化能力。
技术框架:该研究采用标准的离线强化学习Actor-Critic框架,并在此基础上对Actor网络进行正则化。具体而言,作者选择了两种常用的离线强化学习算法,并在三个不同的连续D4RL领域进行了实验。实验流程包括:(1) 使用离线数据集训练Actor和Critic网络;(2) 在训练Actor网络时,应用不同的正则化技术;(3) 评估Actor网络的性能。
关键创新:该研究的关键创新在于将深度学习中常用的正则化技术应用于离线强化学习的Actor网络,并证明了其有效性。与现有方法相比,该研究更加关注Actor网络的泛化能力,并提供了一种简单有效的提高Actor网络泛化能力的方法。
关键设计:论文中,作者使用了dropout、layer normalization和weight decay等正则化方法。具体参数设置可能因算法和数据集而异,但通常会通过交叉验证等方式进行选择。损失函数方面,Actor网络通常使用策略梯度相关的损失函数,而Critic网络则使用时序差分误差相关的损失函数。网络结构方面,Actor和Critic网络通常采用多层感知机或更复杂的神经网络结构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在两个离线强化学习算法和三个不同的连续D4RL领域中,对Actor网络应用标准正则化技术后,性能平均提高了6%。这一结果表明,正则化技术可以有效提高离线强化学习中Actor网络的泛化能力,从而改善整体性能。该提升在多个数据集和算法上均得到验证,证明了该方法的有效性和普适性。
🎯 应用场景
该研究成果可广泛应用于各种需要离线强化学习的场景,例如机器人控制、自动驾驶、推荐系统和金融交易等。通过提高Actor网络的泛化能力,可以使智能体在面对未见过的数据时也能做出合理的决策,从而提高系统的鲁棒性和可靠性。未来,该研究可以进一步扩展到更复杂的离线强化学习算法和环境,并探索更有效的正则化方法。
📄 摘要(原文)
Deep learning regularization techniques, such as dropout, layer normalization, or weight decay, are widely adopted in the construction of modern artificial neural networks, often resulting in more robust training processes and improved generalization capabilities. However, in the domain of Reinforcement Learning (RL), the application of these techniques has been limited, usually applied to value function estimators (Hiraoka et al., 2021; Smith et al., 2022), and may result in detrimental effects. This issue is even more pronounced in offline RL settings, which bear greater similarity to supervised learning but have received less attention. Recent work in continuous offline RL (Park et al., 2024) has demonstrated that while we can build sufficiently powerful critic networks, the generalization of actor networks remains a bottleneck. In this study, we empirically show that applying standard regularization techniques to actor networks in offline RL actor-critic algorithms yields improvements of 6% on average across two algorithms and three different continuous D4RL domains.