A Continual and Incremental Learning Approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption
作者: Marcus Rüb, Philipp Tuchel, Axel Sikora, Daniel Mueller-Gritschneder
分类: cs.LG, cs.AI
发布日期: 2024-09-11
期刊: 2024 IEEE 7th International Conference on Industrial Cyber-Physical Systems (ICPS)
DOI: 10.1109/ICPS59941.2024.10639989
💡 一句话要点
提出一种TinyML设备端持续增量学习算法,结合数据集蒸馏与模型自适应。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: TinyML 增量学习 持续学习 数据集蒸馏 模型自适应
📋 核心要点
- 现有TinyML增量学习方法难以兼顾资源限制和灾难性遗忘问题,模型大小固定导致效率低下。
- 该方法通过知识蒸馏创建小型数据集,并动态调整模型大小,以适应资源受限环境下的增量学习需求。
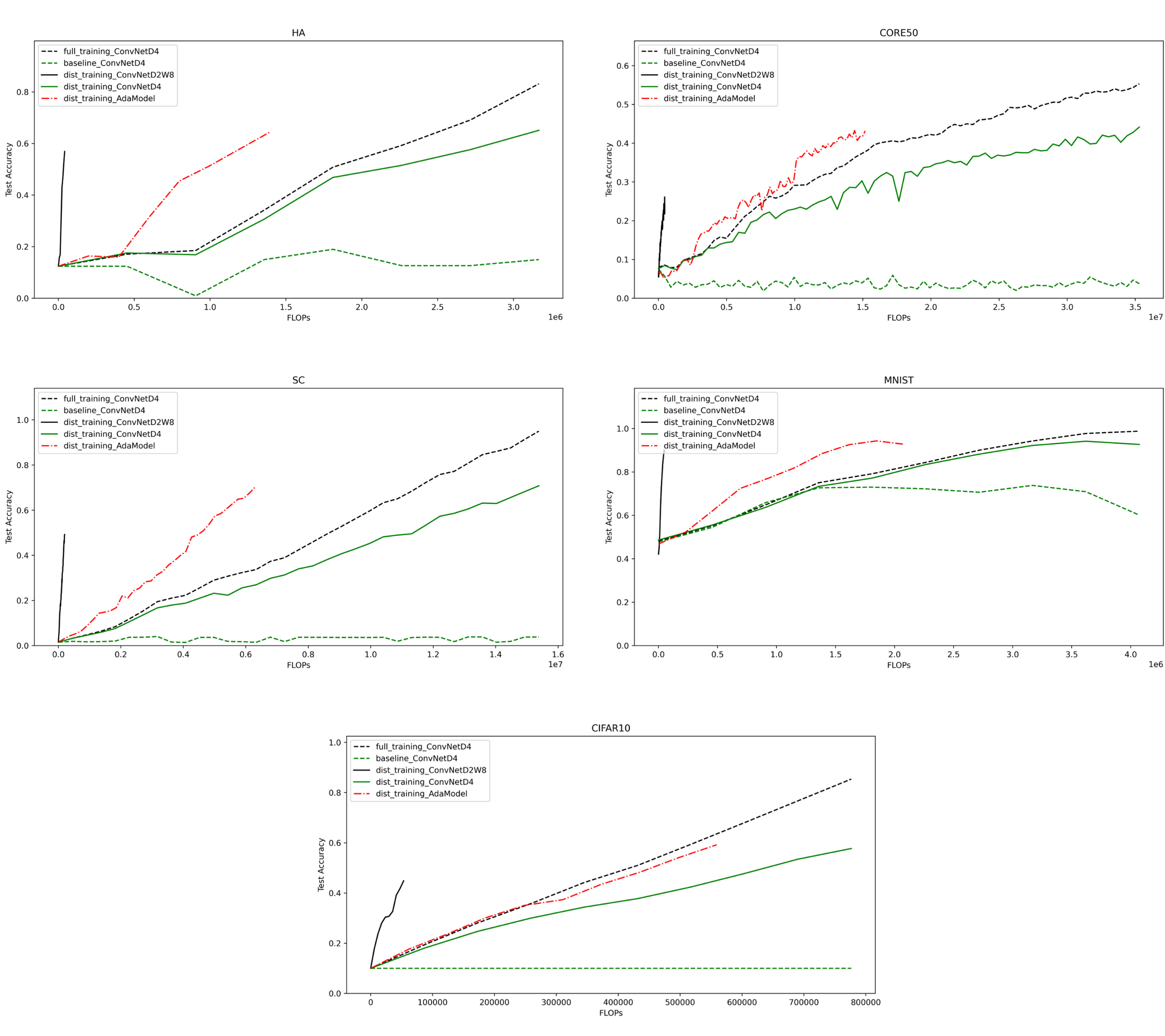
- 实验表明,该算法在精度损失仅1%的情况下,FLOPs降低了57%,且仅需原始数据集1%的内存。
📝 摘要(中文)
本文提出了一种针对TinyML中增量学习的新算法,该算法针对低性能和高能效的嵌入式设备进行了优化。TinyML是一个新兴领域,它将机器学习模型部署在微控制器等资源受限的设备上,从而在传统机器学习模型不可行的环境中实现语音识别、异常检测、预测性维护和传感器数据处理等智能应用。该算法通过使用知识蒸馏来创建一个小的、蒸馏的数据集,从而解决灾难性遗忘的挑战。该方法的新颖之处在于,可以动态调整模型的大小,从而使模型的复杂性能够适应任务的需求。这为资源受限环境中的增量学习提供了一种解决方案,在这些环境中,模型大小和计算效率都是关键因素。结果表明,所提出的算法为嵌入式设备上的TinyML增量学习提供了一种有希望的方法。该算法在包括CIFAR10、MNIST、CORE50、HAR、Speech Commands在内的五个数据集上进行了测试。研究结果表明,尽管与更大的固定模型相比,该算法仅使用了43%的浮点运算(FLOPs),但其精度损失可忽略不计,仅为1%。此外,所提出的方法具有内存效率。虽然最先进的增量学习通常非常消耗内存,但该方法仅需要原始数据集的1%。
🔬 方法详解
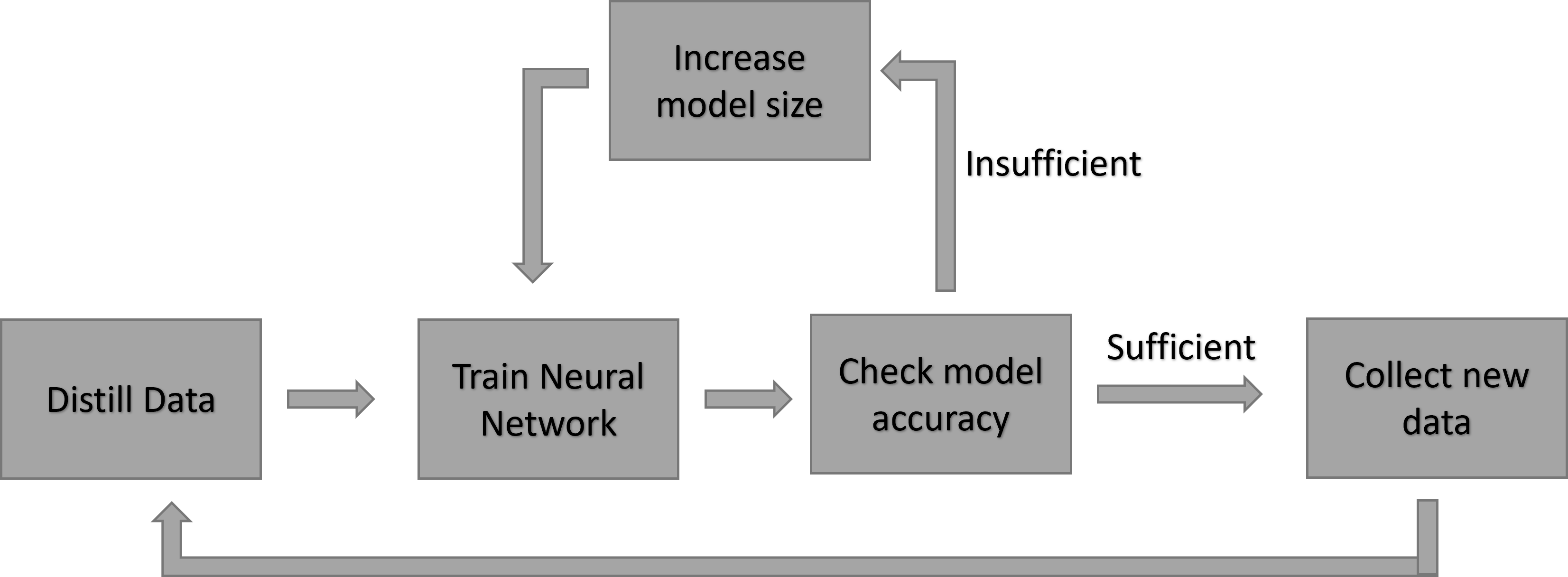
问题定义:论文旨在解决TinyML设备上进行持续增量学习时,如何在资源极度受限的条件下,克服灾难性遗忘问题,并保持较高的学习效率和模型精度。现有方法通常采用固定大小的模型,这在计算资源有限的嵌入式设备上效率低下,并且容易发生灾难性遗忘,即在学习新任务时忘记旧任务的知识。
核心思路:论文的核心思路是结合数据集蒸馏和模型大小自适应。首先,利用知识蒸馏技术,将先前学习到的知识压缩到一个小型、具有代表性的蒸馏数据集中,从而减少存储和计算负担。其次,根据新任务的复杂程度,动态调整模型的大小,避免过度参数化,提高计算效率。
技术框架:该方法包含两个主要阶段:数据集蒸馏阶段和模型训练阶段。在数据集蒸馏阶段,使用先前训练好的模型作为教师模型,生成一个小型蒸馏数据集。在模型训练阶段,首先根据新任务的复杂程度调整模型大小,然后使用蒸馏数据集和新任务的数据集对模型进行训练。训练过程中,采用知识蒸馏损失函数,以保留先前学习到的知识。
关键创新:该方法最重要的创新点在于模型大小的动态自适应。传统的增量学习方法通常采用固定大小的模型,这在资源受限的TinyML环境中效率低下。通过动态调整模型大小,可以根据任务的复杂程度选择合适的模型,从而在保证精度的前提下,最大限度地提高计算效率。
关键设计:在数据集蒸馏阶段,采用对抗生成网络(GAN)生成蒸馏数据集。在模型训练阶段,使用交叉熵损失函数和知识蒸馏损失函数的加权和作为总损失函数。模型大小的调整策略基于新任务数据集的复杂度,复杂度通过计算数据集的内在维度来估计。具体的网络结构选择和超参数设置根据不同的数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该算法在五个数据集上均取得了良好的效果。在CIFAR10数据集上,与固定大小的模型相比,该算法在精度损失仅为1%的情况下,FLOPs降低了57%。此外,该算法仅需原始数据集1%的内存,显著降低了存储需求。这些结果表明,该算法为TinyML设备上的增量学习提供了一种高效且实用的解决方案。
🎯 应用场景
该研究成果可广泛应用于各种TinyML应用场景,例如智能传感器、可穿戴设备、物联网设备等。通过在设备端进行持续增量学习,可以使这些设备能够不断适应新的环境和任务,提高其智能化水平和应用价值。例如,在智能家居中,设备可以不断学习用户的习惯,提供更加个性化的服务;在工业领域,设备可以实时监测设备状态,预测故障,提高生产效率。
📄 摘要(原文)
A new algorithm for incremental learning in the context of Tiny Machine learning (TinyML) is presented, which is optimized for low-performance and energy efficient embedded devices. TinyML is an emerging field that deploys machine learning models on resource-constrained devices such as microcontrollers, enabling intelligent applications like voice recognition, anomaly detection, predictive maintenance, and sensor data processing in environments where traditional machine learning models are not feasible. The algorithm solve the challenge of catastrophic forgetting through the use of knowledge distillation to create a small, distilled dataset. The novelty of the method is that the size of the model can be adjusted dynamically, so that the complexity of the model can be adapted to the requirements of the task. This offers a solution for incremental learning in resource-constrained environments, where both model size and computational efficiency are critical factors. Results show that the proposed algorithm offers a promising approach for TinyML incremental learning on embedded devices. The algorithm was tested on five datasets including: CIFAR10, MNIST, CORE50, HAR, Speech Commands. The findings indicated that, despite using only 43% of Floating Point Operations (FLOPs) compared to a larger fixed model, the algorithm experienced a negligible accuracy loss of just 1%. In addition, the presented method is memory efficient. While state-of-the-art incremental learning is usually very memory intensive, the method requires only 1% of the original data set.