Privacy Bias in Language Models: A Contextual Integrity-based Auditing Metric
作者: Yan Shvartzshnaider, Vasisht Duddu
分类: cs.LG, cs.AI, cs.CR, cs.CY
发布日期: 2024-09-05 (更新: 2025-12-19)
备注: Privacy Enhancing Technologies Symposium (PETS), 2026
💡 一句话要点
提出基于上下文完整性的度量方法,用于评估语言模型中的隐私偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐私偏见 语言模型 上下文完整性 审计指标 信息流
📋 核心要点
- 现有方法难以评估大型语言模型中因提示变化而产生的隐私偏见。
- 论文提出基于上下文完整性的方法,量化信息流的适当性,以此评估隐私偏见。
- 研究考察了模型容量和优化对隐私偏见的影响,为模型训练和部署提供指导。
📝 摘要(中文)
随着大型语言模型(LLMs)被集成到社会技术系统中,检查它们所表现出的隐私偏见至关重要。我们将隐私偏见定义为LLMs响应中信息流的适当性值。隐私偏见与预期值之间的偏差,称为隐私偏见差值,可能表明存在隐私侵犯。作为一种审计指标,隐私偏见可以帮助(a)模型训练者评估LLMs的伦理和社会影响,(b)服务提供商选择适合上下文的LLMs,以及(c)政策制定者评估已部署LLMs中隐私偏见的适当性。我们提出并回答了一个新的研究问题:我们如何可靠地检查LLMs中的隐私偏见以及影响它们的因素?我们提出了一种新颖的方法,使用基于上下文完整性的方法来评估来自各种LLMs的响应,从而评估隐私偏见。我们的方法考虑了提示变化中响应的敏感性,这阻碍了隐私偏见的评估。最后,我们研究了隐私偏见如何受到模型容量和优化方法的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中存在的隐私偏见问题。现有方法在评估LLMs的隐私偏见时,难以有效处理因提示变化而导致的响应敏感性差异,缺乏一种可靠的、可量化的评估指标。这种不足使得模型训练者、服务提供商和政策制定者难以评估和控制LLMs的隐私风险。
核心思路:论文的核心思路是利用上下文完整性(Contextual Integrity)理论来评估LLMs的隐私偏见。上下文完整性关注信息流动的适当性,即信息在特定上下文中是否应该以某种方式流动。通过量化LLMs响应中信息流的适当性值,可以识别和评估隐私偏见。这种方法考虑了上下文因素,能够更准确地评估LLMs的隐私风险。
技术框架:论文提出的技术框架主要包含以下几个阶段:1) 定义信息流:确定LLMs响应中涉及的信息类型和流动方向。2) 评估上下文完整性:根据上下文完整性原则,评估信息流的适当性值。3) 计算隐私偏见差值:将实际信息流与预期信息流进行比较,计算隐私偏见差值,以此量化隐私偏见。4) 分析影响因素:研究模型容量和优化方法等因素对隐私偏见的影响。
关键创新:论文的关键创新在于将上下文完整性理论应用于LLMs的隐私偏见评估。这种方法提供了一种新的视角和工具,可以更全面、更准确地评估LLMs的隐私风险。此外,论文还提出了一种量化隐私偏见的方法,使得隐私风险的评估更加客观和可比。
关键设计:论文的关键设计包括:1) 基于上下文完整性的信息流评估方法,需要定义清晰的信息类型和流动方向,并根据上下文因素确定适当性值。2) 隐私偏见差值的计算方法,需要确定预期信息流,并将其与实际信息流进行比较。3) 实验设计,需要选择合适的LLMs和提示,并控制模型容量和优化方法等变量。
🖼️ 关键图片

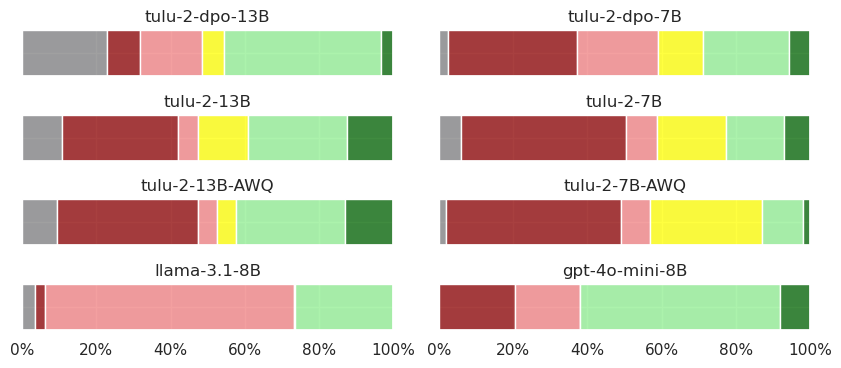
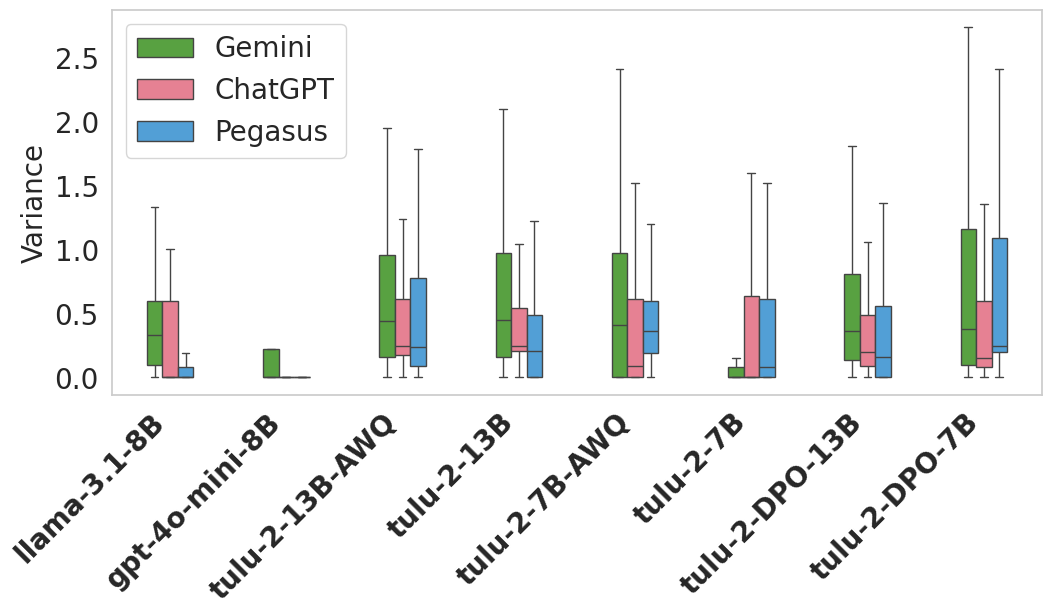
📊 实验亮点
论文提出了一种基于上下文完整性的隐私偏见评估方法,能够有效处理提示变化带来的影响。通过实验,研究者分析了模型容量和优化方法对隐私偏见的影响,为模型训练和部署提供了有价值的指导。具体性能数据未知,但该方法为量化和缓解LLM的隐私风险提供了新思路。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的隐私保护能力。模型训练者可以利用该方法评估模型的伦理和社会影响,服务提供商可以选择适合上下文的LLMs,政策制定者可以评估已部署LLMs的隐私风险。该研究有助于构建更安全、更可靠的AI系统。
📄 摘要(原文)
As large language models (LLMs) are integrated into sociotechnical systems, it is crucial to examine the privacy biases they exhibit. We define privacy bias as the appropriateness value of information flows in responses from LLMs. A deviation between privacy biases and expected values, referred to as privacy bias delta, may indicate privacy violations. As an auditing metric, privacy bias can help (a) model trainers evaluate the ethical and societal impact of LLMs, (b) service providers select context-appropriate LLMs, and (c) policymakers assess the appropriateness of privacy biases in deployed LLMs. We formulate and answer a novel research question: how can we reliably examine privacy biases in LLMs and the factors that influence them? We present a novel approach for assessing privacy biases using a contextual integrity-based methodology to evaluate the responses from various LLMs. Our approach accounts for the sensitivity of responses across prompt variations, which hinders the evaluation of privacy biases. Finally, we investigate how privacy biases are affected by model capacities and optimizations.