Reservoir Static Property Estimation Using Nearest-Neighbor Neural Network
作者: Yuhe Wang
分类: cs.LG, physics.data-an, stat.AP
发布日期: 2024-09-04 (更新: 2024-09-27)
备注: 6 pages, 3 figures; updated to tex source
💡 一句话要点
提出基于最近邻神经网络的油藏静态属性估计方法,提升空间插值精度。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 油藏建模 静态属性估计 最近邻算法 神经网络 空间插值 不确定性量化 地质统计 孔隙度预测
📋 核心要点
- 传统地质统计方法(如IDW和克里金法)难以捕捉油藏数据中复杂的非线性依赖关系,导致静态属性预测精度不足。
- 该方法结合最近邻算法和神经网络,利用神经网络强大的非线性拟合能力,并引入随机化来量化插值的不确定性。
- 通过整合空间邻近性和不确定性量化,该方法旨在提高孔隙度和渗透率等静态属性预测的准确性。
📝 摘要(中文)
本文提出了一种利用最近邻神经网络估计油藏建模中静态属性空间分布的方法。该方法利用神经网络在逼近复杂非线性函数方面的优势,特别是在涉及空间插值的任务中。它结合了最近邻算法来捕获数据点之间的局部空间关系,并引入了随机化来量化插值过程中固有的不确定性。该方法解决了传统地质统计方法(如反距离权重法(IDW)和克里金法)的局限性,这些方法通常无法模拟油藏数据中复杂的非线性依赖关系。通过整合空间邻近性和不确定性量化,所提出的方法可以提高静态属性预测的准确性,例如孔隙度和渗透率。
🔬 方法详解
问题定义:论文旨在解决油藏建模中静态属性(如孔隙度和渗透率)空间分布的精确估计问题。传统地质统计方法,如反距离权重法(IDW)和克里金法,在处理油藏数据中复杂的非线性关系时表现不足,导致预测精度受限。
核心思路:论文的核心思路是利用最近邻神经网络来逼近静态属性与空间位置之间的复杂非线性关系。通过结合最近邻算法,模型能够捕捉数据点之间的局部空间依赖性,从而更准确地进行空间插值。此外,引入随机化方法来量化插值过程中的不确定性,提供更可靠的预测结果。
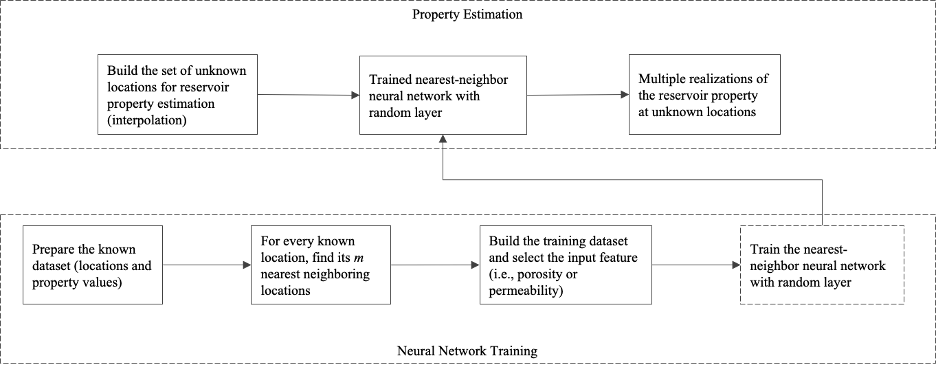
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:对油藏数据进行清洗和标准化,为神经网络的训练做准备。2) 最近邻搜索:对于每个需要预测的位置,利用最近邻算法找到其周围的若干个已知数据点。3) 神经网络训练:使用最近邻数据点的属性值作为输入,训练一个神经网络来预测目标位置的属性值。4) 不确定性量化:通过引入随机化方法(例如,多次随机初始化神经网络并进行预测),来估计预测结果的不确定性。
关键创新:该方法的关键创新在于将最近邻算法与神经网络相结合,充分利用了神经网络强大的非线性拟合能力和最近邻算法对局部空间关系的敏感性。与传统的单一地质统计方法相比,该方法能够更好地捕捉油藏数据中复杂的非线性依赖关系,并提供不确定性量化,从而提高预测的准确性和可靠性。
关键设计:论文中可能涉及的关键设计包括:1) 最近邻算法中邻居数量的选择:需要根据数据的空间分布特征进行调整。2) 神经网络的结构设计:可能采用多层感知机(MLP)或其他适合空间数据处理的网络结构。3) 损失函数的设计:可能采用均方误差(MSE)等常用的回归损失函数。4) 随机化方法的选择:例如,可以通过多次随机初始化神经网络的权重并进行预测,来估计预测结果的方差。
🖼️ 关键图片
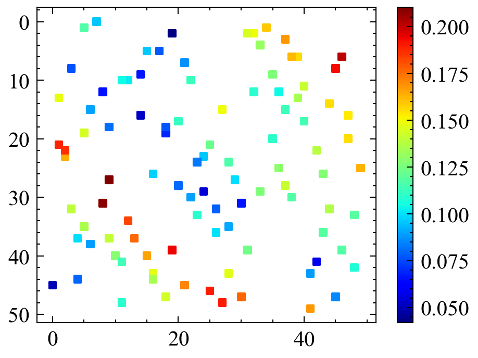
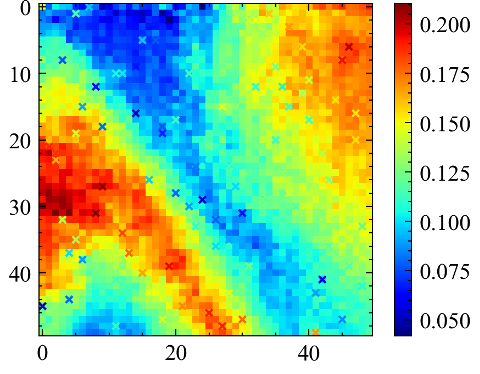
📊 实验亮点
摘要中未提供具体的实验结果和性能数据,因此无法总结实验亮点。但是,该方法旨在克服传统地质统计方法的局限性,并提高静态属性预测的准确性,因此可以推断,实验结果可能会显示该方法在预测精度方面优于IDW和克里金法。
🎯 应用场景
该研究成果可应用于油气勘探开发领域,提高油藏建模的精度和可靠性,辅助油藏工程师进行更准确的储量评估、生产预测和开发方案优化。更精确的静态属性估计有助于降低勘探开发风险,提高油气采收率,具有重要的经济价值和社会效益。
📄 摘要(原文)
This note presents an approach for estimating the spatial distribution of static properties in reservoir modeling using a nearest-neighbor neural network. The method leverages the strengths of neural networks in approximating complex, non-linear functions, particularly for tasks involving spatial interpolation. It incorporates a nearest-neighbor algorithm to capture local spatial relationships between data points and introduces randomization to quantify the uncertainty inherent in the interpolation process. This approach addresses the limitations of traditional geostatistical methods, such as Inverse Distance Weighting (IDW) and Kriging, which often fail to model the complex non-linear dependencies in reservoir data. By integrating spatial proximity and uncertainty quantification, the proposed method can improve the accuracy of static property predictions like porosity and permeability.