An Introduction to Centralized Training for Decentralized Execution in Cooperative Multi-Agent Reinforcement Learning
作者: Christopher Amato
分类: cs.LG, cs.MA
发布日期: 2024-09-04
备注: arXiv admin note: substantial text overlap with arXiv:2405.06161
💡 一句话要点
介绍合作多智能体强化学习中集中训练分散执行方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 集中训练分散执行 合作博弈 强化学习 智能体协作
📋 核心要点
- 多智能体强化学习面临如何在训练时利用全局信息,同时保证智能体在实际环境中独立决策的问题。
- 集中训练分散执行(CTDE)方法通过在训练阶段使用集中式信息,在执行阶段仅依赖局部观测,实现了二者的平衡。
- CTDE方法在合作场景中应用广泛,能够提升智能体的协作能力,并且避免了执行过程中的通信需求。
📝 摘要(中文)
近年来,多智能体强化学习(MARL)的研究呈现爆炸式增长。现有的方法可以分为三大类:集中训练和执行(CTE)、集中训练分散执行(CTDE)以及分散训练和执行(DTE)。CTDE方法是最常见的,因为它们可以在训练期间利用集中式信息,但在执行期间以分散式方式进行——仅使用执行期间智能体可用的信息。CTDE是唯一需要单独训练阶段的范例,在该阶段可以使用任何可用的信息(例如,其他智能体策略、底层状态)。因此,它们比CTE方法更具可扩展性,不需要执行期间的通信,并且通常表现良好。CTDE最自然地适用于合作场景,但根据假设观察到的信息,也可能应用于竞争或混合场景。本文是对合作MARL中CTDE的介绍,旨在解释该设置、基本概念和常用方法。由于该子领域非常广泛,因此本文并未涵盖CTDE MARL中的所有工作。我收录了我认为对于理解该子领域中的主要概念很重要的工作,并向我省略的那些工作表示歉意。
🔬 方法详解
问题定义:论文主要关注合作多智能体强化学习中的集中训练分散执行(CTDE)问题。现有方法在多智能体协作中,要么依赖集中式执行,可扩展性差;要么完全分散式训练,难以学习有效的协作策略。CTDE旨在解决如何在训练时利用全局信息,同时保证智能体在实际执行时仅依赖局部观测,从而实现高效的协作。
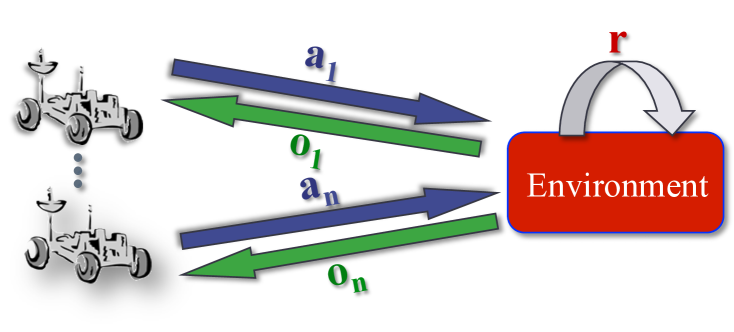
核心思路:CTDE的核心思路是在训练阶段,允许智能体访问全局状态信息和其他智能体的策略,以便学习更有效的协作策略。而在执行阶段,每个智能体只能根据自己的局部观测做出决策,无需与其他智能体通信。这种方式既能利用全局信息进行训练,又能保证智能体在实际环境中的独立性。
技术框架:CTDE的整体框架包含两个阶段:训练阶段和执行阶段。在训练阶段,通常使用集中式的评论家(Critic)来评估联合动作的价值,并指导每个智能体的策略更新。每个智能体根据全局状态信息和其他智能体的策略,学习自己的策略。在执行阶段,每个智能体根据自己的局部观测,独立地执行策略,无需与其他智能体通信。
关键创新:CTDE最重要的创新在于将训练和执行分离,允许在训练阶段利用全局信息,从而学习更有效的协作策略。与完全分散式训练相比,CTDE能够更好地利用全局信息,学习更优的策略;与集中式执行相比,CTDE具有更好的可扩展性和鲁棒性。
关键设计:CTDE的关键设计包括集中式评论家的设计、智能体策略的学习算法以及局部观测的设计。集中式评论家通常使用全局状态信息和所有智能体的动作作为输入,输出联合动作的价值。智能体策略的学习算法可以使用各种强化学习算法,如Q-learning、Actor-Critic等。局部观测的设计需要考虑智能体能够获取的信息,以及如何利用这些信息做出决策。
🖼️ 关键图片


📊 实验亮点
由于该论文为综述性质,因此没有具体的实验结果。但CTDE方法在许多合作多智能体强化学习任务中都取得了显著的成果。例如,在星际争霸II(StarCraft II)等复杂游戏中,基于CTDE的方法能够训练出超越人类玩家水平的智能体。在机器人协同任务中,CTDE方法也能够实现多个机器人高效协作,完成复杂的任务。
🎯 应用场景
CTDE方法在机器人协同、自动驾驶、交通调度、资源分配等领域具有广泛的应用前景。通过CTDE,可以训练出能够在复杂环境中高效协作的智能体,解决实际问题,例如多机器人协同完成复杂任务,自动驾驶车辆在交通拥堵情况下进行协同避让,以及在分布式系统中进行资源优化分配等。
📄 摘要(原文)
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. Many approaches have been developed but they can be divided into three main types: centralized training and execution (CTE), centralized training for decentralized execution (CTDE), and Decentralized training and execution (DTE). CTDE methods are the most common as they can use centralized information during training but execute in a decentralized manner -- using only information available to that agent during execution. CTDE is the only paradigm that requires a separate training phase where any available information (e.g., other agent policies, underlying states) can be used. As a result, they can be more scalable than CTE methods, do not require communication during execution, and can often perform well. CTDE fits most naturally with the cooperative case, but can be potentially applied in competitive or mixed settings depending on what information is assumed to be observed. This text is an introduction to CTDE in cooperative MARL. It is meant to explain the setting, basic concepts, and common methods. It does not cover all work in CTDE MARL as the subarea is quite extensive. I have included work that I believe is important for understanding the main concepts in the subarea and apologize to those that I have omitted.