Hallucination Detection in LLMs: Fast and Memory-Efficient Fine-Tuned Models
作者: Gabriel Y. Arteaga, Thomas B. Schön, Nicolas Pielawski
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-09-04 (更新: 2024-12-06)
备注: 6 pages, 3 figures
💡 一句话要点
提出快速且内存高效的微调模型,用于检测大型语言模型中的幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 集成学习 微调 不确定性估计
📋 核心要点
- 大型语言模型在高风险场景中应用受限,主要原因是其幻觉问题难以有效检测和控制。
- 提出一种快速且内存友好的LLM集成训练方法,旨在降低训练和推理成本,使其更易于部署。
- 实验表明,该方法训练的集成模型能够有效检测LLM的幻觉,且仅需单GPU即可完成训练和推理。
📝 摘要(中文)
在自动驾驶汽车、医疗或保险等高风险环境中部署人工智能时,不确定性估计是必不可少的组成部分。近年来,大型语言模型(LLM)的使用激增,但它们容易产生幻觉,这可能在高风险环境中造成严重危害。尽管LLM取得了成功,但它们的训练和运行成本很高:需要大量的计算和内存,这在实践中阻碍了集成方法的应用。在这项工作中,我们提出了一种新颖的方法,该方法可以快速且内存友好地训练LLM集成。我们表明,由此产生的集成可以检测幻觉,并且在实践中是一种可行的方法,因为只需要一个GPU进行训练和推理。
🔬 方法详解
问题定义:大型语言模型(LLM)虽然强大,但在高风险应用中,其“幻觉”问题(即生成不真实或无意义的内容)是一个主要障碍。现有的LLM训练和部署成本高昂,特别是集成方法,需要大量的计算资源和内存,这使得它们在资源受限的环境中难以应用。因此,如何高效地检测和减轻LLM的幻觉,同时降低计算成本,是一个亟待解决的问题。
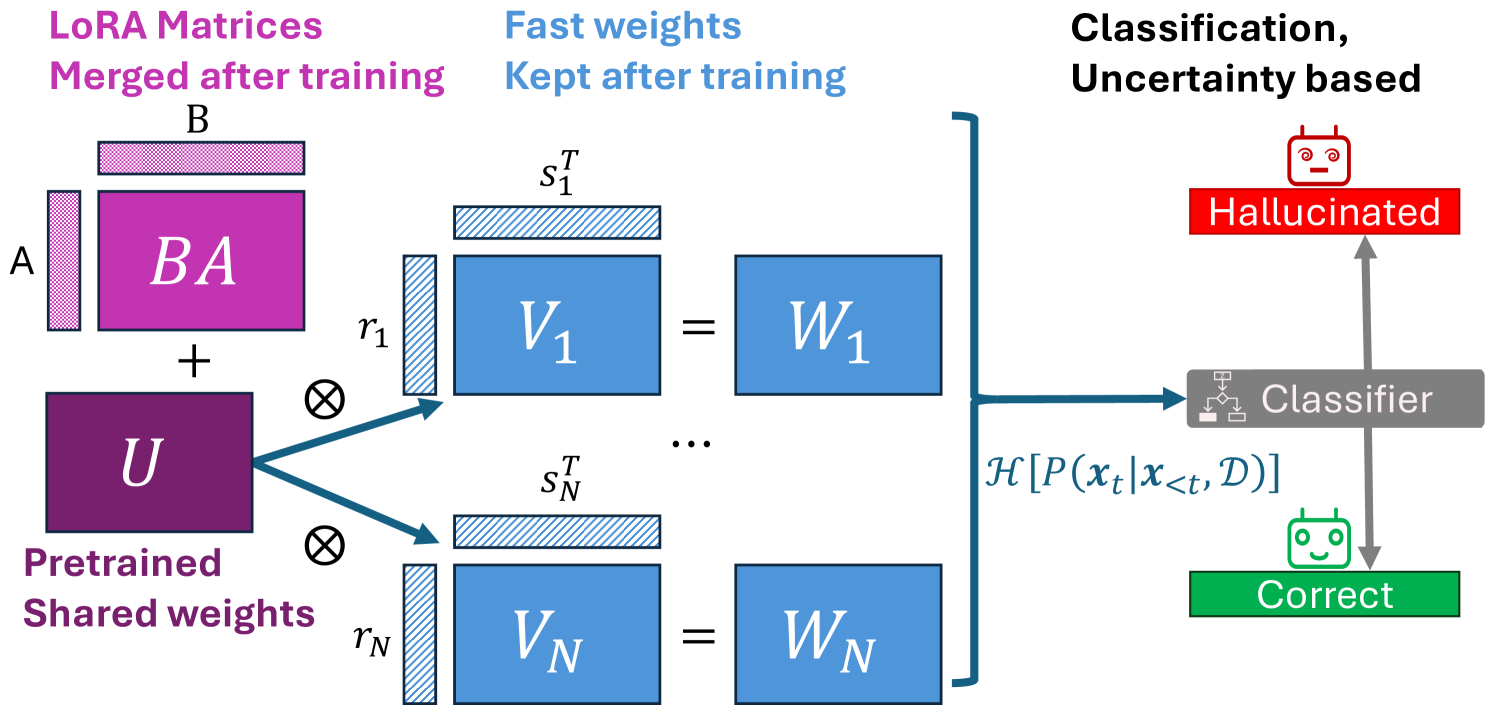
核心思路:该论文的核心思路是设计一种快速且内存高效的LLM集成训练方法,使得可以在有限的计算资源下训练多个模型,并通过集成的方式来提高幻觉检测的准确性。通过集成多个模型的预测结果,可以减少单个模型产生的幻觉带来的影响,从而提高整体的可靠性。
技术框架:论文提出的方法主要包含以下几个阶段:1) 选择预训练的LLM作为基础模型;2) 使用少量数据对基础模型进行微调,生成多个不同的模型变体;3) 将这些模型变体集成起来,形成一个集成模型;4) 使用集成模型对LLM的输出进行评估,判断是否存在幻觉。具体的集成方式可能包括投票、平均或更复杂的加权方法。
关键创新:该论文的关键创新在于提出了一种快速且内存高效的LLM集成训练方法。这种方法允许在有限的计算资源下训练多个模型,并通过集成的方式来提高幻觉检测的准确性。与传统的集成方法相比,该方法降低了训练和推理的成本,使其更易于部署。
关键设计:具体的参数设置、损失函数和网络结构等技术细节在摘要中没有明确说明,属于未知信息。但是,可以推测,微调过程可能采用了特定的正则化技术或数据增强方法,以提高模型的泛化能力和鲁棒性。此外,集成方式的选择和权重分配也可能是影响性能的关键因素。
🖼️ 关键图片

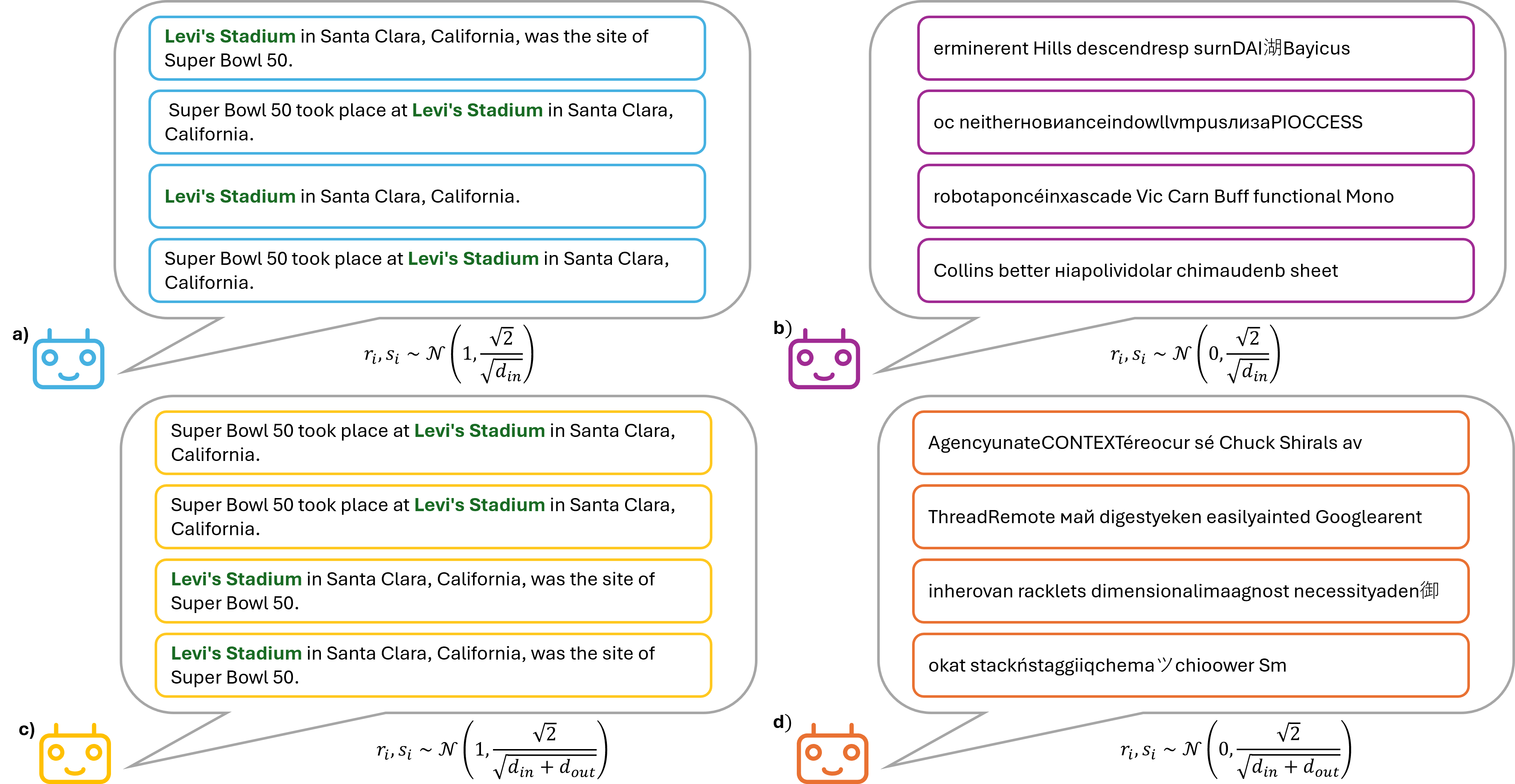
📊 实验亮点
论文的主要亮点在于提出了一种仅需单GPU即可完成训练和推理的LLM集成方法,用于检测幻觉。虽然摘要中没有给出具体的性能数据和对比基线,但强调了该方法在降低计算成本方面的优势,使其在资源受限的环境中更具可行性。具体的性能提升幅度属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的LLM应用场景,例如自动驾驶、医疗诊断、金融风控等。通过提高LLM的可靠性,可以降低因幻觉导致的风险,并促进LLM在更多领域的应用。未来,该方法可以进一步扩展到其他类型的AI模型,提高整体的安全性。
📄 摘要(原文)
Uncertainty estimation is a necessary component when implementing AI in high-risk settings, such as autonomous cars, medicine, or insurances. Large Language Models (LLMs) have seen a surge in popularity in recent years, but they are subject to hallucinations, which may cause serious harm in high-risk settings. Despite their success, LLMs are expensive to train and run: they need a large amount of computations and memory, preventing the use of ensembling methods in practice. In this work, we present a novel method that allows for fast and memory-friendly training of LLM ensembles. We show that the resulting ensembles can detect hallucinations and are a viable approach in practice as only one GPU is needed for training and inference.