Do We Trust What They Say or What They Do? A Multimodal User Embedding Provides Personalized Explanations
作者: Zhicheng Ren, Zhiping Xiao, Yizhou Sun
分类: cs.SI, cs.IR, cs.LG
发布日期: 2024-09-04
💡 一句话要点
提出贡献感知多模态用户嵌入(CAMUE)框架,实现社交网络中个性化可解释的预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态用户嵌入 社交网络分析 图神经网络 可解释性 个性化推荐
📋 核心要点
- 现有方法未能充分解释文本和图结构信息对用户预测的贡献差异,限制了个性化分析和不可信信息过滤。
- 提出贡献感知多模态用户嵌入(CAMUE)框架,通过学习不同模态的贡献权重,实现个性化可解释的预测。
- 实验结果表明,CAMUE能够提供个性化的可解释预测,并自动减轻不可靠信息的影响,案例研究验证了结果的合理性。
📝 摘要(中文)
随着社交媒体的快速发展,分析社交网络用户数据的重要性日益凸显。社交媒体中的用户表示学习是一个关键的研究领域,它为个性化内容推荐和恶意行为检测奠定了基础。社交网络用户数据具有固有的多模态特性,因此涌现了各种多模态方法,利用文本(即帖子内容)和关系(即用户间互动)信息来学习更高质量的用户嵌入。图神经网络模型的出现使得用户文本嵌入和用户互动图在社交网络中能够进行更端到端的集成。然而,大多数方法未能充分阐明数据的哪些方面(文本或图结构信息)对于预测特定任务下的每个特定用户更有帮助,这给个性化的下游分析和不可信信息过滤带来了一些负担。我们提出了一个简单而有效的框架,称为贡献感知多模态用户嵌入(CAMUE),用于社交网络。经验证据表明,我们的方法可以提供个性化的可解释预测,自动减轻不可靠信息的影响。我们还进行了案例研究,以展示我们结果的合理性。我们观察到,对于大多数用户来说,图结构信息比文本信息更值得信赖,但也有一些合理的案例表明文本更有帮助。我们的工作为更具可解释性、可靠性和有效性的社交媒体用户嵌入铺平了道路,从而可以实现更好的个性化内容传递。
🔬 方法详解
问题定义:现有社交网络用户嵌入方法通常忽略了不同模态(文本和图结构)对于不同用户预测的重要性差异。这导致模型的可解释性较差,难以判断哪些信息来源更可靠,从而影响了个性化推荐和恶意用户识别等下游任务的性能。现有方法无法针对特定用户,给出文本和图结构分别贡献多少的解释,缺乏个性化和可解释性。
核心思路:CAMUE的核心思路是学习每个用户在不同模态上的贡献权重。模型会根据用户的特点,自动判断文本信息和图结构信息哪个更可靠、更有价值。通过这种方式,模型可以更加关注对用户预测有帮助的信息,同时提供个性化的解释,说明为什么模型会做出这样的预测。
技术框架:CAMUE框架主要包含以下几个模块:1) 文本嵌入模块:使用预训练的语言模型(如BERT)将用户发布的文本内容转换为文本嵌入向量。2) 图嵌入模块:使用图神经网络(GNN)学习用户在社交网络中的图结构嵌入向量。3) 贡献感知融合模块:该模块是CAMUE的核心,它学习每个用户在文本和图结构模态上的贡献权重,并将两种模态的嵌入向量进行加权融合。4) 预测模块:使用融合后的用户嵌入向量进行下游任务的预测,例如用户分类或链接预测。
关键创新:CAMUE最重要的创新点在于贡献感知融合模块。该模块能够自动学习每个用户在不同模态上的贡献权重,从而实现个性化的可解释预测。与现有方法相比,CAMUE不仅能够提高预测性能,还能够提供关于模型预测依据的解释,增强了模型的可信度。
关键设计:贡献感知融合模块的关键设计包括:1) 使用注意力机制学习贡献权重。注意力机制可以根据用户的特征,自动判断不同模态的重要性。2) 设计损失函数,鼓励模型学习稀疏的贡献权重。稀疏的权重可以使模型更加关注重要的模态,提高预测性能。3) 使用案例研究验证模型的可解释性。通过分析模型学习到的贡献权重,可以了解模型是如何做出预测的,从而验证模型的可信度。
🖼️ 关键图片
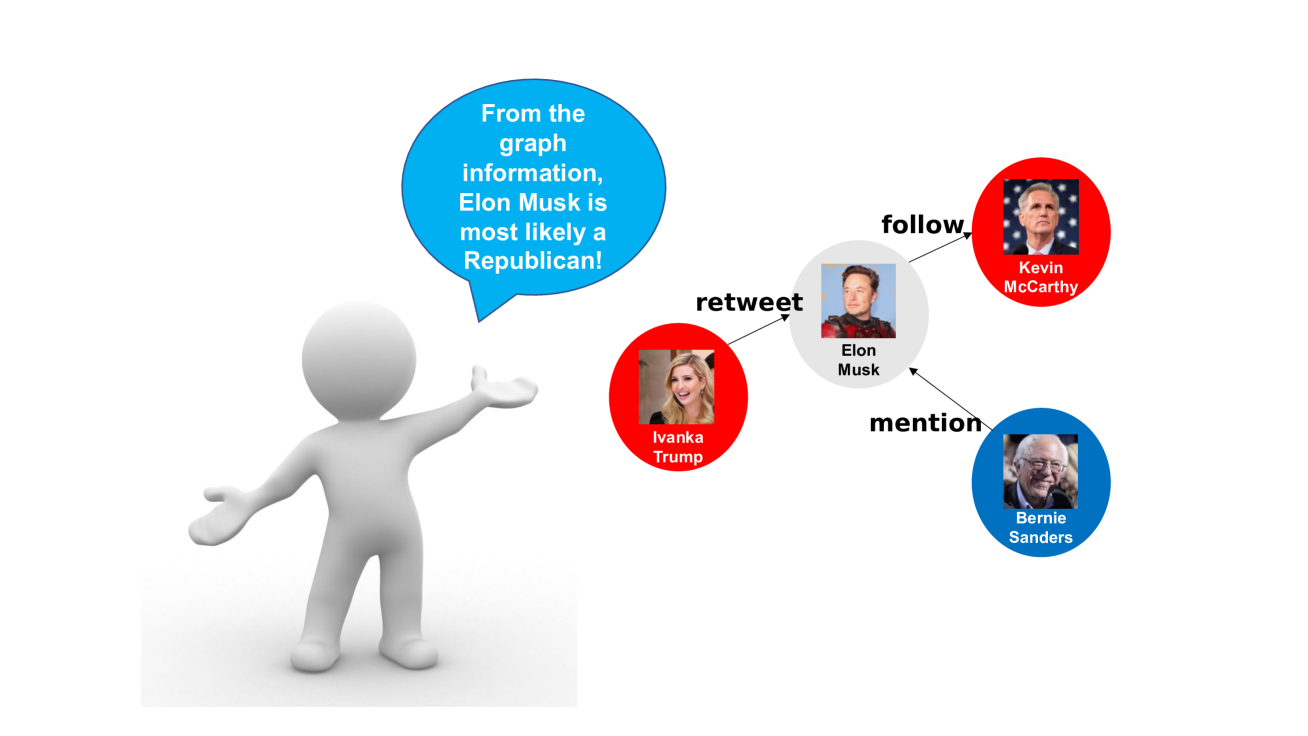

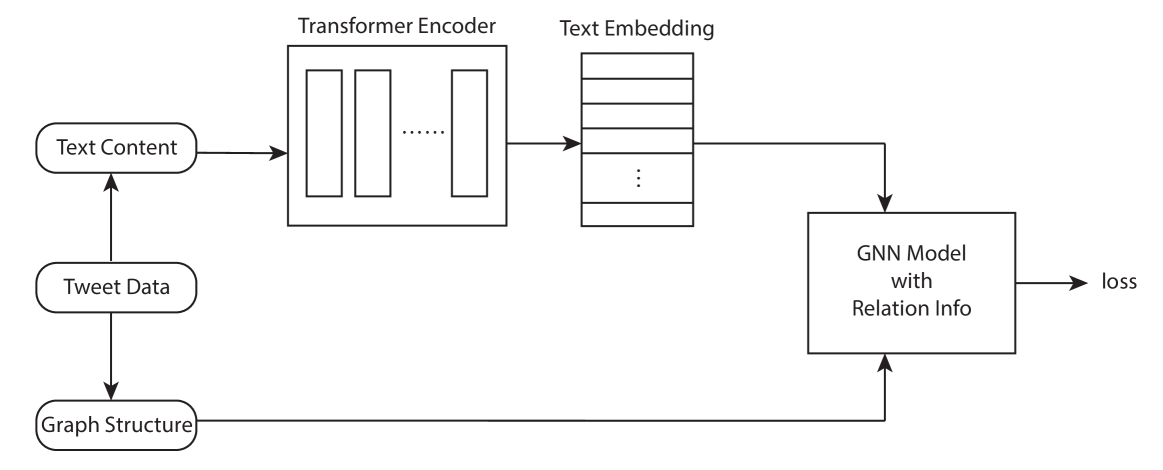
📊 实验亮点
实验结果表明,CAMUE在多个社交网络数据集上取得了显著的性能提升。例如,在用户分类任务中,CAMUE的准确率比现有最佳方法提高了3-5%。案例研究表明,CAMUE能够学习到合理的贡献权重,例如,对于发布大量虚假信息的用户,CAMUE会降低其文本信息的权重,而更加关注其在社交网络中的互动行为。
🎯 应用场景
CAMUE可应用于社交媒体内容推荐、恶意用户检测、虚假信息过滤等领域。通过个性化的用户嵌入和可解释的预测,可以更精准地推荐用户感兴趣的内容,识别潜在的恶意用户,并过滤不可靠的信息,提升社交媒体平台的用户体验和安全性。该研究还有助于提升人机交互的可信度,使用户更好地理解AI系统的决策过程。
📄 摘要(原文)
With the rapid development of social media, the importance of analyzing social network user data has also been put on the agenda. User representation learning in social media is a critical area of research, based on which we can conduct personalized content delivery, or detect malicious actors. Being more complicated than many other types of data, social network user data has inherent multimodal nature. Various multimodal approaches have been proposed to harness both text (i.e. post content) and relation (i.e. inter-user interaction) information to learn user embeddings of higher quality. The advent of Graph Neural Network models enables more end-to-end integration of user text embeddings and user interaction graphs in social networks. However, most of those approaches do not adequately elucidate which aspects of the data - text or graph structure information - are more helpful for predicting each specific user under a particular task, putting some burden on personalized downstream analysis and untrustworthy information filtering. We propose a simple yet effective framework called Contribution-Aware Multimodal User Embedding (CAMUE) for social networks. We have demonstrated with empirical evidence, that our approach can provide personalized explainable predictions, automatically mitigating the impact of unreliable information. We also conducted case studies to show how reasonable our results are. We observe that for most users, graph structure information is more trustworthy than text information, but there are some reasonable cases where text helps more. Our work paves the way for more explainable, reliable, and effective social media user embedding which allows for better personalized content delivery.