Unifying Causal Representation Learning with the Invariance Principle
作者: Dingling Yao, Dario Rancati, Riccardo Cadei, Marco Fumero, Francesco Locatello
分类: cs.LG, stat.ML
发布日期: 2024-09-04 (更新: 2025-03-05)
备注: ICLR2025 Camera ready
💡 一句话要点
统一因果表示学习与不变性原则,提升高维数据因果推断能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 因果表示学习 不变性原则 因果推断 数据对称性 高维数据 治疗效果估计 因果发现
📋 核心要点
- 现有因果表示学习方法依赖于严格的因果假设,缺乏通用性,难以适应不同类型的数据。
- 该论文提出基于数据对称性的不变性原则,统一多种因果表示学习方法,实现更灵活的因果变量识别。
- 实验表明,该方法在真实世界高维生态数据上,提升了治疗效果估计的准确性,验证了方法的有效性。
📝 摘要(中文)
因果表示学习(CRL)旨在从高维观测中恢复潜在的因果变量,以解决因果下游任务,例如预测新的干预效果或更鲁棒的分类。目前已开发了大量方法,每种方法都针对精心设计的特定问题设置,从而导致不同类型的可识别性。人们普遍认为这些不同的设置非常重要,因为它们通常与Pearl因果层次结构的不同层级相关联,即使这种对应关系并不总是完全准确。本文表明,许多因果表示学习方法在方法论上将其表示与固有的数据对称性对齐,而不是严格遵守这种分层映射。因果变量的识别是由不一定是因果关系的不变性原则指导的。这一结果使我们能够将许多现有方法统一到一个单一的方法中,该方法可以根据与手头问题相关的不变性混合和匹配不同的假设,包括非因果假设。它还显著提高了适用性,我们通过改进对真实世界高维生态数据的治疗效果估计来证明这一点。总的来说,本文阐明了因果假设在因果变量发现中的作用,并将重点转移到保持数据对称性上。
🔬 方法详解
问题定义:现有的因果表示学习方法通常针对特定的问题设置和因果假设,导致方法之间缺乏统一性,难以灵活应用于不同的场景。这些方法往往依赖于Pearl因果层次结构,但实际应用中这种对应关系并不总是准确的。因此,如何设计一种通用的因果表示学习框架,能够适应不同的数据特征和任务需求,是一个重要的挑战。
核心思路:该论文的核心思路是,将因果表示学习与数据固有的对称性联系起来,利用不变性原则来指导因果变量的识别。作者认为,许多现有的因果表示学习方法实际上是在寻找与数据对称性对齐的表示,而这些对称性不一定具有因果关系。通过将不同的因果假设和非因果假设统一到一个框架中,可以更灵活地进行因果推断。
技术框架:该论文提出了一个统一的因果表示学习框架,该框架允许混合和匹配不同的假设,包括因果假设和非因果假设。具体来说,该框架首先学习数据的表示,然后利用不变性原则来识别因果变量。不变性原则可以通过不同的方法来实现,例如,通过寻找在不同环境下保持不变的表示,或者通过寻找与特定干预措施相关的表示。
关键创新:该论文最重要的技术创新点在于,它将因果表示学习与不变性原则联系起来,并提出了一个统一的框架,该框架可以混合和匹配不同的假设。这使得该方法能够更灵活地适应不同的数据特征和任务需求,从而提高了因果推断的准确性和鲁棒性。与现有方法相比,该方法不再局限于特定的因果假设,而是可以利用更广泛的数据信息。
关键设计:论文中关键的设计在于如何定义和利用不变性原则。具体实现可能依赖于特定的任务和数据,例如,可以使用对比学习来学习在不同环境下保持不变的表示,或者使用因果发现算法来识别与特定干预措施相关的表示。损失函数的设计需要考虑如何最大化表示的不变性,同时保持表示的表达能力。具体的网络结构和参数设置需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
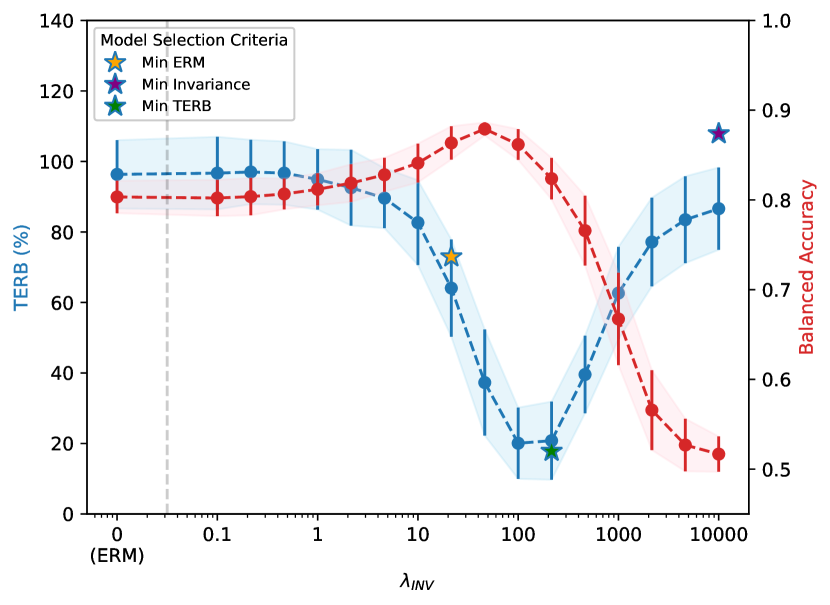
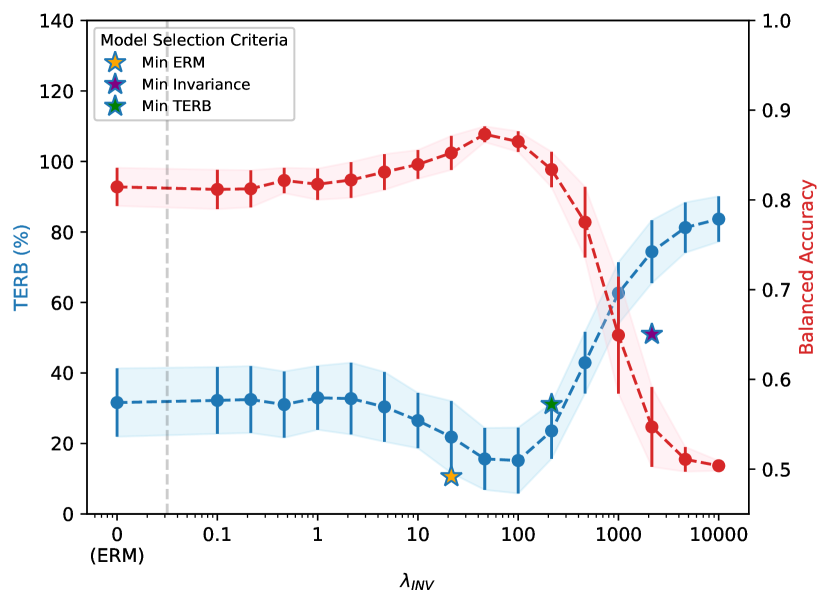
该论文在真实世界高维生态数据上进行了实验,结果表明,该方法能够显著提高治疗效果估计的准确性。具体而言,该方法在预测不同干预措施对生态系统影响方面,优于现有的因果表示学习方法,验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可广泛应用于需要因果推断的领域,例如医疗健康、金融风控、推荐系统等。通过更准确地识别因果变量,可以更好地预测干预效果,制定更有效的策略,并提高决策的可靠性。例如,在医疗领域,可以用于预测不同治疗方案对患者的影响;在金融领域,可以用于评估不同政策对市场的影响。
📄 摘要(原文)
Causal representation learning (CRL) aims at recovering latent causal variables from high-dimensional observations to solve causal downstream tasks, such as predicting the effect of new interventions or more robust classification. A plethora of methods have been developed, each tackling carefully crafted problem settings that lead to different types of identifiability. These different settings are widely assumed to be important because they are often linked to different rungs of Pearl's causal hierarchy, even though this correspondence is not always exact. This work shows that instead of strictly conforming to this hierarchical mapping, many causal representation learning approaches methodologically align their representations with inherent data symmetries. Identification of causal variables is guided by invariance principles that are not necessarily causal. This result allows us to unify many existing approaches in a single method that can mix and match different assumptions, including non-causal ones, based on the invariance relevant to the problem at hand. It also significantly benefits applicability, which we demonstrate by improving treatment effect estimation on real-world high-dimensional ecological data. Overall, this paper clarifies the role of causal assumptions in the discovery of causal variables and shifts the focus to preserving data symmetries.