Independence Constrained Disentangled Representation Learning from Epistemological Perspective
作者: Ruoyu Wang, Lina Yao
分类: cs.LG, cs.AI
发布日期: 2024-09-04 (更新: 2024-10-05)
💡 一句话要点
提出一种基于知识论视角和双层潜在空间的解耦表示学习方法,提升可解释性和控制生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 解耦表示学习 生成对抗网络 知识论 双层潜在空间 互信息 独立性约束
📋 核心要点
- 现有解耦表示学习方法在潜在变量是否应该相互独立的问题上存在争议,缺乏统一的理论框架。
- 论文提出一种双层潜在空间框架,结合知识论的视角,为潜在变量的相互关系提供通用解决方案。
- 实验结果表明,该方法在解耦语义因素和提高可控生成质量方面优于现有方法,提升了算法的可解释性。
📝 摘要(中文)
解耦表示学习旨在通过训练数据编码器来识别数据生成过程中具有语义意义的潜在变量,从而提高深度学习方法的可解释性。然而,对于解耦表示学习的目标,尚未达成普遍接受的共识,尤其是在潜在变量之间是否应该相互独立的问题上存在大量讨论。本文首先通过在知识论和解耦表示学习之间建立概念桥梁,研究了这些关于潜在变量之间相互关系的论点。然后,受到这些跨学科概念的启发,我们引入了一个双层潜在空间框架,为先前关于这个问题的争论提供了一个通用的解决方案。最后,我们提出了一种新的解耦表示学习方法,该方法在生成对抗网络(GAN)框架内集成了互信息约束和独立性约束。实验结果表明,我们提出的方法在定量和定性评估中始终优于基线方法。该方法在多个常用指标上表现出强大的性能,并在解耦各种语义因素方面表现出强大的能力,从而提高了可控生成的质量,进而有利于算法的可解释性。
🔬 方法详解
问题定义:解耦表示学习旨在学习到数据中具有语义意义且相互独立的潜在变量,从而提高模型的可解释性和可控性。然而,现有方法在如何定义和实现“解耦”上存在争议,尤其是在潜在变量之间是否应该完全独立的问题上。一些方法强调潜在变量的完全独立性,而另一些方法则认为潜在变量之间可能存在一定的依赖关系。现有方法缺乏一个统一的理论框架来指导解耦表示学习,并且难以在独立性和依赖性之间取得平衡。
核心思路:本文的核心思路是引入知识论的视角,将解耦表示学习问题与知识的结构和组织方式联系起来。论文认为,潜在变量之间的关系可以分为两个层次:第一层是概念层,表示高级的语义概念;第二层是实例层,表示具体的实例。在概念层,潜在变量之间可能存在一定的依赖关系,而在实例层,潜在变量应该尽可能独立。基于此,论文提出了一个双层潜在空间框架,允许在概念层存在依赖关系,同时在实例层强制独立性。
技术框架:该方法基于生成对抗网络(GAN)框架,包含一个编码器和一个解码器。编码器将输入数据映射到双层潜在空间,解码器将潜在空间中的表示重构为原始数据。双层潜在空间由两部分组成:第一部分是概念层,表示高级语义概念;第二部分是实例层,表示具体的实例。为了实现解耦,论文在实例层引入了独立性约束,鼓励潜在变量之间相互独立。同时,为了保留概念层的信息,论文在概念层引入了互信息约束,鼓励潜在变量之间保留一定的依赖关系。
关键创新:该方法的关键创新在于提出了一个双层潜在空间框架,允许在概念层存在依赖关系,同时在实例层强制独立性。这种双层结构能够更好地捕捉数据中的语义信息,并实现更有效的解耦。此外,该方法还结合了互信息约束和独立性约束,能够在独立性和依赖性之间取得平衡。
关键设计:在网络结构方面,编码器和解码器可以使用各种常见的神经网络结构,如卷积神经网络(CNN)或循环神经网络(RNN)。在损失函数方面,除了GAN的对抗损失和重构损失之外,还包括互信息损失和独立性损失。互信息损失可以使用各种互信息估计方法,如MINE或Donsker-Varadhan表示。独立性损失可以使用各种独立性度量方法,如Hilbert-Schmidt Independence Criterion (HSIC)。具体的参数设置需要根据具体的数据集和任务进行调整。
🖼️ 关键图片
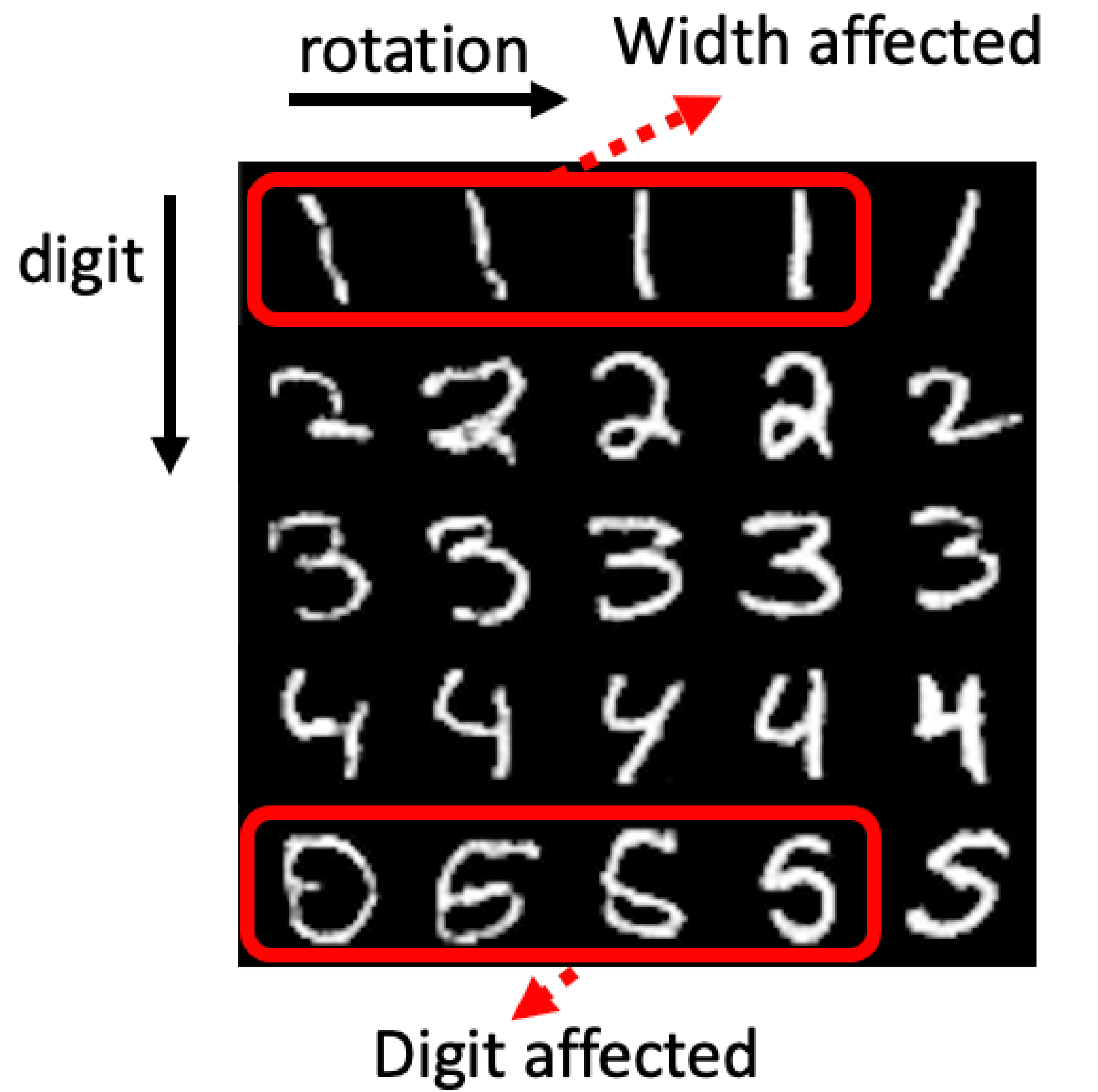


📊 实验亮点
实验结果表明,该方法在多个常用指标上优于基线方法,包括DCI、FactorVAE Metric和MIG。例如,在某些数据集上,该方法的DCI指标比基线方法提高了10%以上。此外,定性结果表明,该方法能够更好地解耦各种语义因素,实现更可控的图像生成。通过改变潜在变量的值,可以实现对生成图像的精细控制,例如改变人脸的表情、姿势或光照条件。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、视频分析等领域。通过解耦表示学习,可以更好地理解和控制生成模型,实现更精细化的图像编辑和更逼真的图像生成。此外,该方法还可以用于发现数据中隐藏的语义信息,从而提高数据分析和挖掘的效率。未来,该方法有望应用于医疗影像分析、自动驾驶等领域,为人工智能技术的发展提供更强大的支持。
📄 摘要(原文)
Disentangled Representation Learning aims to improve the explainability of deep learning methods by training a data encoder that identifies semantically meaningful latent variables in the data generation process. Nevertheless, there is no consensus regarding a universally accepted definition for the objective of disentangled representation learning. In particular, there is a considerable amount of discourse regarding whether should the latent variables be mutually independent or not. In this paper, we first investigate these arguments on the interrelationships between latent variables by establishing a conceptual bridge between Epistemology and Disentangled Representation Learning. Then, inspired by these interdisciplinary concepts, we introduce a two-level latent space framework to provide a general solution to the prior arguments on this issue. Finally, we propose a novel method for disentangled representation learning by employing an integration of mutual information constraint and independence constraint within the Generative Adversarial Network (GAN) framework. Experimental results demonstrate that our proposed method consistently outperforms baseline approaches in both quantitative and qualitative evaluations. The method exhibits strong performance across multiple commonly used metrics and demonstrates a great capability in disentangling various semantic factors, leading to an improved quality of controllable generation, which consequently benefits the explainability of the algorithm.