Robust Federated Finetuning of Foundation Models via Alternating Minimization of LoRA
作者: Shuangyi Chen, Yue Ju, Hardik Dalal, Zhongwen Zhu, Ashish Khisti
分类: cs.LG, cs.DC
发布日期: 2024-09-04
备注: Presented at ES-FOMO-II@ICML2024
💡 一句话要点
提出RoLoRA框架,通过交替最小化LoRA实现对联邦微调基础模型的鲁棒优化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 参数高效微调 LoRA 交替最小化 数据异构性 鲁棒性 基础模型
📋 核心要点
- 现有联邦学习结合LoRA的方法在参数减少和数据异构性方面存在鲁棒性问题,限制了其应用。
- RoLoRA通过交替最小化LoRA权重,增强了模型对数据异构性和参数减少的适应能力,提升了鲁棒性。
- 实验表明,RoLoRA在多种联邦微调场景中,相较于现有方法,显著提高了模型的鲁棒性和有效性。
📝 摘要(中文)
参数高效微调(PEFT)已成为一种创新的训练策略,它仅更新少量模型参数,从而显著降低计算和内存需求。PEFT还有助于减少联邦学习环境中的数据传输,因为通信量取决于更新的大小。在这项工作中,我们探讨了先前研究的局限性,这些研究将一种名为LoRA的著名PEFT方法与联邦微调相结合,然后引入RoLoRA,这是一种鲁棒的联邦微调框架,它利用LoRA的交替最小化方法,从而在减少微调参数和增加数据异构性方面提供更大的鲁棒性。我们的结果表明,RoLoRA不仅具有通信优势,而且在多种联邦微调场景中显著提高了鲁棒性和有效性。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,使用LoRA进行参数高效微调时,由于数据异构性和微调参数减少导致的模型鲁棒性下降问题。现有方法在面对客户端数据分布差异大或可用参数较少时,性能会显著降低。
核心思路:RoLoRA的核心思路是通过交替最小化LoRA的权重,从而提高模型对数据异构性的适应能力。这种方法允许模型在不同客户端之间更有效地共享知识,并减少对特定客户端数据的过度拟合。
技术框架:RoLoRA框架基于标准的联邦学习流程,主要包含以下几个阶段:1) 服务器初始化全局模型;2) 服务器将全局模型分发给各个客户端;3) 客户端使用本地数据和RoLoRA算法对模型进行微调;4) 客户端将LoRA权重更新发送回服务器;5) 服务器聚合来自客户端的LoRA权重更新,并更新全局模型。
关键创新:RoLoRA的关键创新在于使用交替最小化方法来优化LoRA权重。传统的LoRA微调通常采用单步优化,容易受到数据异构性的影响。而RoLoRA通过交替优化LoRA的两个矩阵,能够更有效地探索参数空间,从而提高模型的鲁棒性。
关键设计:RoLoRA的关键设计包括:1) 使用LoRA进行参数高效微调,减少通信开销;2) 采用交替最小化算法优化LoRA权重,具体来说,LoRA将一个预训练好的权重矩阵分解为两个低秩矩阵A和B,RoLoRA交替固定A优化B,再固定B优化A;3) 使用标准的联邦平均算法聚合客户端的LoRA权重更新。损失函数通常采用交叉熵损失或均方误差损失,具体取决于任务类型。
🖼️ 关键图片
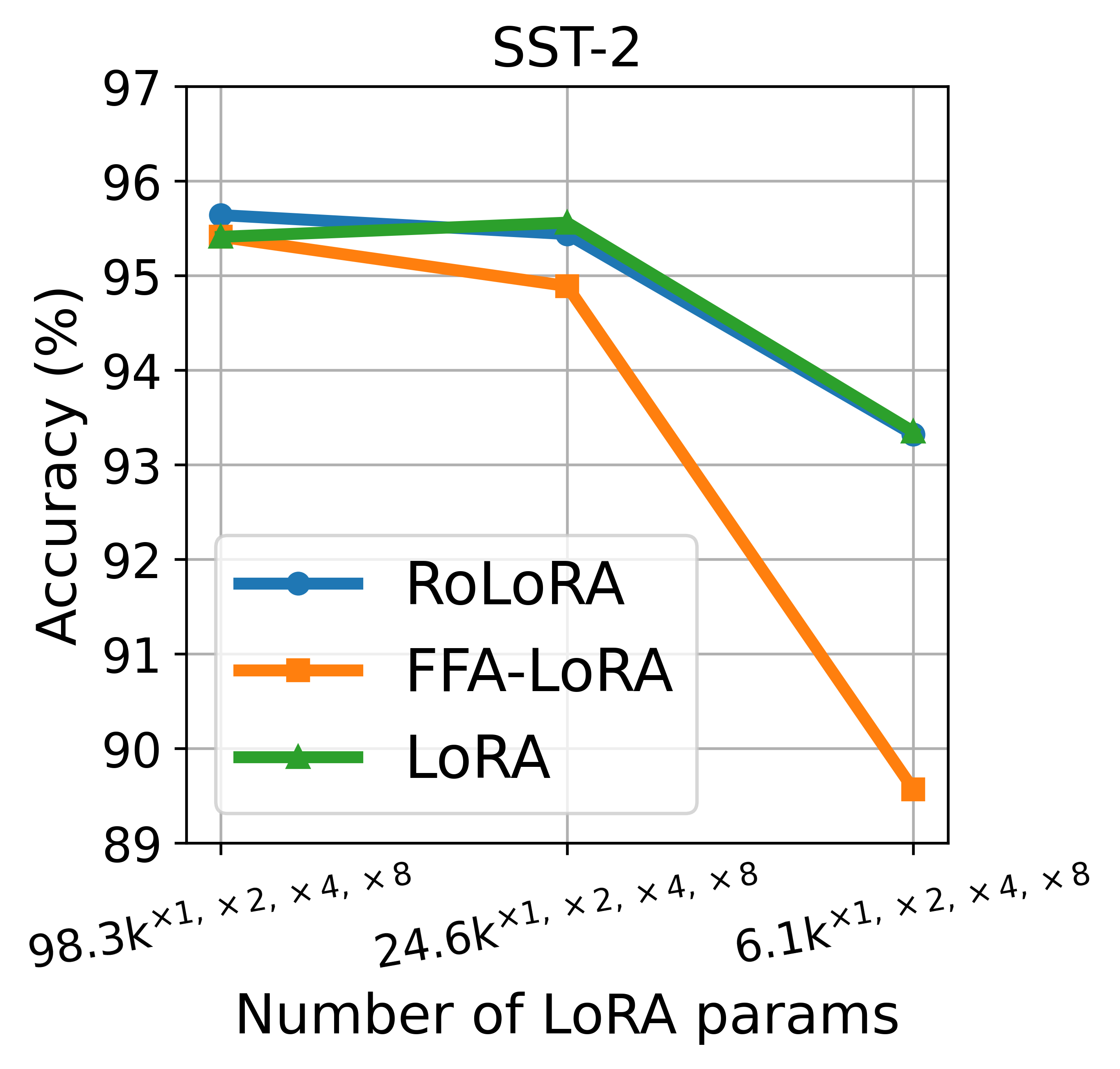

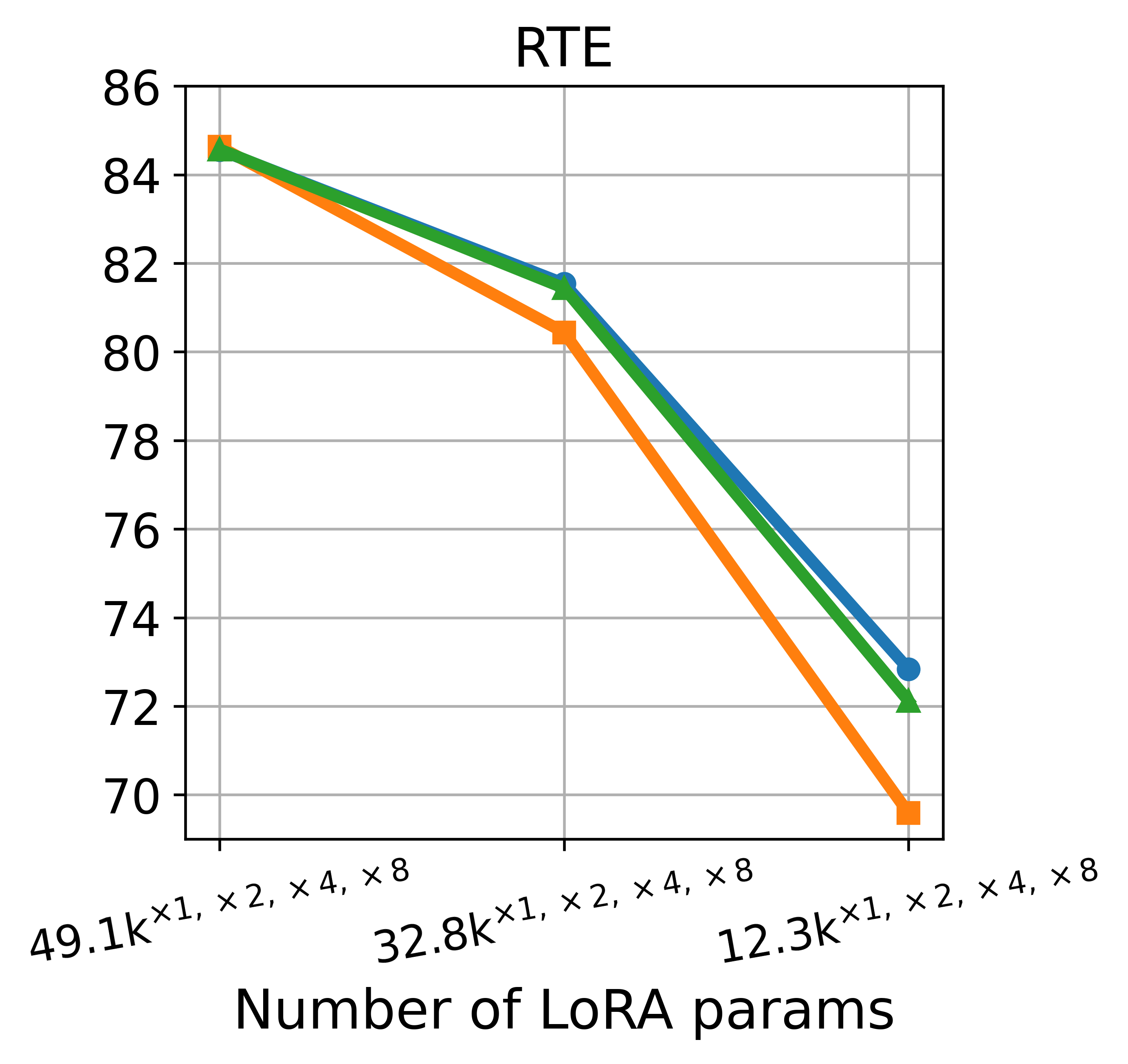
📊 实验亮点
实验结果表明,RoLoRA在数据异构性较强的联邦学习场景下,相较于传统的联邦学习和基于LoRA的联邦学习方法,能够显著提高模型的准确率和鲁棒性。具体而言,在某些数据集上,RoLoRA的性能提升可达5%-10%。
🎯 应用场景
RoLoRA适用于各种需要联邦学习和参数高效微调的场景,例如:跨设备自然语言处理、个性化推荐系统、医疗健康数据分析等。该方法可以有效降低通信成本,保护用户隐私,并提高模型在异构数据上的泛化能力,具有广泛的应用前景。
📄 摘要(原文)
Parameter-Efficient Fine-Tuning (PEFT) has risen as an innovative training strategy that updates only a select few model parameters, significantly lowering both computational and memory demands. PEFT also helps to decrease data transfer in federated learning settings, where communication depends on the size of updates. In this work, we explore the constraints of previous studies that integrate a well-known PEFT method named LoRA with federated fine-tuning, then introduce RoLoRA, a robust federated fine-tuning framework that utilizes an alternating minimization approach for LoRA, providing greater robustness against decreasing fine-tuning parameters and increasing data heterogeneity. Our results indicate that RoLoRA not only presents the communication benefits but also substantially enhances the robustness and effectiveness in multiple federated fine-tuning scenarios.