SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration
作者: Joseph M. Cavanagh, Kunyang Sun, Andrew Gritsevskiy, Dorian Bagni, Yingze Wang, Thomas D. Bannister, Teresa Head-Gordon
分类: physics.chem-ph, cs.LG
发布日期: 2024-09-03 (更新: 2025-11-12)
💡 一句话要点
SmileyLlama:通过指令微调LLM实现定向化学空间探索
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 化学语言模型 指令微调 药物发现 分子生成
📋 核心要点
- 现有化学语言模型在生成具有特定属性的分子方面存在局限性,缺乏与用户指令的有效交互。
- 通过指令微调通用LLM,使其能够理解和执行化学相关的指令,从而定向生成具有所需属性的分子。
- SmileyLlama在生成有效和新颖的类药分子方面表现出色,并能通过强化学习优化分子与药物靶标的结合亲和力。
📝 摘要(中文)
本文展示了如何通过对通用大型语言模型(LLM)Llama-3.1-8B-Instruct进行监督式微调,将其转化为化学语言模型(CLM)SmileyLlama,用于分子生成。通过与从头开始在大量ChEMBL数据上训练的CLM进行比较,评估了SmileyLlama生成有效和新颖的类药分子的能力。此外,使用直接偏好优化(DPO)来提高SmileyLlama对提示的遵循程度,并在iMiner强化学习框架内生成分子,以预测具有优化3D构象和对药物靶标(以SARS-Cov-2主蛋白酶为例)具有高结合亲和力的新药分子。该框架使LLM能够直接作为CLM生成具有用户指定属性的分子,而不仅仅是作为具有化学知识的聊天机器人或有用的虚拟助手。虽然数据集和分析侧重于药物发现,但此通用过程可以扩展到其他化学应用,例如化学合成。
🔬 方法详解
问题定义:论文旨在解决药物发现领域中,如何利用大型语言模型(LLM)高效生成具有特定性质(例如,与特定靶标蛋白具有高亲和力)的类药分子的问题。现有方法,如从头训练的化学语言模型(CLM),虽然可以生成分子,但缺乏与用户指令的有效交互,难以定向生成满足特定需求的分子。
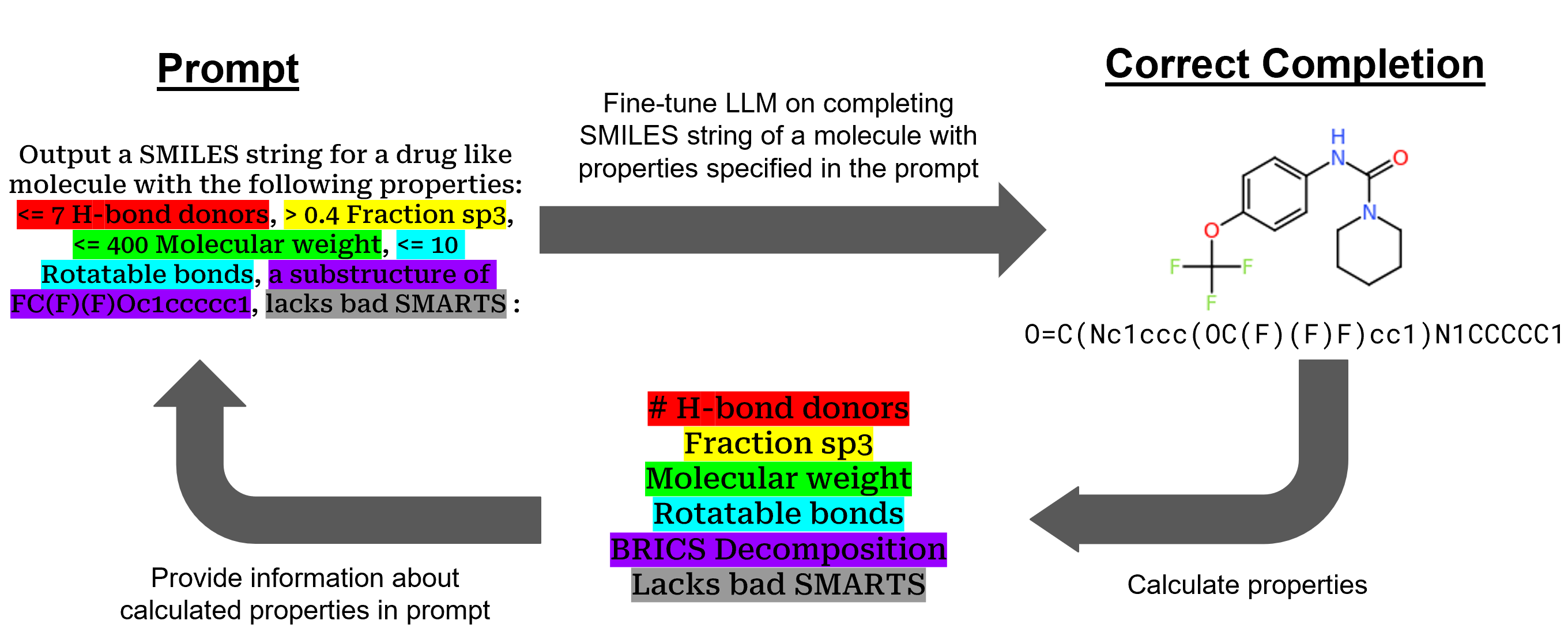
核心思路:论文的核心思路是将一个预训练的通用LLM(Llama-3.1-8B-Instruct)通过指令微调(instruction tuning)转化为一个化学语言模型(CLM),命名为SmileyLlama。通过精心设计的提示(prompt)和监督学习,使LLM能够理解和执行化学相关的指令,从而定向生成具有所需属性的分子。
技术框架:整体框架包含以下几个主要阶段:1) 选择一个预训练的通用LLM作为基础模型。2) 构建包含化学相关指令和对应分子结构的训练数据集。3) 使用监督学习对LLM进行微调,使其能够理解和生成SMILES字符串。4) 使用直接偏好优化(DPO)进一步提高模型对提示的遵循程度。5) 将模型集成到iMiner强化学习框架中,以优化分子与特定药物靶标的结合亲和力。
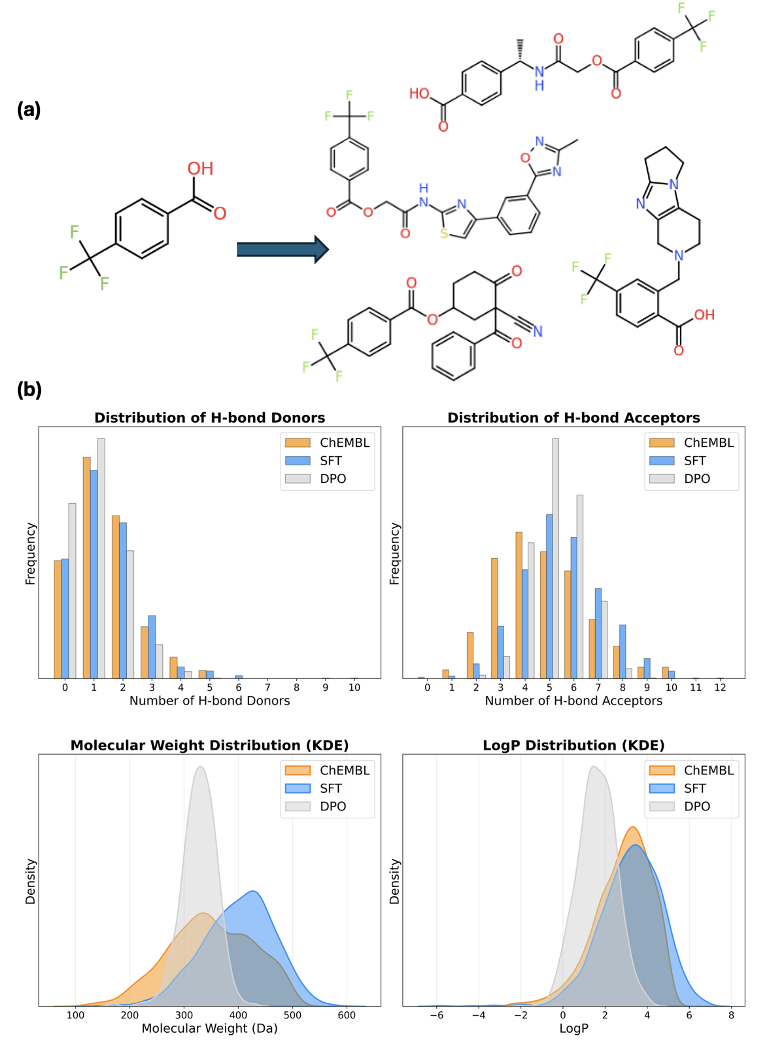
关键创新:最重要的技术创新点在于利用指令微调将通用LLM转化为CLM。与从头训练CLM相比,这种方法可以利用LLM强大的语言理解和生成能力,并能通过指令实现对分子生成过程的更精细控制。此外,结合DPO和强化学习,进一步提升了模型生成具有特定属性分子的能力。
关键设计:关键设计包括:1) 精心设计的提示(prompt),用于指导LLM生成特定类型的分子。2) 使用SMILES字符串作为分子表示,方便LLM进行处理。3) 使用直接偏好优化(DPO)来微调模型,使其更好地遵循指令。4) 将模型集成到iMiner强化学习框架中,使用结合亲和力作为奖励信号,优化分子结构。
🖼️ 关键图片
📊 实验亮点
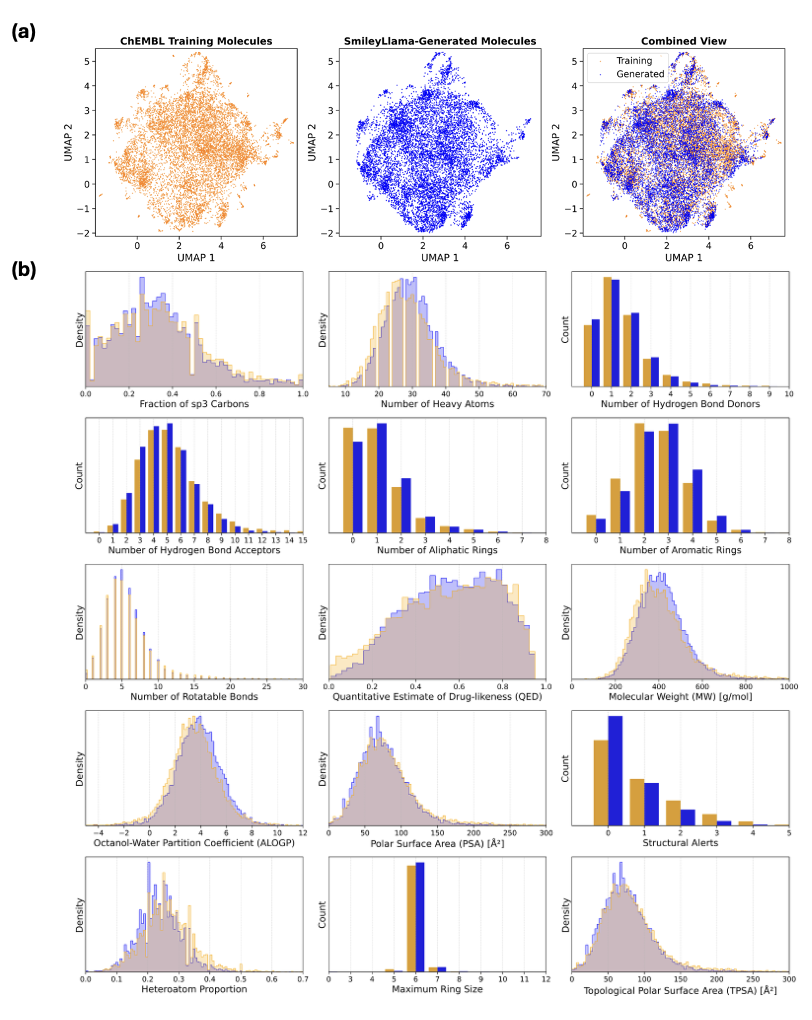
SmileyLlama在生成有效和新颖的类药分子方面表现出与从头训练的CLM相当的性能。通过直接偏好优化(DPO),SmileyLlama对提示的遵循程度得到了显著提高。在iMiner强化学习框架中,SmileyLlama成功生成了与SARS-Cov-2主蛋白酶具有高结合亲和力的分子,验证了该方法在药物发现中的潜力。
🎯 应用场景
该研究成果可应用于药物发现领域,加速新药的筛选和优化过程。通过指定药物靶标和所需性质,研究人员可以利用SmileyLlama快速生成候选分子,并利用强化学习优化其与靶标的结合亲和力。此外,该方法还可以扩展到其他化学应用,例如材料科学和化学合成,用于设计具有特定功能的分子和材料。
📄 摘要(原文)
Here we show that a general-purpose large language model (LLM) chatbot, Llama-3.1-8B-Instruct, can be transformed via supervised fine-tuning of engineered prompts into a chemical language model (CLM), SmileyLlama, for molecule generation. We benchmark SmileyLlama by comparing it to CLMs trained from scratch on large amounts of ChEMBL data for their ability to generate valid and novel drug-like molecules. We also use direct preference optimization to both improve SmileyLlama's adherence to a prompt and to generate molecules within the iMiner reinforcement learning framework to predict new drug molecules with optimized 3D conformations and high binding affinity to drug targets, illustrated with the SARS-Cov-2 Main Protease. This overall framework allows a LLM to speak directly as a CLM which can generate molecules with user-specified properties, rather than acting only as a chatbot with knowledge of chemistry or as a helpful virtual assistant. While our dataset and analyses are geared toward drug discovery, this general procedure can be extended to other chemical applications such as chemical synthesis.