Real-Time Recurrent Learning using Trace Units in Reinforcement Learning
作者: Esraa Elelimy, Adam White, Michael Bowling, Martha White
分类: cs.LG, cs.AI
发布日期: 2024-09-02 (更新: 2024-10-30)
备注: Neurips 2024
💡 一句话要点
提出基于Trace Units的实时循环学习方法,提升强化学习在部分可观测环境中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环神经网络 实时循环学习 强化学习 部分可观测环境 线性循环单元 在线学习 Trace Units
📋 核心要点
- 传统RNN的RTRL训练在在线强化学习中计算成本过高,限制了其在部分可观测环境中的应用。
- 论文提出Recurrent Trace Units (RTUs),对线性循环单元(LRUs)进行微小但关键的修改,提升RTRL训练效率。
- 实验表明,RTUs在多个部分可观测环境中显著优于其他循环架构,同时降低了计算成本。
📝 摘要(中文)
循环神经网络(RNNs)被用于学习部分可观测环境中的表征。对于在线学习并持续与环境交互的智能体,使用实时循环学习(RTRL)训练RNNs是理想的;不幸的是,RTRL对于标准RNNs来说计算成本过高。一个有希望的方向是使用线性循环架构(LRUs),其中密集的循环权重被复值对角矩阵所取代,从而使RTRL变得高效。在这项工作中,我们基于这些见解,提供了一种轻量级但有效的方法,用于在线强化学习中训练RNNs。我们引入了循环Trace Units(RTUs),这是对LRUs的一个小修改,但我们发现,当使用RTRL训练时,RTUs比LRUs具有显著的性能优势。我们发现,RTUs在多个部分可观测环境中显著优于其他循环架构,同时使用的计算量明显更少。
🔬 方法详解
问题定义:论文旨在解决在线强化学习中,传统RNN由于RTRL训练计算复杂度过高,难以有效应用于部分可观测环境的问题。现有方法,如标准RNN,在RTRL训练下计算成本巨大,而线性循环单元(LRUs)虽然降低了计算复杂度,但在性能上有所欠缺。
核心思路:论文的核心思路是在LRUs的基础上引入Recurrent Trace Units (RTUs),通过对LRU进行微小的修改,使其在RTRL训练下能够更好地捕捉时间依赖关系,从而提升在部分可观测环境中的学习性能。RTUs的设计目标是在计算效率和表征能力之间取得平衡。
技术框架:整体框架是标准的在线强化学习流程,智能体与环境进行交互,并使用RTRL算法更新RNN的参数。关键在于RNN的循环单元采用了RTUs。具体流程包括:1. 智能体根据当前状态选择动作;2. 环境返回奖励和下一个状态;3. 使用RTRL算法,基于奖励和状态转移更新RTUs的参数。
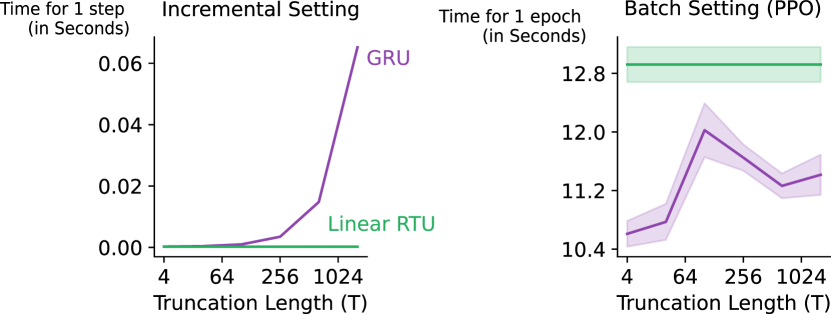
关键创新:最重要的技术创新点是RTUs的设计。RTUs是对LRUs的改进,通过引入trace机制,使得网络能够更好地追踪和利用过去的信息,从而提升对时间依赖关系的建模能力。与LRUs相比,RTUs在计算复杂度增加不多的情况下,显著提升了性能。
关键设计:RTUs的关键设计在于其trace更新机制。具体来说,RTUs维护一个trace向量,该向量用于记录过去激活值的累积影响。在每个时间步,trace向量根据当前的激活值和衰减因子进行更新。RTUs的输出是当前激活值和trace向量的加权和。衰减因子是一个重要的超参数,用于控制过去信息的影响程度。损失函数通常是标准的强化学习损失函数,如TD误差或策略梯度损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RTUs在多个部分可观测环境中显著优于其他循环架构,包括标准RNN和LRUs。具体来说,RTUs在某些任务上的性能提升超过了10%,同时使用的计算量明显更少。这表明RTUs在计算效率和性能之间取得了良好的平衡。
🎯 应用场景
该研究成果可应用于机器人导航、对话系统、金融交易等需要处理部分可观测环境和在线学习的领域。通过使用RTUs,智能体可以更有效地学习环境的动态特性,从而做出更明智的决策。未来,该技术有望在资源受限的设备上实现高性能的在线强化学习。
📄 摘要(原文)
Recurrent Neural Networks (RNNs) are used to learn representations in partially observable environments. For agents that learn online and continually interact with the environment, it is desirable to train RNNs with real-time recurrent learning (RTRL); unfortunately, RTRL is prohibitively expensive for standard RNNs. A promising direction is to use linear recurrent architectures (LRUs), where dense recurrent weights are replaced with a complex-valued diagonal, making RTRL efficient. In this work, we build on these insights to provide a lightweight but effective approach for training RNNs in online RL. We introduce Recurrent Trace Units (RTUs), a small modification on LRUs that we nonetheless find to have significant performance benefits over LRUs when trained with RTRL. We find RTUs significantly outperform other recurrent architectures across several partially observable environments while using significantly less computation.