ToolACE: Winning the Points of LLM Function Calling
作者: Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, Enhong Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-09-02 (更新: 2025-07-25)
备注: 21 pages, 22 figures
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
ToolACE:通过自进化Agent流程生成高质量函数调用数据,显著提升LLM工具使用能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 函数调用 大型语言模型 数据合成 自进化 多Agent系统
📋 核心要点
- 现有函数调用数据合成方法缺乏覆盖率和准确性,难以充分训练LLM的工具使用能力。
- ToolACE通过自进化Agent流程,自动生成准确、复杂和多样化的工具学习数据,有效扩充训练集。
- 实验证明,使用ToolACE生成的数据训练的模型,即使参数量较小,也能在函数调用任务上达到SOTA性能。
📝 摘要(中文)
函数调用显著扩展了大型语言模型的应用边界,而高质量和多样化的训练数据对于释放这种能力至关重要。然而,真实的函数调用数据收集和标注非常具有挑战性,而现有流程生成的合成数据往往缺乏覆盖率和准确性。本文提出了ToolACE,一个自动化的Agent流程,旨在生成准确、复杂和多样化的工具学习数据。ToolACE利用一种新颖的自进化合成过程来管理一个包含26,507个多样化API的综合API池。对话通过多个Agent之间的交互生成,并由形式化的思考过程指导。为了确保数据准确性,我们实现了一个双层验证系统,结合了基于规则和基于模型的检查。实验表明,即使只有80亿参数的模型,在我们的合成数据上训练后,也能在Berkeley Function-Calling Leaderboard上取得最先进的性能,与最新的GPT-4模型相媲美。我们的模型和部分数据已在https://huggingface.co/Team-ACE上公开。
🔬 方法详解
问题定义:现有方法在生成函数调用数据时面临挑战,主要体现在两个方面:一是真实函数调用数据难以收集和标注,成本高昂;二是现有的合成数据生成流程覆盖率和准确性不足,导致训练出的LLM在工具使用方面表现不佳。因此,如何高效、低成本地生成高质量、多样化的函数调用数据,是本文要解决的核心问题。
核心思路:ToolACE的核心思路是利用多Agent协作和自进化机制,模拟真实场景下的函数调用过程,从而自动生成高质量的训练数据。通过不断迭代和优化API池,以及引入双层验证机制,确保生成数据的准确性和多样性。这种方法旨在克服现有合成数据生成流程的局限性,提高LLM在函数调用任务中的性能。
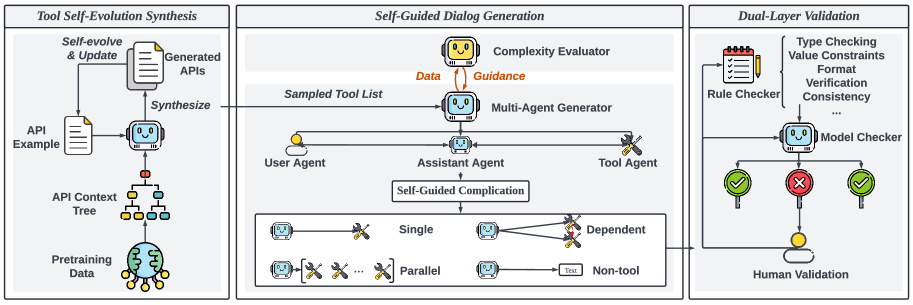
技术框架:ToolACE的整体框架包含以下几个主要模块:1) API池构建:通过自进化合成过程,收集和管理一个包含大量API的API池。2) 对话生成:多个Agent在形式化思考过程的指导下进行交互,生成对话数据,模拟真实场景下的函数调用过程。3) 数据验证:采用双层验证系统,包括基于规则的验证和基于模型的验证,确保生成数据的准确性。整个流程自动化运行,无需人工干预。
关键创新:ToolACE的关键创新在于其自进化合成过程和双层验证系统。自进化合成过程能够不断扩充和优化API池,提高数据的多样性;双层验证系统能够有效过滤错误数据,保证数据的准确性。此外,多Agent协作的对话生成方式也更贴近真实场景,有助于提高LLM的泛化能力。
关键设计:在API池构建方面,采用了自进化策略,不断添加新的API,并删除无效的API。在对话生成方面,设计了形式化的思考过程,指导Agent进行交互,确保对话的逻辑性和连贯性。在数据验证方面,基于规则的验证主要检查API调用是否符合规范,基于模型的验证则利用LLM判断对话的合理性。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
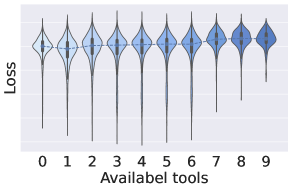
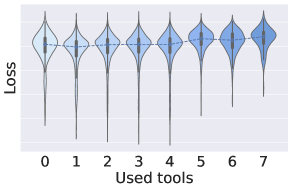
实验结果表明,使用ToolACE生成的数据训练的8B参数模型,在Berkeley Function-Calling Leaderboard上取得了SOTA性能,甚至可以与GPT-4相媲美。这证明了ToolACE生成数据的有效性和高质量,为低成本训练高性能函数调用模型提供了新的途径。
🎯 应用场景
ToolACE生成的函数调用数据可以广泛应用于训练各种LLM,提高其工具使用能力,从而赋能智能助手、自动化流程、智能客服等应用场景。该研究降低了高质量函数调用数据的获取成本,加速了LLM在实际应用中的落地,并有望推动人机协作的进一步发展。
📄 摘要(原文)
Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.