Mamba or Transformer for Time Series Forecasting? Mixture of Universals (MoU) Is All You Need
作者: Sijia Peng, Yun Xiong, Yangyong Zhu, Zhiqiang Shen
分类: cs.LG, cs.AI
发布日期: 2024-08-28
备注: Code at https://github.com/lunaaa95/mou/
🔗 代码/项目: GITHUB
💡 一句话要点
提出混合通用模型(MoU),融合Mamba与Transformer,提升时间序列预测精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 时间序列预测 长期依赖建模 Mamba Transformer 混合架构 自注意力机制 特征提取器混合
📋 核心要点
- 现有时间序列预测方法侧重长期依赖,忽略短期动态,导致预测精度受限。
- MoU模型通过特征提取器混合(MoF)和架构混合(MoA)自适应地建模短期和长期依赖。
- 实验表明,MoU在多个数据集上达到SOTA性能,同时保持较低的计算成本。
📝 摘要(中文)
时间序列预测需要平衡短期和长期依赖关系以实现准确的预测。现有方法主要侧重于长期依赖建模,忽略了短期动态的复杂性,这可能会阻碍性能。Transformer在建模长期依赖方面表现出色,但因其二次计算成本而备受诟病。Mamba提供了一种接近线性的替代方案,但据报道,由于潜在的信息丢失,在时间序列长期预测中效果较差。目前的架构在为长期依赖建模提供高效率和强大性能方面存在不足。为了应对这些挑战,我们引入了混合通用模型(MoU),这是一种多功能模型,可以捕获短期和长期依赖关系,从而提高时间序列预测的性能。MoU由两个新颖的设计组成:特征提取器混合(MoF),一种自适应方法,旨在改进时间序列patch表示以实现短期依赖;以及架构混合(MoA),它以专门的顺序分层集成Mamba、前馈、卷积和自注意力架构,以从混合的角度对长期依赖进行建模。所提出的方法在保持相对较低的计算成本的同时,实现了最先进的性能。在七个真实世界数据集上的大量实验证明了MoU的优越性。
🔬 方法详解
问题定义:时间序列预测任务需要同时捕捉短期和长期依赖关系。现有方法要么侧重于Transformer的长期依赖建模能力,但计算成本高昂;要么采用Mamba等线性复杂度模型,但可能损失信息,导致长期预测效果不佳。因此,如何在效率和性能之间取得平衡是关键问题。
核心思路:MoU的核心思路是将不同的架构进行混合,利用各自的优势来建模时间序列数据的不同方面。具体来说,MoF负责提取更有效的短期特征,而MoA则负责以分层的方式整合不同的架构(Mamba, FeedForward, Convolution, Self-Attention)来建模长期依赖。通过这种混合的方式,MoU旨在兼顾效率和性能。
技术框架:MoU模型主要包含两个核心模块:MoF(Mixture of Feature Extractors)和MoA(Mixture of Architectures)。首先,时间序列数据被分割成patches,然后通过MoF模块提取patches的特征表示,MoF自适应地选择不同的特征提取器来捕捉短期依赖。接下来,提取的特征被输入到MoA模块,MoA以分层的方式整合Mamba、前馈网络、卷积和自注意力机制,从而建模长期依赖。最终,MoA的输出用于进行时间序列预测。
关键创新:MoU的关键创新在于其混合架构的设计,特别是MoF和MoA两个模块。MoF通过自适应地选择不同的特征提取器来增强短期依赖的建模能力。MoA则通过分层整合不同的架构,充分利用了各种架构的优势,从而更有效地建模长期依赖。这种混合架构的设计使得MoU能够在效率和性能之间取得更好的平衡。
关键设计:MoF的关键设计在于如何自适应地选择特征提取器。具体实现细节未知,但推测可能使用了某种门控机制或注意力机制来动态地调整不同特征提取器的权重。MoA的关键设计在于如何分层整合不同的架构。论文中提到了一种特定的顺序,但具体顺序和理由未知。损失函数和具体的网络结构细节也未知。
🖼️ 关键图片
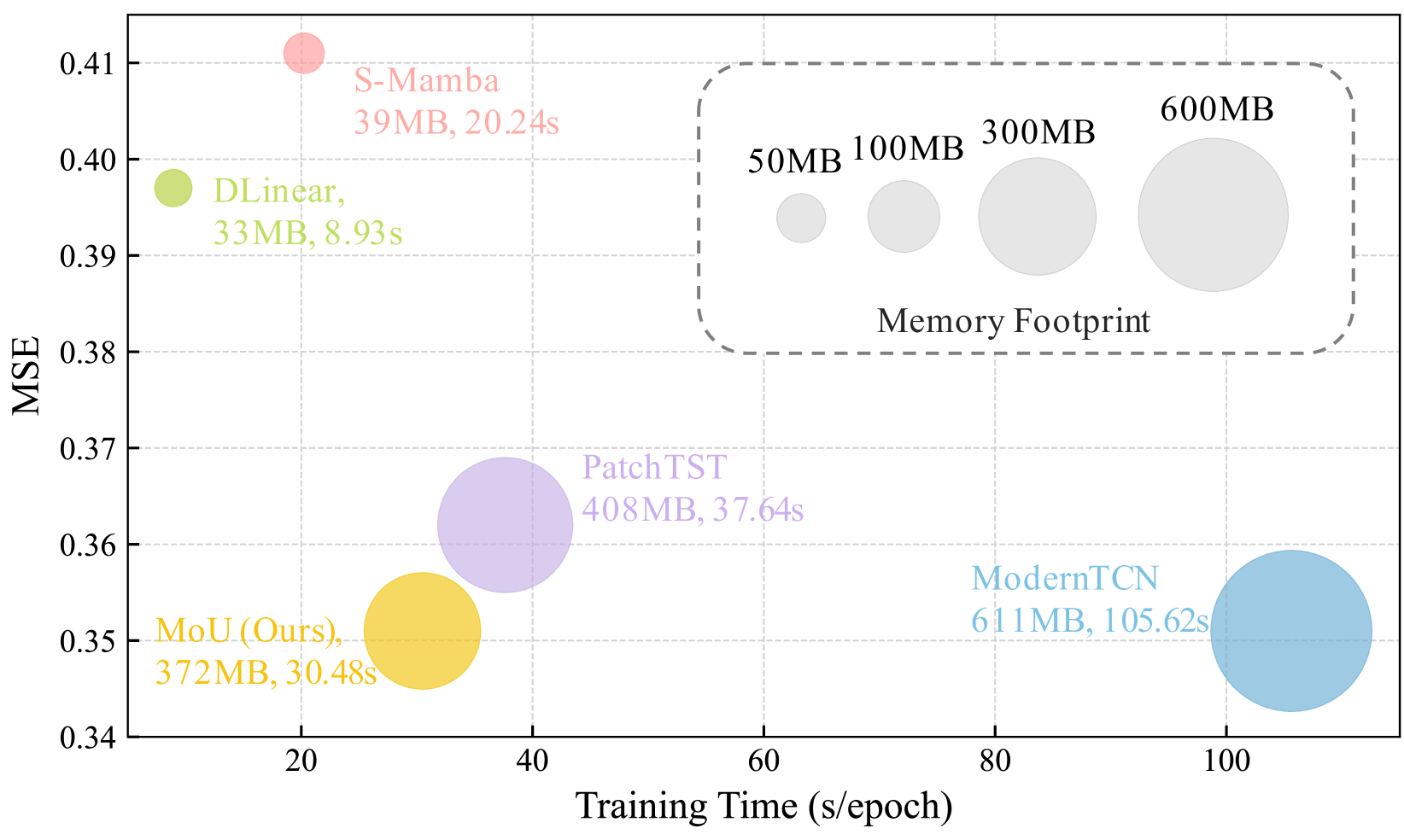


📊 实验亮点
MoU模型在七个真实世界数据集上进行了广泛的实验,结果表明MoU在时间序列预测任务上达到了最先进的性能。具体的性能提升幅度未知,但摘要中强调了MoU在保持相对较低计算成本的同时,实现了SOTA性能,这意味着MoU在效率和准确性之间取得了良好的平衡。
🎯 应用场景
该研究成果可广泛应用于金融市场预测、能源需求预测、供应链管理、交通流量预测等领域。通过更准确地预测未来趋势,可以帮助企业和政府做出更明智的决策,提高运营效率,降低风险,并优化资源配置。该模型在长期预测方面的优势,使其在需要提前规划的场景中具有重要价值。
📄 摘要(原文)
Time series forecasting requires balancing short-term and long-term dependencies for accurate predictions. Existing methods mainly focus on long-term dependency modeling, neglecting the complexities of short-term dynamics, which may hinder performance. Transformers are superior in modeling long-term dependencies but are criticized for their quadratic computational cost. Mamba provides a near-linear alternative but is reported less effective in time series longterm forecasting due to potential information loss. Current architectures fall short in offering both high efficiency and strong performance for long-term dependency modeling. To address these challenges, we introduce Mixture of Universals (MoU), a versatile model to capture both short-term and long-term dependencies for enhancing performance in time series forecasting. MoU is composed of two novel designs: Mixture of Feature Extractors (MoF), an adaptive method designed to improve time series patch representations for short-term dependency, and Mixture of Architectures (MoA), which hierarchically integrates Mamba, FeedForward, Convolution, and Self-Attention architectures in a specialized order to model long-term dependency from a hybrid perspective. The proposed approach achieves state-of-the-art performance while maintaining relatively low computational costs. Extensive experiments on seven real-world datasets demonstrate the superiority of MoU. Code is available at https://github.com/lunaaa95/mou/.