Simultaneous Training of First- and Second-Order Optimizers in Population-Based Reinforcement Learning
作者: Felix Pfeiffer, Shahram Eivazi
分类: cs.LG, cs.AI
发布日期: 2024-08-27 (更新: 2024-09-04)
备注: 8 pages, 5 figures
💡 一句话要点
提出在基于种群的强化学习中同时训练一阶和二阶优化器的方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 超参数优化 基于种群的训练 二阶优化器 K-FAC TD3 MuJoCo
📋 核心要点
- 强化学习中超参数调整困难,严重影响智能体性能和学习效率,动态调整超参数是关键。
- 论文提出在PBT框架下,同时使用一阶和二阶优化器,使模型能适应不同学习阶段,加速收敛。
- 实验结果表明,K-FAC与Adam结合的PBT方法,在MuJoCo环境中相比仅使用Adam的PBT,性能提升高达10%。
📝 摘要(中文)
强化学习(RL)中超参数的调整至关重要,因为这些参数会显著影响智能体的性能和学习效率。在训练过程中动态调整超参数可以显著提高学习的性能和稳定性。基于种群的训练(PBT)提供了一种通过在整个训练过程中不断调整超参数来实现这一目标的方法。这种持续的调整使模型能够适应不同的学习阶段,从而加快收敛速度并全面提高性能。本文提出了一种对PBT的改进方法,即在单个种群中同时利用一阶和二阶优化器。我们使用TD3算法在各种MuJoCo环境中进行了一系列实验。我们的结果首次从经验上证明了在基于PBT的RL中结合二阶优化器的潜力。具体而言,K-FAC优化器与Adam的结合相比于仅使用Adam的PBT,整体性能提高了10%。此外,在Adam偶尔会失败的环境中,例如Swimmer环境,具有K-FAC的混合种群表现出更可靠的学习结果,在没有显著增加计算时间的情况下,提供了训练稳定性的显著优势。
🔬 方法详解
问题定义:论文旨在解决强化学习中超参数优化的问题。传统方法依赖手动调整或网格搜索,效率低下且难以适应训练过程中的动态变化。现有基于种群的训练方法(PBT)虽然能动态调整超参数,但通常只使用一阶优化器,限制了优化效率和稳定性,尤其是在复杂环境中。
核心思路:论文的核心思路是在PBT框架内,引入二阶优化器与一阶优化器混合的种群。二阶优化器如K-FAC,能够更准确地估计梯度信息,加速收敛并提高稳定性。通过在种群中同时存在一阶和二阶优化器,可以兼顾计算效率和优化性能,使智能体在不同学习阶段选择更合适的优化策略。
技术框架:整体框架仍然是PBT,包含以下主要阶段:1)初始化:随机初始化一个包含多个智能体的种群,每个智能体具有不同的超参数配置,种群中既包含使用Adam优化器的智能体,也包含使用K-FAC优化器的智能体。2)训练:每个智能体在环境中独立训练一段时间。3)评估:评估每个智能体的性能。4)选择:根据性能选择表现较好的智能体。5)探索与利用:表现较差的智能体复制表现较好的智能体的超参数和权重,并进行小幅度的扰动(探索),以寻找更优的超参数配置。这个过程迭代进行,直到达到训练目标。
关键创新:最重要的创新点是在PBT框架中引入了二阶优化器,并与一阶优化器混合使用。这打破了传统PBT只使用一阶优化器的局限,充分利用了二阶优化器在优化复杂问题时的优势。通过种群的多样性,算法能够自适应地选择合适的优化策略,从而提高学习效率和稳定性。这是首次在PBT中成功应用二阶优化器的实证研究。
关键设计:论文使用TD3算法作为基础强化学习算法,并在MuJoCo环境中进行实验。种群大小、训练迭代次数等参数根据具体环境进行调整。关键在于如何平衡种群中一阶和二阶优化器的比例,以及如何设计探索策略,以保证种群的多样性和优化效率。论文中具体参数设置未知。
🖼️ 关键图片

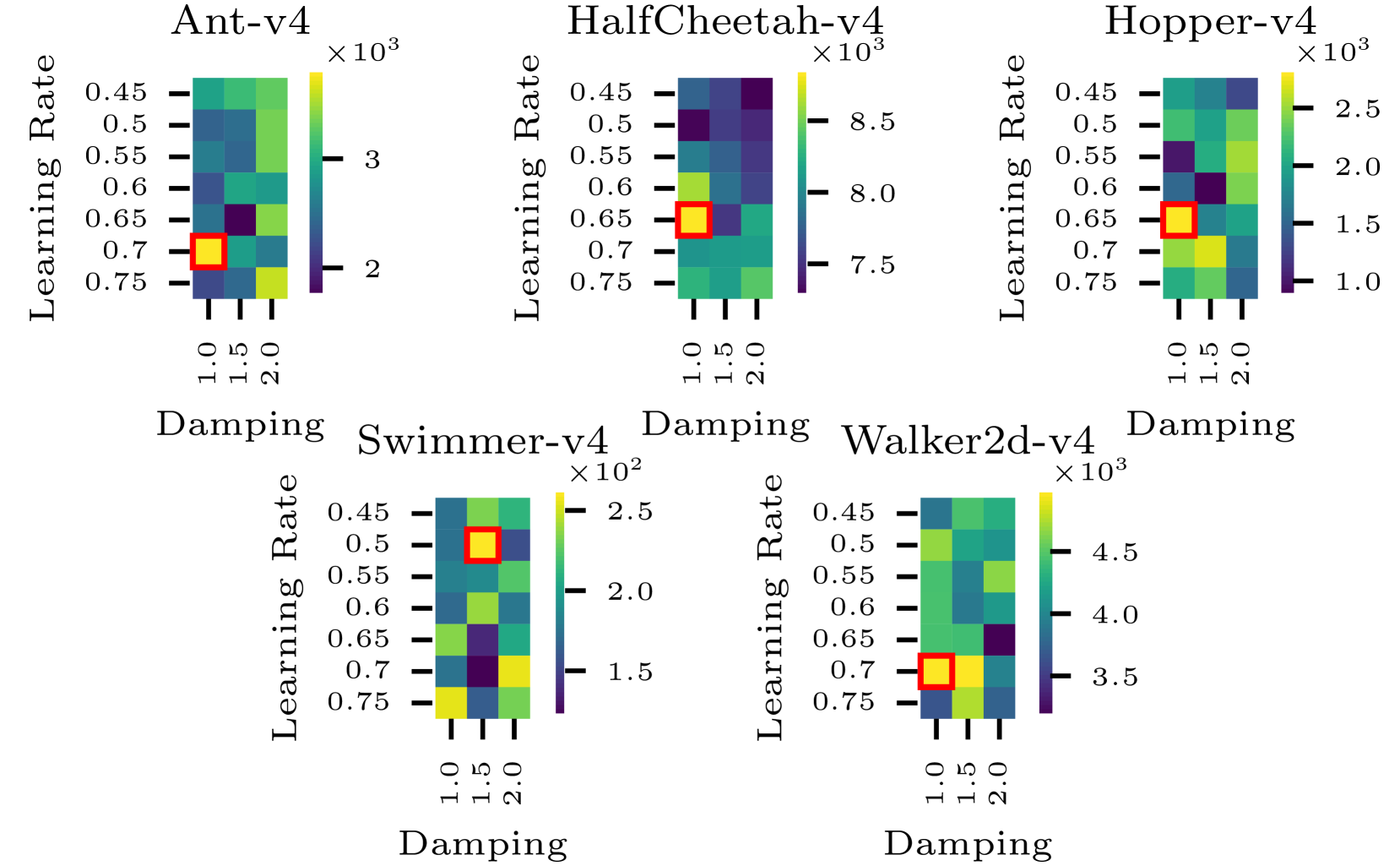

📊 实验亮点
实验结果表明,在MuJoCo环境中,K-FAC与Adam结合的PBT方法相比于仅使用Adam的PBT,整体性能提升高达10%。尤其是在Adam优化器容易失效的Swimmer环境中,混合种群表现出更稳定的学习效果。该方法在提升性能的同时,并未显著增加计算时间,具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于机器人控制、游戏AI、自动驾驶等领域。通过动态调整超参数和优化器,可以显著提高智能体的学习效率和鲁棒性,使其能够更好地适应复杂多变的环境。未来,该方法有望应用于更复杂的强化学习任务,例如多智能体协作、元学习等。
📄 摘要(原文)
The tuning of hyperparameters in reinforcement learning (RL) is critical, as these parameters significantly impact an agent's performance and learning efficiency. Dynamic adjustment of hyperparameters during the training process can significantly enhance both the performance and stability of learning. Population-based training (PBT) provides a method to achieve this by continuously tuning hyperparameters throughout the training. This ongoing adjustment enables models to adapt to different learning stages, resulting in faster convergence and overall improved performance. In this paper, we propose an enhancement to PBT by simultaneously utilizing both first- and second-order optimizers within a single population. We conducted a series of experiments using the TD3 algorithm across various MuJoCo environments. Our results, for the first time, empirically demonstrate the potential of incorporating second-order optimizers within PBT-based RL. Specifically, the combination of the K-FAC optimizer with Adam led to up to a 10% improvement in overall performance compared to PBT using only Adam. Additionally, in environments where Adam occasionally fails, such as the Swimmer environment, the mixed population with K-FAC exhibited more reliable learning outcomes, offering a significant advantage in training stability without a substantial increase in computational time.