GIFT-SW: Gaussian noise Injected Fine-Tuning of Salient Weights for LLMs
作者: Maxim Zhelnin, Viktor Moskvoretskii, Egor Shvetsov, Egor Venediktov, Mariya Krylova, Aleksandr Zuev, Evgeny Burnaev
分类: cs.LG, cs.AI
发布日期: 2024-08-27
💡 一句话要点
GIFT-SW:通过高斯噪声注入微调LLM显著权重,实现高效参数微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 显著权重 高斯噪声注入 大型语言模型 LLaMA 模型量化 敏感性分析
📋 核心要点
- 现有PEFT方法虽然有效,但未充分利用LLM中权重的重要性差异,导致计算资源浪费。
- GIFT-SW通过识别并仅微调显著权重列,同时对非显著权重列注入噪声,实现更高效的参数更新。
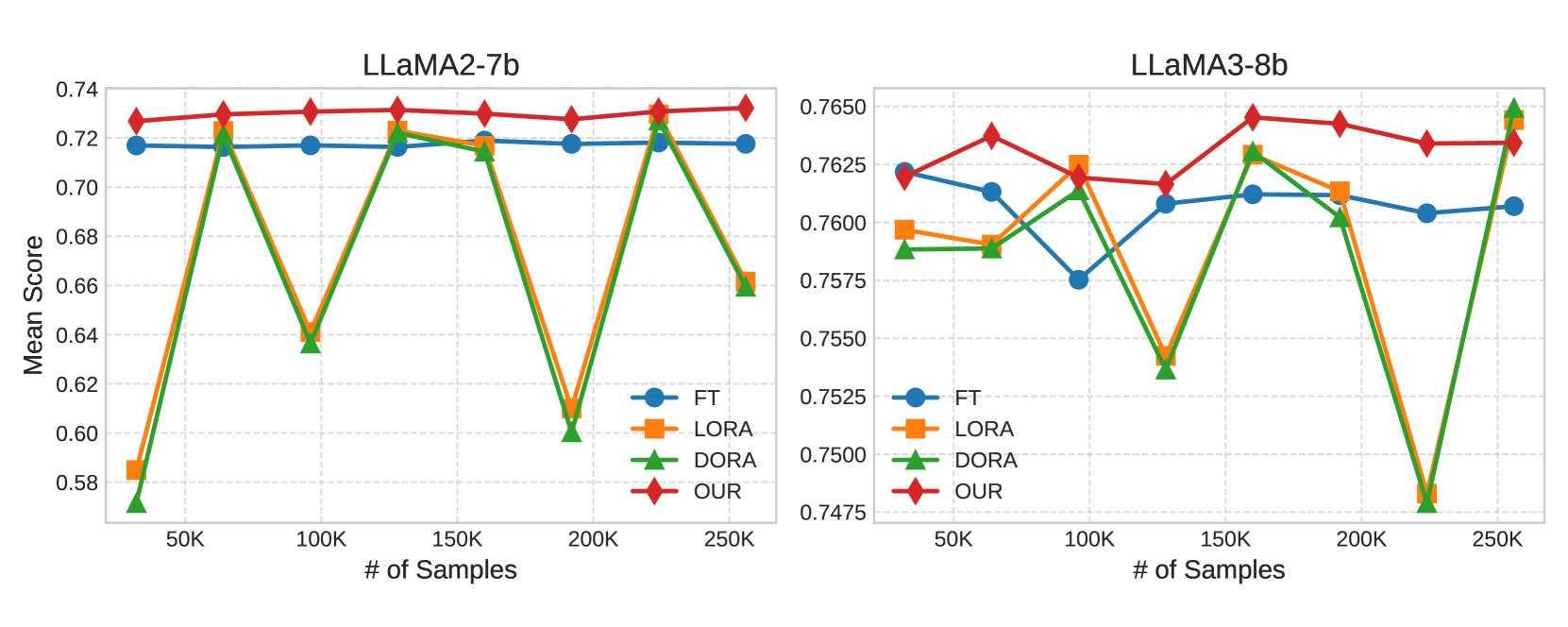
- 实验表明,GIFT-SW在相同计算预算下优于全量微调和现有PEFT方法,并能有效恢复量化模型的性能。
📝 摘要(中文)
参数高效微调(PEFT)方法因其普及性和降低大型语言模型(LLM)的使用门槛而备受欢迎。最近的研究表明,一小部分权重对性能有显著影响。基于此,我们提出了一种新的PEFT方法,称为显著权重高斯噪声注入微调(GIFT-SW)。我们的方法仅更新显著的列,同时向非显著的列注入高斯噪声。为了识别这些列,我们开发了一种广义的敏感性度量,该度量扩展并统一了先前研究中的度量。对LLaMA模型的实验表明,在相同的计算预算下,GIFT-SW优于完全微调和现代PEFT方法。此外,GIFT-SW提供了实际优势,可以通过保持显著权重为全精度来恢复经过混合精度量化的模型的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)微调过程中参数效率低下的问题。现有方法,包括全量微调和部分参数微调(PEFT),要么计算成本高昂,要么未能充分利用LLM中不同权重的重要性差异,导致资源浪费和性能瓶颈。
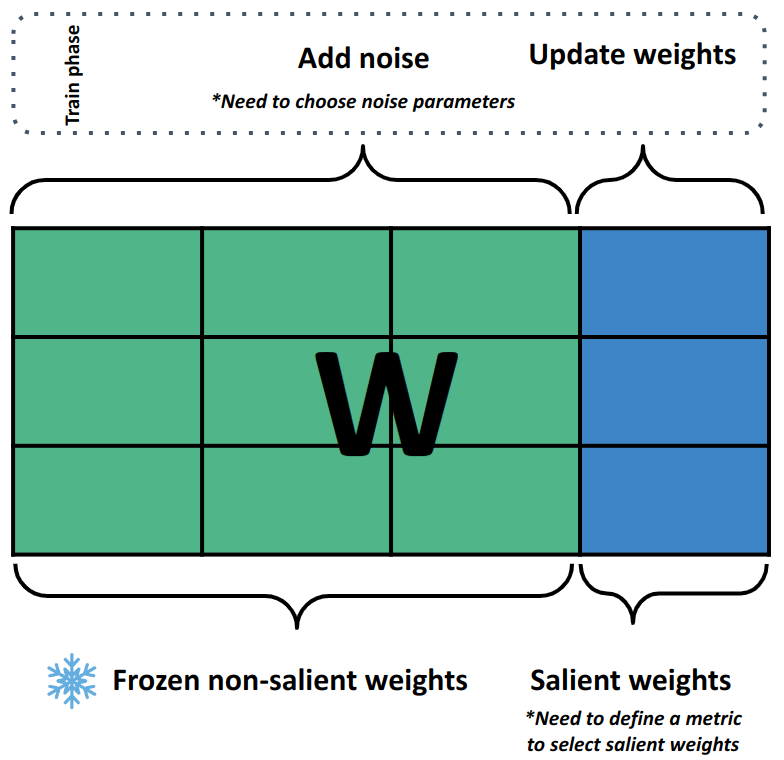
核心思路:论文的核心思路是基于观察到LLM中只有一小部分权重对性能起关键作用。因此,GIFT-SW方法的核心在于识别这些“显著权重”,并只对它们进行微调,同时对不重要的权重注入高斯噪声。这种方法旨在在保持性能的同时,显著减少需要更新的参数数量,从而提高微调效率。
技术框架:GIFT-SW方法主要包含两个阶段:1) 显著权重识别:使用一种广义的敏感性度量来评估每个权重列的重要性。该度量扩展并统一了先前研究中的度量。2) 参数更新:仅更新显著的权重列,同时向非显著的权重列注入高斯噪声。这种噪声注入可以被视为一种正则化技术,有助于防止模型过拟合。
关键创新:GIFT-SW的关键创新在于其显著权重识别方法和噪声注入策略。广义敏感性度量能够更准确地识别对性能影响最大的权重列。同时,对非显著权重注入高斯噪声,不仅减少了计算量,还起到了正则化的作用,提高了模型的泛化能力。与现有PEFT方法相比,GIFT-SW更加关注权重的重要性差异,并采取了更精细化的微调策略。
关键设计:GIFT-SW的关键设计包括:1) 广义敏感性度量的具体形式,需要根据不同的LLM架构和任务进行调整。2) 高斯噪声的方差和均值的选择,需要通过实验进行优化,以平衡正则化效果和性能损失。3) 显著权重列的数量,需要根据计算预算和性能要求进行权衡。论文中可能提供了这些参数的具体设置和选择策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GIFT-SW在LLaMA模型上优于全量微调和现有PEFT方法。在相同计算预算下,GIFT-SW能够达到更高的性能水平。此外,GIFT-SW还能够有效恢复经过混合精度量化的模型的性能,使其在实际应用中更具优势。
🎯 应用场景
GIFT-SW可应用于各种需要高效微调LLM的场景,例如资源受限的边缘设备、快速模型迭代开发以及对量化模型进行性能恢复。该方法能够降低微调成本,加速模型部署,并提升量化模型的实用性,具有广泛的应用前景。
📄 摘要(原文)
Parameter Efficient Fine-Tuning (PEFT) methods have gained popularity and democratized the usage of Large Language Models (LLMs). Recent studies have shown that a small subset of weights significantly impacts performance. Based on this observation, we introduce a novel PEFT method, called Gaussian noise Injected Fine Tuning of Salient Weights (GIFT-SW). Our method updates only salient columns, while injecting Gaussian noise into non-salient ones. To identify these columns, we developeda generalized sensitivity metric that extends and unifies metrics from previous studies. Experiments with LLaMA models demonstrate that GIFT-SW outperforms full fine-tuning and modern PEFT methods under the same computational budget. Moreover, GIFT-SW offers practical advantages to recover performance of models subjected to mixed-precision quantization with keeping salient weights in full precision.