Condensed Data Expansion Using Model Inversion for Knowledge Distillation
作者: Kuluhan Binici, Shivam Aggarwal, Cihan Acar, Nam Trung Pham, Karianto Leman, Gim Hee Lee, Tulika Mitra
分类: cs.LG, cs.AI
发布日期: 2024-08-25 (更新: 2025-11-10)
备注: Accepted by the Fortieth AAAI Conference on Artificial Intelligence (AAAI-26)
💡 一句话要点
提出基于模型反演的精简数据扩展方法,提升知识蒸馏性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型反演 精简数据集 数据扩展 合成数据
📋 核心要点
- 直接在精简数据集上进行训练或知识蒸馏,由于信息不足,效果往往不佳。
- 利用预训练教师模型的知识,通过模型反演生成合成数据,扩展精简数据集。
- 实验表明,该方法显著提升了知识蒸馏的准确性,尤其是在数据稀缺的情况下。
📝 摘要(中文)
精简数据集能够紧凑地表示大型数据集,但直接在其上训练模型或通过知识蒸馏(KD)来提升模型性能,由于信息有限,可能导致次优结果。为了解决这个问题,我们提出了一种使用模型反演来扩展精简数据集的方法。模型反演是一种基于预训练模型在其训练数据上的“印象”来生成合成数据的技术。这种方法特别适用于KD场景,因为教师模型已经预训练并保留了原始训练数据的知识。通过创建补充精简样本的合成数据,我们丰富了训练集,更好地近似了底层数据分布,从而提高了知识蒸馏期间学生模型的准确性。我们的方法在KD准确性方面表现出显著的提升,与单独使用精简数据集相比,优于标准的基于模型反演的KD方法高达11.4%,适用于各种数据集和模型架构。重要的是,即使每个类别只使用一个精简样本,它仍然有效,并且还可以提高仅有有限的真实数据样本可用的few-shot场景中的性能。
🔬 方法详解
问题定义:论文旨在解决在知识蒸馏中,直接使用精简数据集训练学生模型时,由于信息量不足导致的性能瓶颈问题。现有的知识蒸馏方法通常依赖于完整的训练数据集,但在某些场景下,只能获取到原始数据集的精简版本,这限制了学生模型的学习能力。
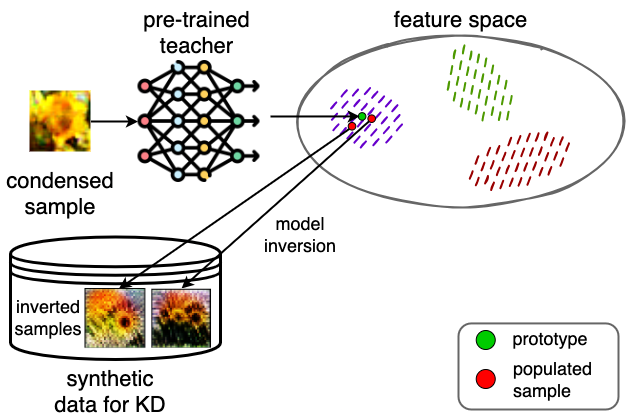
核心思路:论文的核心思路是利用预训练的教师模型,通过模型反演技术生成与精简数据集互补的合成数据,从而扩展训练集。由于教师模型已经学习了原始数据集的知识,因此生成的合成数据能够更好地代表原始数据分布,弥补精简数据集的信息缺失。
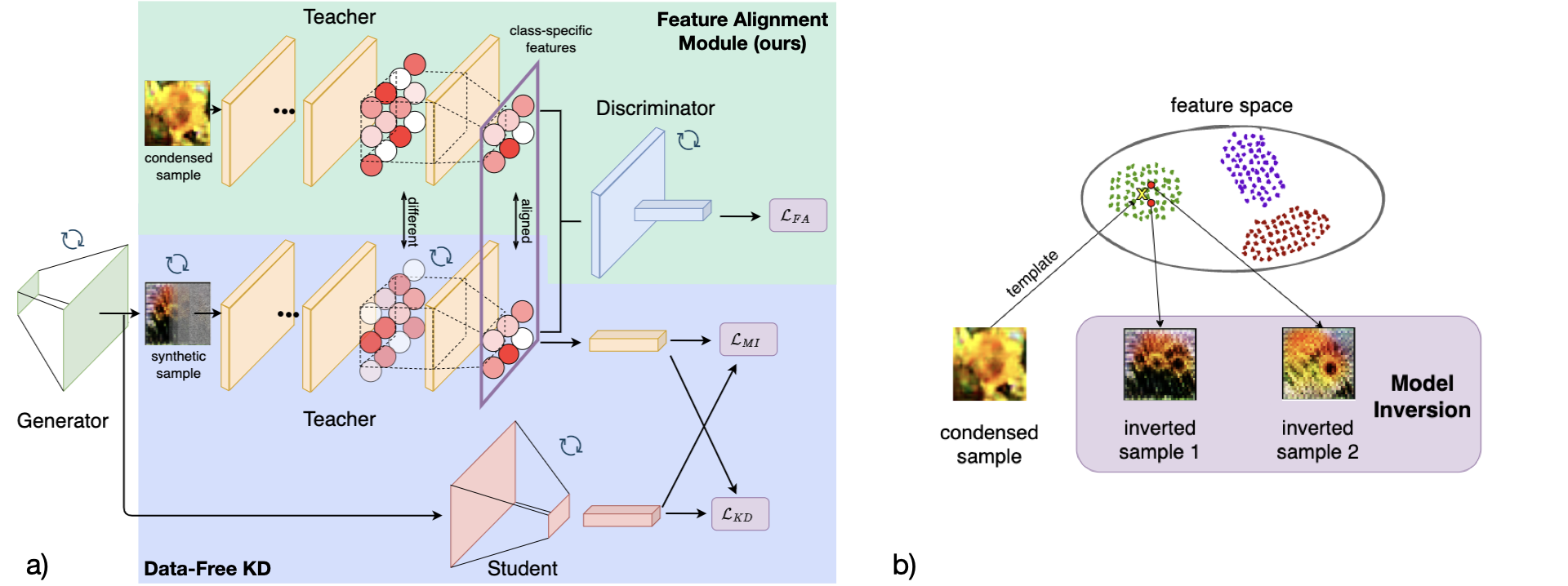
技术框架:该方法主要包含以下几个阶段:1) 使用原始数据集训练教师模型;2) 从原始数据集中提取精简数据集;3) 使用教师模型对精简数据集进行模型反演,生成合成数据;4) 将精简数据集和合成数据合并,作为学生模型的训练集,并使用知识蒸馏技术训练学生模型。
关键创新:该方法最重要的创新点在于将模型反演技术应用于精简数据集的扩展,并将其与知识蒸馏相结合。与传统的基于模型反演的知识蒸馏方法不同,该方法不是直接使用模型反演生成整个训练集,而是只生成补充精简数据集的合成数据,从而在保证性能的同时,降低了计算成本。
关键设计:论文中可能涉及的关键设计包括:1) 模型反演的具体方法,例如使用梯度反演或生成对抗网络;2) 精简数据集的选取策略,例如基于聚类或重要性采样;3) 知识蒸馏的损失函数,例如使用KL散度或Hinton损失;4) 教师模型和学生模型的网络结构选择。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在知识蒸馏的准确性方面取得了显著的提升,与单独使用精简数据集相比,性能提升高达11.4%。即使每个类别只使用一个精简样本,该方法仍然有效,并且在few-shot场景下也能提高性能。该方法在多个数据集和模型架构上都表现出良好的泛化能力。
🎯 应用场景
该研究成果可应用于数据隐私保护、模型压缩和加速等领域。例如,在数据隐私保护场景下,可以使用精简数据集和模型反演技术生成合成数据,用于训练模型,而无需访问原始敏感数据。在模型压缩和加速场景下,可以使用精简数据集和知识蒸馏技术,将大型模型的知识迁移到小型模型,从而降低模型的计算复杂度和存储空间。
📄 摘要(原文)
Condensed datasets offer a compact representation of larger datasets, but training models directly on them or using them to enhance model performance through knowledge distillation (KD) can result in suboptimal outcomes due to limited information. To address this, we propose a method that expands condensed datasets using model inversion, a technique for generating synthetic data based on the impressions of a pre-trained model on its training data. This approach is particularly well-suited for KD scenarios, as the teacher model is already pre-trained and retains knowledge of the original training data. By creating synthetic data that complements the condensed samples, we enrich the training set and better approximate the underlying data distribution, leading to improvements in student model accuracy during knowledge distillation. Our method demonstrates significant gains in KD accuracy compared to using condensed datasets alone and outperforms standard model inversion-based KD methods by up to 11.4% across various datasets and model architectures. Importantly, it remains effective even when using as few as one condensed sample per class, and can also enhance performance in few-shot scenarios where only limited real data samples are available.