A Law of Next-Token Prediction in Large Language Models
作者: Hangfeng He, Weijie J. Su
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2024-08-24 (更新: 2025-08-31)
备注: Transferred for publication to Physical Review E from Physical Review Research (to waive publication charges)
💡 一句话要点
揭示大语言模型中token预测的普适定律:层间贡献均等
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 下一token预测 模型可解释性 层间贡献 token嵌入
📋 核心要点
- 大型语言模型内部运作机制复杂,理解其预测过程面临黑盒挑战。
- 论文揭示了LLM中token嵌入学习的定量规律,即每一层对预测准确性的贡献均等。
- 该规律在多种LLM中普遍存在,为模型开发和应用提供了新的指导方向。
📝 摘要(中文)
大型语言模型(LLM)已被广泛应用于各个领域,但其黑盒特性给理解模型如何内部处理输入数据以进行预测带来了重大挑战。本文介绍了一个精确且定量的定律,该定律支配了预训练LLM中上下文token嵌入通过中间层进行下一token预测的学习过程。我们的研究结果表明,从最低层到最高层,每一层都对提高预测准确性做出同等贡献——这是一种在各种开源LLM中观察到的普遍现象,与其架构或预训练数据无关。我们证明,该定律为LLM开发和应用(包括模型缩放、预训练任务和可解释性)中的实践提供了新的视角和可操作的见解。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在各种应用中表现出色,但其内部运作机制仍然像一个黑盒子。理解LLM如何处理输入数据并进行预测是一个重要的研究问题。现有的方法往往难以精确量化模型内部各层对最终预测结果的贡献,缺乏对模型行为的深入理解。
核心思路:本文的核心思路是发现并量化LLM中token嵌入学习的规律。作者假设LLM的每一层都对预测结果有贡献,并通过实验验证了这一假设。更重要的是,他们发现这种贡献是均等的,即每一层对提高预测准确性的贡献大致相同。这种均等贡献的规律为理解LLM的内部运作提供了一个新的视角。
技术框架:该研究主要通过实验分析预训练的LLM。具体来说,作者选取了多种开源LLM,包括不同架构和不同预训练数据的模型。然后,他们分析了这些模型在进行下一token预测时,每一层对预测准确性的贡献。通过量化每一层的贡献,作者验证了层间贡献均等的规律。
关键创新:本文最重要的技术创新在于发现了LLM中token预测的普适定律,即层间贡献均等。这一发现颠覆了以往对LLM内部运作的认知,为模型开发和应用提供了新的指导。与现有方法相比,该研究提供了一种精确且定量的分析方法,能够更深入地理解LLM的行为。
关键设计:研究中关键的设计在于如何量化每一层对预测准确性的贡献。具体来说,作者可能采用了某种指标来衡量每一层输出的token嵌入的质量,并将其与最终的预测结果进行关联。此外,作者可能还设计了一系列实验来验证层间贡献均等的规律在不同模型和不同数据集上的普适性。具体的参数设置、损失函数和网络结构等细节可能因不同的LLM而异,但核心的实验方法和分析框架是相同的。
🖼️ 关键图片
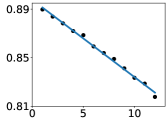
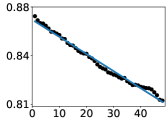
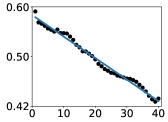
📊 实验亮点
研究发现,在多种开源LLM中,从最低层到最高层,每一层都对提高预测准确性做出同等贡献。这一规律与模型的架构和预训练数据无关,具有普遍性。该发现为理解LLM的内部运作提供了一个新的视角,并为模型开发和应用提供了新的指导。
🎯 应用场景
该研究成果可应用于指导LLM的模型缩放,优化预训练任务,并提升模型的可解释性。例如,在模型缩放时,可以根据层间贡献均等的规律,合理分配计算资源。在预训练任务设计时,可以更有针对性地训练模型的不同层次。此外,该研究还有助于开发更易于理解和调试的LLM。
📄 摘要(原文)
Large language models (LLMs) have been widely employed across various application domains, yet their black-box nature poses significant challenges to understanding how these models process input data internally to make predictions. In this paper, we introduce a precise and quantitative law that governs the learning of contextualized token embeddings through intermediate layers in pre-trained LLMs for next-token prediction. Our findings reveal that each layer contributes equally to enhancing prediction accuracy, from the lowest to the highest layer -- a universal phenomenon observed across a diverse array of open-source LLMs, irrespective of their architectures or pre-training data. We demonstrate that this law offers new perspectives and actionable insights to inform and guide practices in LLM development and applications, including model scaling, pre-training tasks, and interpretation.