The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities
作者: Venkatesh Balavadhani Parthasarathy, Ahtsham Zafar, Aafaq Khan, Arsalan Shahid
分类: cs.LG, cs.CL
发布日期: 2024-08-23 (更新: 2024-10-30)
💡 一句话要点
LLM微调终极指南:从基础到突破的技术、研究、实践与挑战全面综述
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 参数高效微调 人类偏好对齐 自然语言处理
📋 核心要点
- 现有LLM微调方法在计算效率、数据不平衡和对齐人类偏好方面存在挑战,限制了其在资源受限场景和特定任务中的应用。
- 该综述旨在提供一个全面的LLM微调指南,涵盖从基础理论到前沿技术的各个方面,并强调实际应用中的挑战和机遇。
- 报告总结了各种微调方法、优化技术和部署策略,为研究人员和从业人员提供了在LLM微调领域取得突破性进展的实用指导。
📝 摘要(中文)
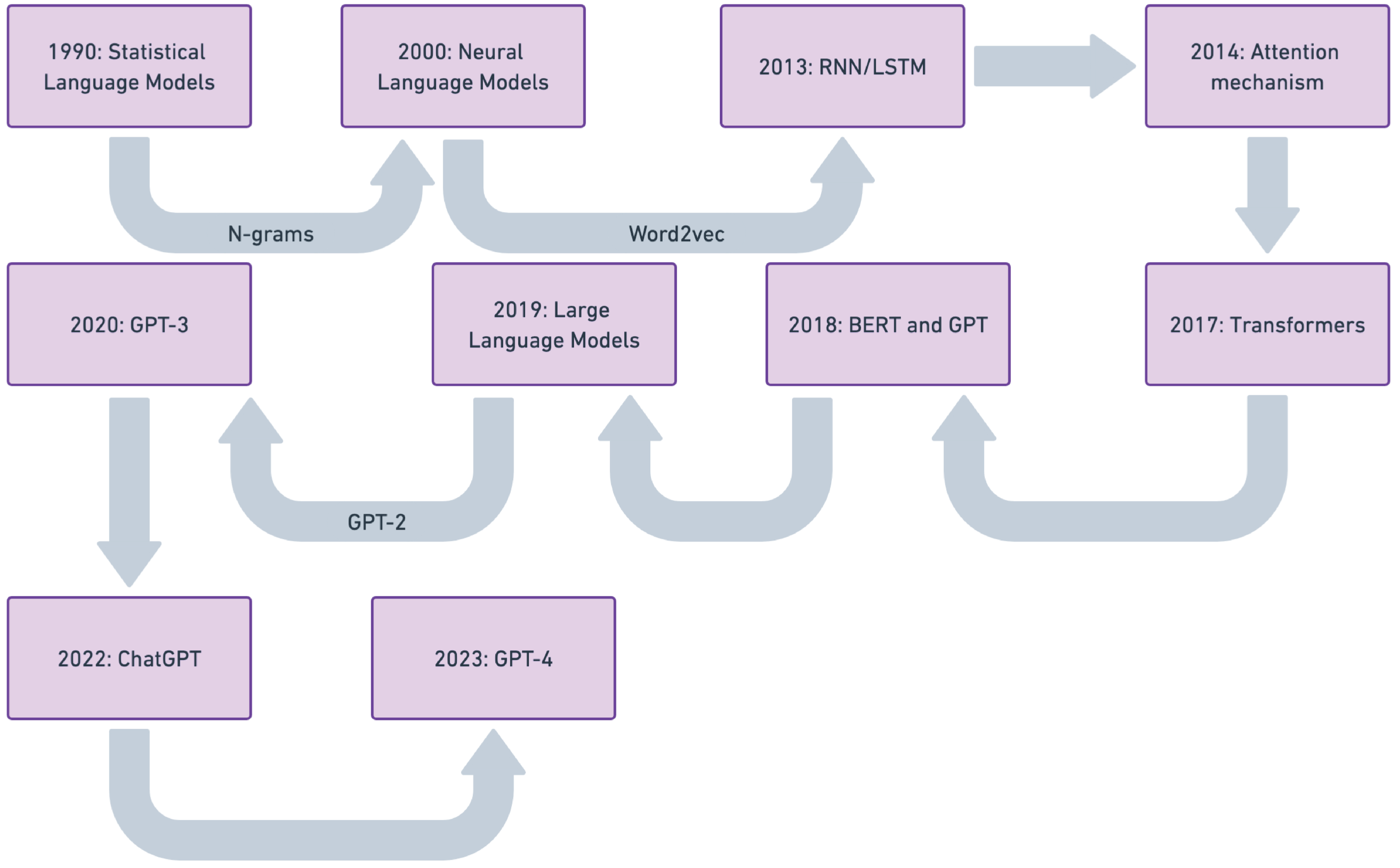
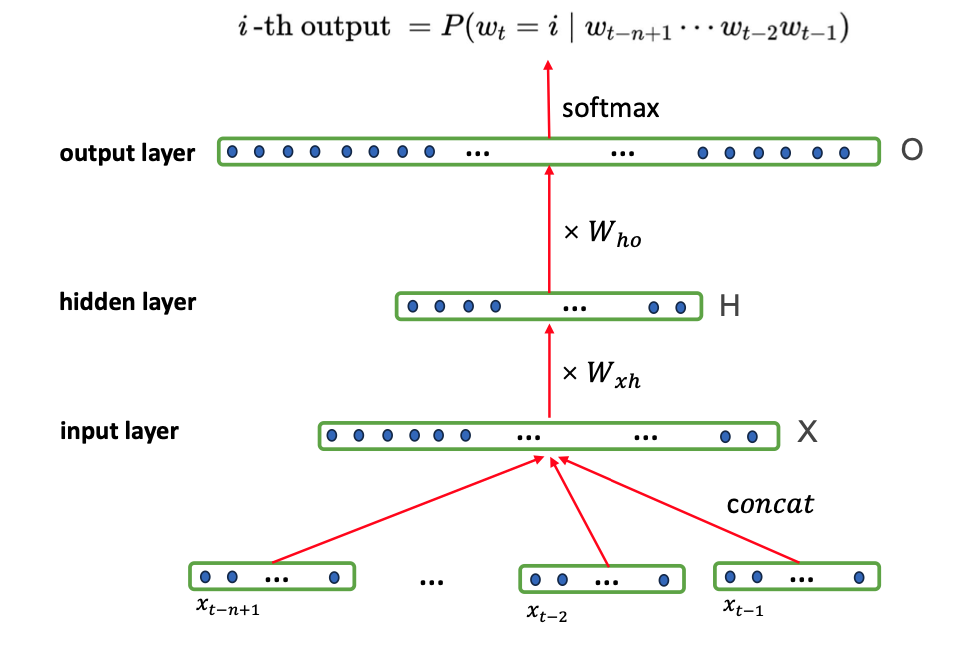
本报告探讨了大型语言模型(LLM)的微调,融合了理论见解与实际应用。报告概述了LLM从传统自然语言处理(NLP)模型到其在人工智能中关键作用的历史演变。对监督、无监督和基于指令的方法等微调方法进行了比较,突出了它们对不同任务的适用性。报告介绍了一个结构化的七阶段LLM微调流程,涵盖数据准备、模型初始化、超参数调整和模型部署。重点介绍了管理不平衡数据集和优化技术。探索了低秩适应(LoRA)和半精度微调等参数高效方法,以平衡计算效率和性能。讨论了内存微调、专家混合(MoE)和代理混合(MoA)等高级技术,以利用专用网络和多代理协作。报告还研究了近端策略优化(PPO)和直接偏好优化(DPO)等新方法,这些方法使LLM与人类偏好保持一致,以及剪枝和路由优化以提高效率。进一步的章节涵盖验证框架、部署后监控和推理优化,并关注在分布式和基于云的平台上部署LLM。还讨论了多模态LLM、音频和语音微调等新兴领域,以及与可扩展性、隐私和问责制相关的挑战。本报告为研究人员和从业人员在不断发展的环境中进行LLM微调提供了可操作的见解。
🔬 方法详解
问题定义:现有LLM微调方法面临诸多挑战。首先,全参数微调计算成本高昂,难以在资源有限的场景下应用。其次,数据不平衡问题会导致模型在少数类别上表现良好,而在多数类别上表现不佳。此外,如何使LLM的输出与人类偏好对齐也是一个重要难题,传统的监督学习方法难以捕捉人类的细微偏好。
核心思路:本综述的核心思路是系统性地梳理LLM微调的各个方面,从基础理论到前沿技术,从数据准备到模型部署,为研究人员和从业人员提供一个全面的参考框架。通过对比不同微调方法的优缺点,分析各种优化技术的适用场景,并探讨新兴领域的发展趋势,旨在帮助读者更好地理解LLM微调的本质,并找到解决实际问题的有效方法。
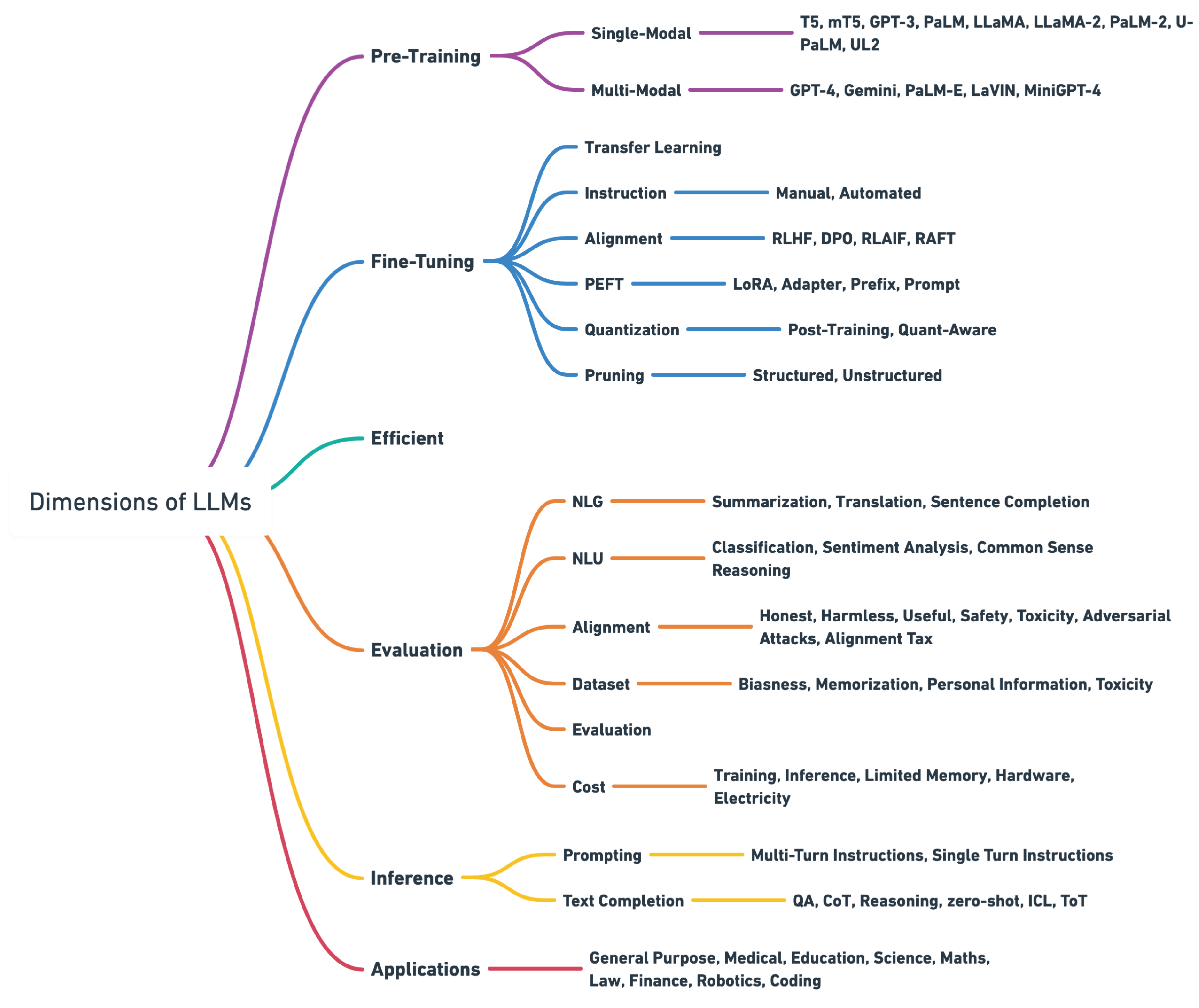
技术框架:该综述报告构建了一个七阶段的LLM微调流程,包括:1. 数据准备:清洗、标注和增强数据;2. 模型初始化:选择合适的预训练模型;3. 微调方法选择:根据任务选择监督、无监督或指令微调;4. 超参数调整:优化学习率、batch size等参数;5. 优化技术应用:解决数据不平衡、提高计算效率;6. 模型部署:选择合适的部署平台;7. 监控与维护:持续监控模型性能并进行维护。此外,报告还深入探讨了参数高效微调、高级微调技术和对齐人类偏好的方法。
关键创新:本综述的关键创新在于其全面性和系统性。它不仅涵盖了LLM微调的各个方面,还深入探讨了新兴领域的发展趋势,如多模态LLM、音频和语音微调等。此外,报告还强调了实际应用中的挑战和机遇,为研究人员和从业人员提供了可操作的见解。
关键设计:报告详细介绍了各种微调方法的原理和适用场景,如监督微调、无监督微调和指令微调。对于参数高效微调,报告重点介绍了LoRA和半精度微调等方法。对于对齐人类偏好,报告探讨了PPO和DPO等方法。此外,报告还讨论了剪枝和路由优化等技术,以提高LLM的效率。
🖼️ 关键图片
📊 实验亮点
该综述全面总结了LLM微调的各种技术,并对不同方法进行了对比分析。特别地,报告深入探讨了参数高效微调方法(如LoRA)和对齐人类偏好的方法(如DPO),为研究人员提供了宝贵的参考。此外,报告还关注了新兴领域的发展趋势,如多模态LLM和音频/语音微调。
🎯 应用场景
该研究成果对自然语言处理、智能客服、内容生成、教育、医疗等领域具有广泛的应用前景。通过高效微调LLM,可以降低模型部署成本,提高模型在特定任务上的性能,并使模型更好地服务于人类社会。未来,该研究将推动LLM在更多实际场景中的应用,并促进人工智能技术的普及。
📄 摘要(原文)
This report examines the fine-tuning of Large Language Models (LLMs), integrating theoretical insights with practical applications. It outlines the historical evolution of LLMs from traditional Natural Language Processing (NLP) models to their pivotal role in AI. A comparison of fine-tuning methodologies, including supervised, unsupervised, and instruction-based approaches, highlights their applicability to different tasks. The report introduces a structured seven-stage pipeline for fine-tuning LLMs, spanning data preparation, model initialization, hyperparameter tuning, and model deployment. Emphasis is placed on managing imbalanced datasets and optimization techniques. Parameter-efficient methods like Low-Rank Adaptation (LoRA) and Half Fine-Tuning are explored for balancing computational efficiency with performance. Advanced techniques such as memory fine-tuning, Mixture of Experts (MoE), and Mixture of Agents (MoA) are discussed for leveraging specialized networks and multi-agent collaboration. The report also examines novel approaches like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), which align LLMs with human preferences, alongside pruning and routing optimizations to improve efficiency. Further sections cover validation frameworks, post-deployment monitoring, and inference optimization, with attention to deploying LLMs on distributed and cloud-based platforms. Emerging areas such as multimodal LLMs, fine-tuning for audio and speech, and challenges related to scalability, privacy, and accountability are also addressed. This report offers actionable insights for researchers and practitioners navigating LLM fine-tuning in an evolving landscape.