Critique-out-Loud Reward Models
作者: Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, Prithviraj Ammanabrolu
分类: cs.LG
发布日期: 2024-08-21
💡 一句话要点
提出Critique-out-Loud奖励模型,提升LLM在RLHF中的偏好建模能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 强化学习 人类反馈 大型语言模型 偏好建模 自然语言评论 自洽解码
📋 核心要点
- 传统奖励模型在RLHF中隐式推理响应质量,限制了其能力,需要更显式的推理方式。
- CLoud奖励模型通过生成自然语言评论来显式评估响应质量,再预测奖励。
- 实验表明,CLoud模型在偏好分类准确率和胜率上均优于传统奖励模型。
📝 摘要(中文)
传统的奖励模型在基于人类反馈的强化学习(RLHF)中,直接预测偏好得分,而没有利用底层大型语言模型(LLM)的生成能力。这限制了奖励模型的能力,因为它们必须隐式地推理响应的质量,即偏好建模必须在模型的单次前向传递中完成。为了使奖励模型能够显式地推理响应的质量,我们引入了Critique-out-Loud(CLoud)奖励模型。CLoud奖励模型首先生成对助手响应的自然语言评论,然后使用该评论来预测响应质量的标量奖励。我们证明了CLoud奖励模型在Llama-3-8B和70B基础模型上的成功:与经典奖励模型相比,CLoud奖励模型在RewardBench上的成对偏好分类准确率分别提高了4.65和5.84个百分点。此外,当用作Best-of-N的评分模型时,CLoud奖励模型在ArenaHard上的胜率实现了帕累托改进。最后,我们探索了如何通过执行自洽解码进行奖励预测来利用CLoud奖励模型的动态推理计算能力。
🔬 方法详解
问题定义:现有奖励模型在RLHF中直接预测偏好得分,缺乏对生成文本质量的显式推理能力。这种隐式推理限制了模型理解和区分细微偏好的能力,导致奖励信号不够准确,影响后续强化学习的效果。现有方法难以充分利用LLM的生成能力进行更深入的评估。
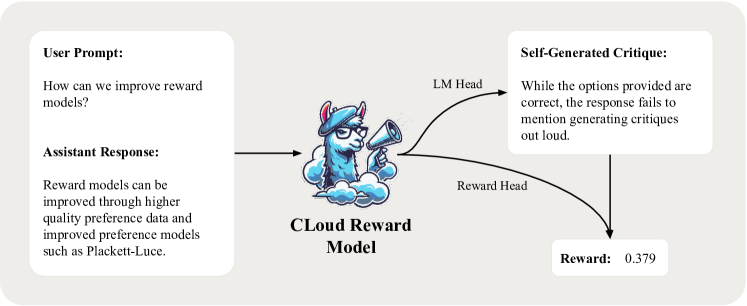
核心思路:CLoud奖励模型的核心思路是让奖励模型首先生成对生成文本的自然语言评论(critique),然后基于该评论预测奖励。通过显式地生成评论,模型可以更深入地分析文本的优点和缺点,从而更准确地评估文本的质量。这种显式推理过程模仿了人类评估文本的方式,有助于提高奖励模型的准确性和可解释性。
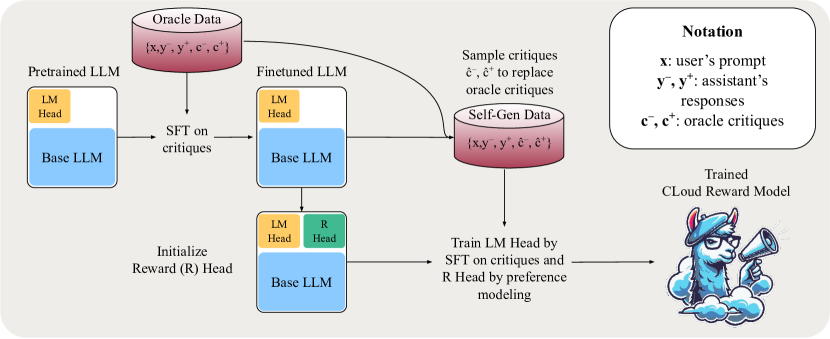
技术框架:CLoud奖励模型包含两个主要阶段:评论生成阶段和奖励预测阶段。在评论生成阶段,模型接收输入文本,并生成一段自然语言评论,描述文本的质量。在奖励预测阶段,模型将输入文本和生成的评论作为输入,预测一个标量奖励值。整体流程可以描述为:输入文本 -> 评论生成 -> 奖励预测。
关键创新:CLoud奖励模型最重要的创新点在于引入了显式的评论生成步骤。与传统奖励模型直接预测奖励不同,CLoud模型首先生成评论,然后基于评论预测奖励。这种显式推理过程使得模型能够更深入地理解文本的质量,从而更准确地评估文本的优劣。此外,该方法允许利用LLM的生成能力进行更细致的评估。
关键设计:CLoud奖励模型可以使用各种LLM作为基础模型,例如Llama-3。评论生成阶段可以使用标准的文本生成技术,例如自回归解码。奖励预测阶段可以使用一个简单的线性层或更复杂的神经网络。论文还探索了自洽解码(self-consistency decoding)用于奖励预测,以进一步提高奖励的准确性。损失函数通常包括评论生成损失和奖励预测损失,可以使用交叉熵损失或均方误差损失。
🖼️ 关键图片
📊 实验亮点
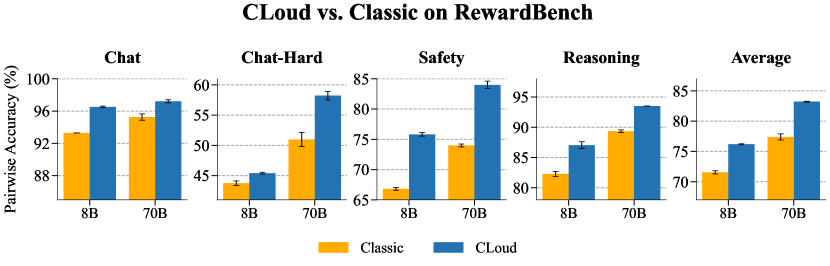
实验结果表明,CLoud奖励模型在RewardBench上的成对偏好分类准确率显著优于传统奖励模型,对于Llama-3-8B和70B基础模型,分别提高了4.65和5.84个百分点。此外,当用作Best-of-N的评分模型时,CLoud奖励模型在ArenaHard上的胜率实现了帕累托改进,表明其在实际应用中具有更好的性能。
🎯 应用场景
CLoud奖励模型可应用于各种需要评估文本质量的场景,例如对话系统、文本摘要、代码生成等。通过提供更准确的奖励信号,可以提升这些系统的性能和用户体验。该方法还有助于提高模型的可解释性,使用户能够理解模型做出决策的原因。未来可应用于更复杂的RLHF任务,例如多轮对话和长期规划。
📄 摘要(原文)
Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.