Mixed Sparsity Training: Achieving 4$\times$ FLOP Reduction for Transformer Pretraining
作者: Pihe Hu, Shaolong Li, Longbo Huang
分类: cs.LG
发布日期: 2024-08-21
💡 一句话要点
提出混合稀疏训练(MST),在Transformer预训练中实现4倍FLOPs降低。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏训练 Transformer 预训练 计算效率 动态稀疏 大型语言模型 混合稀疏注意力
📋 核心要点
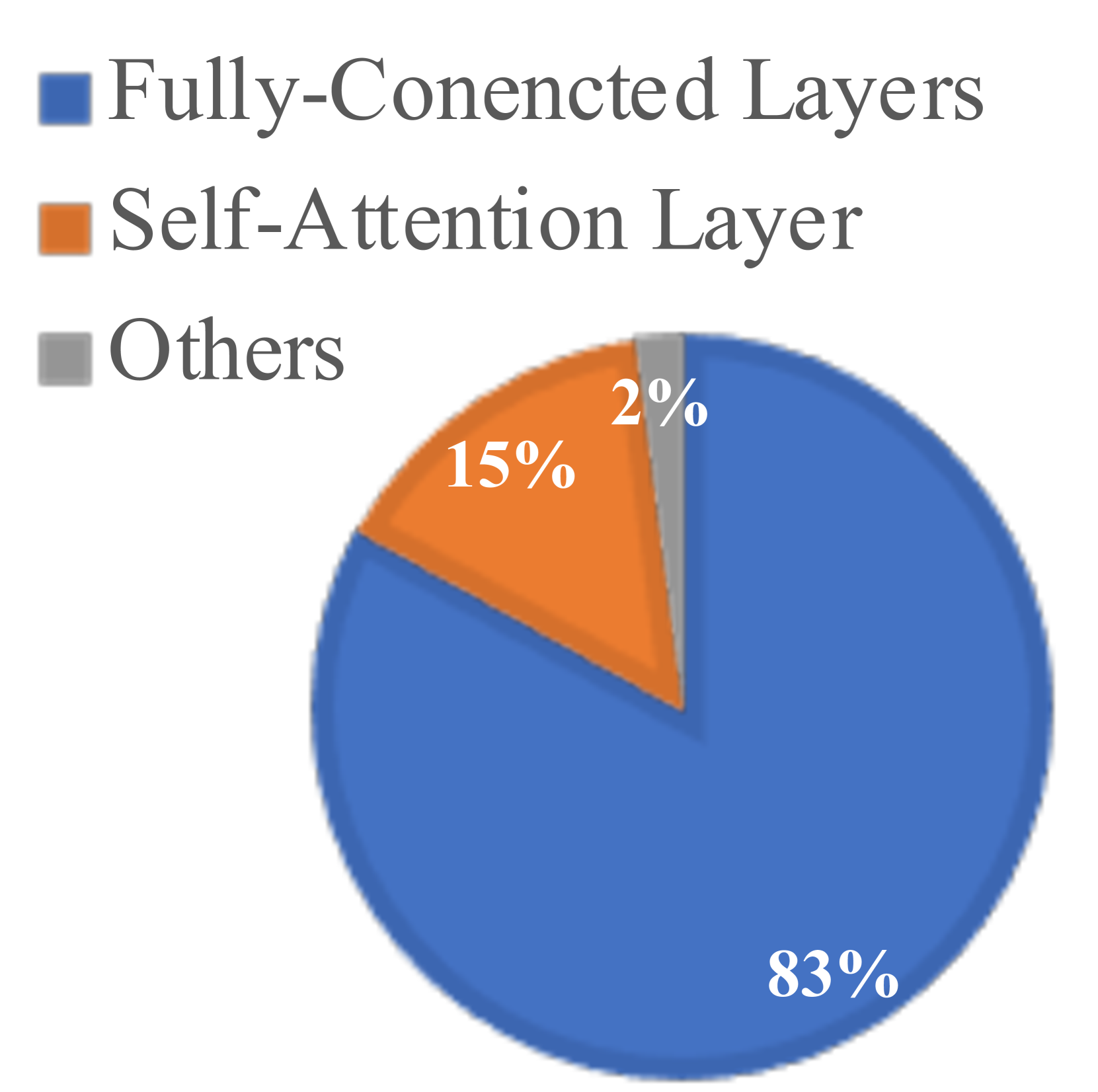
- 大型语言模型预训练计算成本高昂,存在大量冗余计算,阻碍了其广泛应用。
- 提出混合稀疏训练(MST),通过动态稀疏训练、稀疏变异和混合稀疏注意力,在预训练过程中减少计算量。
- 在GPT-2上的实验表明,MST能够在不损失性能的前提下,将FLOPs降低4倍。
📝 摘要(中文)
大型语言模型(LLMs)在复杂任务中取得了显著进展,但其广泛应用受到巨大计算需求的阻碍。基于Transformer的LLM拥有数千亿参数,需要在高端GPU集群上进行数月的预训练。本文揭示了一个引人注目的发现:Transformer的预训练计算中存在大量冗余。为此,我们提出了混合稀疏训练(MST),这是一种高效的预训练方法,可以在保持性能的同时减少约75%的浮点运算(FLOPs)。MST在预训练期间集成了动态稀疏训练(DST)与稀疏变异(SV)和混合稀疏注意力(HSA),包括三个不同的阶段:预热、超稀疏化和恢复。预热阶段将密集模型转换为稀疏模型,恢复阶段恢复连接。在这些阶段中,模型以动态演化的稀疏拓扑和HSA机制进行训练,以保持性能并同时最小化训练FLOPs。我们在GPT-2上的实验表明,在不影响性能的情况下,FLOPs减少了4倍。
🔬 方法详解
问题定义:论文旨在解决大型Transformer模型预训练过程中计算量过大的问题。现有方法通常采用密集计算,忽略了模型中存在的冗余性,导致训练成本居高不下。因此,如何降低预训练的计算复杂度,同时保持模型性能,是本文要解决的核心问题。
核心思路:论文的核心思路是利用稀疏性来减少计算量。通过在训练过程中动态地调整模型的稀疏结构,移除不重要的连接,从而减少FLOPs。同时,为了弥补稀疏化可能带来的性能损失,引入了稀疏变异和混合稀疏注意力机制,以保持模型的表达能力。
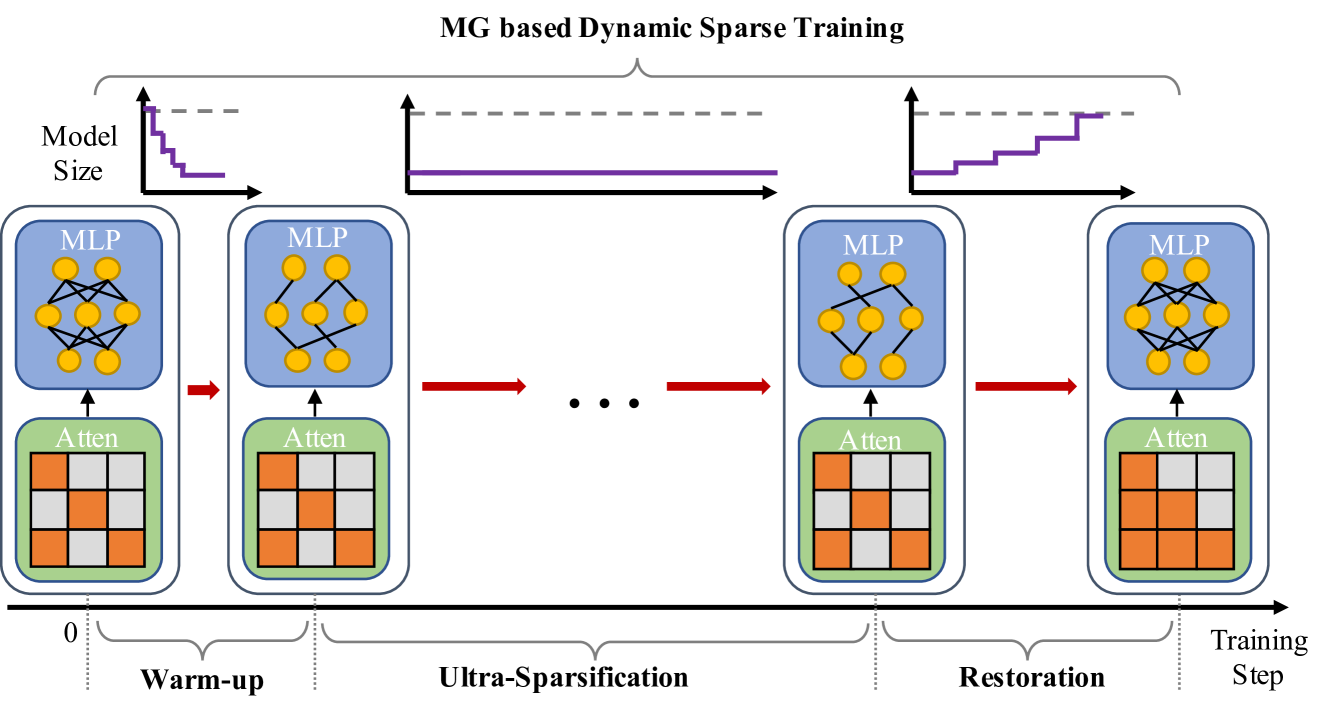
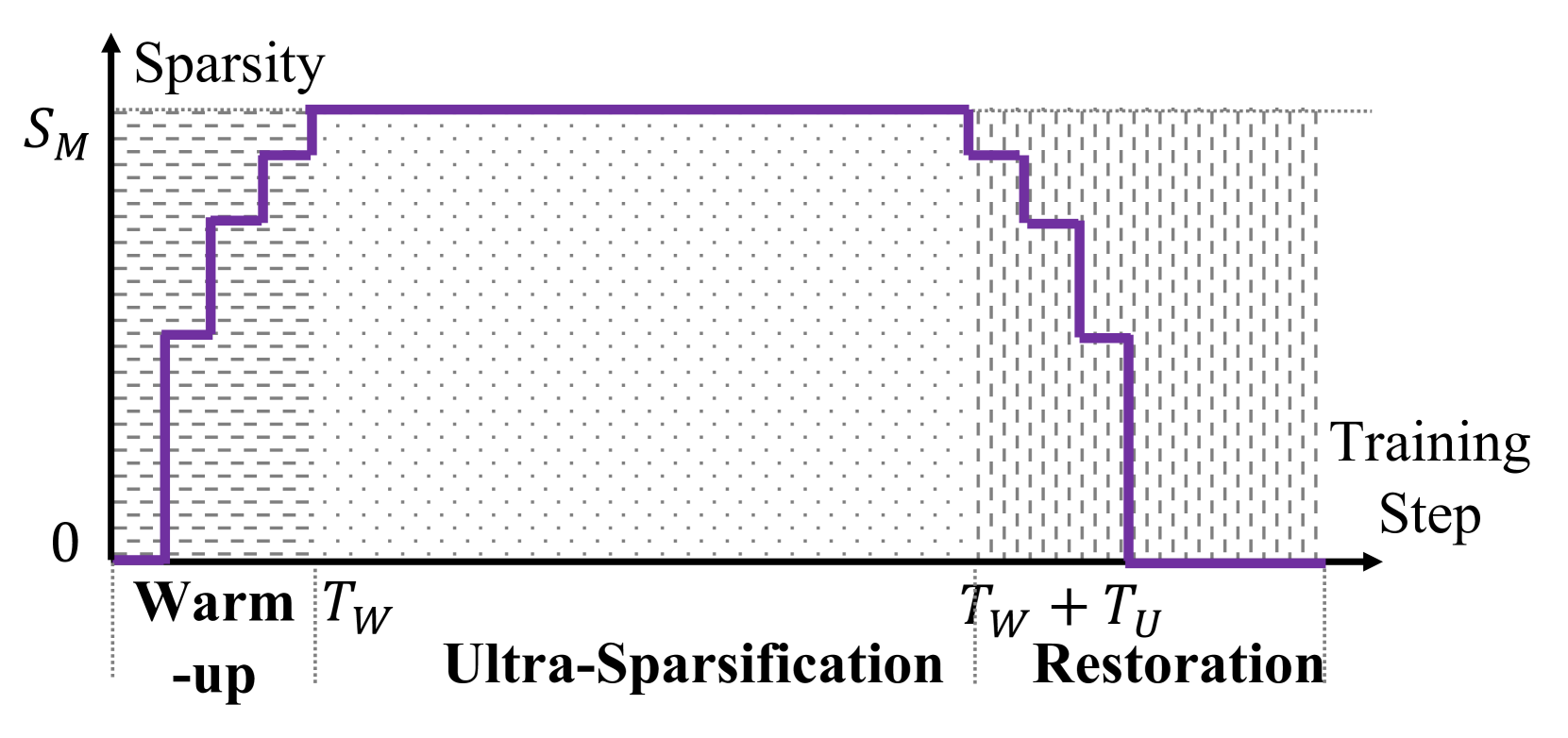
技术框架:MST包含三个主要阶段:预热(Warm-up)、超稀疏化(Ultra-sparsification)和恢复(Restoration)。在预热阶段,将密集模型逐渐稀疏化。超稀疏化阶段进一步增加模型的稀疏度,以最大程度地减少计算量。恢复阶段则重新引入部分连接,以提升模型性能。整个训练过程中,模型采用动态稀疏拓扑和混合稀疏注意力机制。
关键创新:MST的关键创新在于混合使用了动态稀疏训练(DST)、稀疏变异(SV)和混合稀疏注意力(HSA)。DST允许模型在训练过程中动态调整稀疏结构;SV通过改变稀疏模式来提高模型的泛化能力;HSA则是一种专门为稀疏模型设计的注意力机制,能够有效地利用稀疏连接进行计算。与传统的静态稀疏方法相比,MST能够更好地适应模型的训练过程,从而在减少计算量的同时保持性能。
关键设计:在预热阶段,采用逐渐增加稀疏度的方式,避免模型性能急剧下降。超稀疏化阶段,根据一定的策略(例如,基于梯度幅值)移除不重要的连接。恢复阶段,重新引入部分连接,以提升模型性能。混合稀疏注意力机制(HSA)的设计是关键,它允许模型在不同的注意力头中使用不同的稀疏模式,从而更好地捕捉输入序列中的依赖关系。具体的稀疏比例、连接恢复策略等参数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在GPT-2模型上应用MST,可以在不损失性能的前提下,将FLOPs降低4倍。这意味着可以使用更少的计算资源和时间来完成模型的预训练,从而大大提高了训练效率。该结果验证了MST在降低Transformer模型预训练成本方面的有效性。
🎯 应用场景
该研究成果可应用于各种基于Transformer的大型语言模型的预训练,例如GPT、BERT等。通过降低预训练的计算成本,可以加速模型的开发和部署,并使得在资源受限的环境下训练大型模型成为可能。此外,该方法还可以推广到其他类型的神经网络,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) have made significant strides in complex tasks, yet their widespread adoption is impeded by substantial computational demands. With hundreds of billion parameters, transformer-based LLMs necessitate months of pretraining across a high-end GPU cluster. However, this paper reveals a compelling finding: transformers exhibit considerable redundancy in pretraining computations, which motivates our proposed solution, Mixed Sparsity Training (MST), an efficient pretraining method that can reduce about $75\%$ of Floating Point Operations (FLOPs) while maintaining performance. MST integrates dynamic sparse training (DST) with Sparsity Variation (SV) and Hybrid Sparse Attention (HSA) during pretraining, involving three distinct phases: warm-up, ultra-sparsification, and restoration. The warm-up phase transforms the dense model into a sparse one, and the restoration phase reinstates connections. Throughout these phases, the model is trained with a dynamically evolving sparse topology and an HSA mechanism to maintain performance and minimize training FLOPs concurrently. Our experiment on GPT-2 showcases a FLOP reduction of $4\times$ without compromising performance.