Centralized Reward Agent for Knowledge Sharing and Transfer in Multi-Task Reinforcement Learning
作者: Haozhe Ma, Zhengding Luo, Thanh Vinh Vo, Kuankuan Sima, Tze-Yun Leong
分类: cs.LG, cs.AI
发布日期: 2024-08-20 (更新: 2025-10-26)
💡 一句话要点
提出集中式奖励代理CRA,用于多任务强化学习中的知识共享与迁移。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多任务强化学习 奖励塑造 知识共享 知识迁移 集中式奖励代理
📋 核心要点
- 强化学习中稀疏奖励问题是挑战,现有方法难以有效利用辅助信息。
- 提出集中式奖励代理CRA,通过塑造奖励实现跨任务知识共享与迁移。
- 实验表明,该方法在多任务稀疏奖励环境中具有鲁棒性,并能有效迁移到新任务。
📝 摘要(中文)
本文提出了一种新颖的多任务强化学习框架,该框架集成了集中式奖励代理(CRA)和多个分布式策略代理。CRA充当知识池,旨在从各种任务中提取知识并将其分发给各个策略代理,以提高学习效率。具体而言,塑造的奖励充当编码知识的直接指标。该框架不仅增强了已建立任务之间的知识共享,而且还通过转移有意义的奖励信号来适应新任务。我们在离散和连续域(包括代表性的Meta-World基准)上验证了所提出的方法,证明了其在多任务稀疏奖励环境中的鲁棒性以及对未见任务的有效可迁移性。
🔬 方法详解
问题定义:多任务强化学习中,当奖励信号稀疏时,智能体难以有效学习。现有方法在跨任务知识共享和迁移方面存在不足,尤其是在适应新任务时,无法有效利用已有知识加速学习。
核心思路:本文的核心思路是利用奖励塑造(Reward Shaping)策略,将知识编码为奖励信号,并通过一个集中的奖励代理(CRA)来管理和分发这些奖励信号。CRA从各个任务中学习,并将有用的奖励信号传递给各个策略代理,从而促进知识共享和迁移。
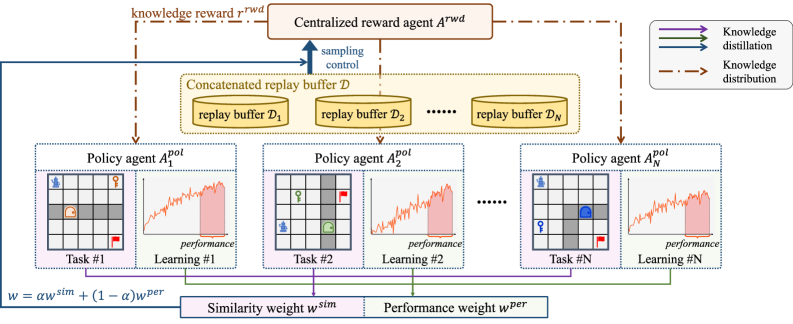
技术框架:该框架包含一个集中式奖励代理(CRA)和多个分布式策略代理。每个策略代理负责解决一个特定的任务。CRA从所有任务中收集信息,学习一个通用的奖励函数,并根据该函数为每个策略代理提供额外的奖励信号。这些额外的奖励信号可以指导策略代理更快地学习到最优策略。整体流程是:每个策略代理与环境交互,获得即时奖励和状态转移信息;这些信息被发送到CRA;CRA根据学习到的奖励函数生成额外的奖励信号;策略代理结合环境奖励和CRA提供的奖励信号进行策略更新。
关键创新:最重要的创新点在于CRA的设计,它充当了一个知识池,能够从多个任务中提取知识,并将其转化为奖励信号,从而实现跨任务的知识共享和迁移。与传统的奖励塑造方法不同,CRA是集中式的,能够更好地利用所有任务的信息,学习到更有效的奖励函数。
关键设计:CRA可以使用各种机器学习模型来实现,例如神经网络或决策树。奖励函数的设计需要考虑任务之间的相似性和差异性,以便能够有效地迁移知识。具体实现细节未知,论文可能未详细描述CRA内部的具体网络结构和损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的方法在Meta-World基准测试中表现出色,证明了其在多任务稀疏奖励环境中的鲁棒性。该方法不仅能够提高已建立任务的学习效率,而且能够有效地将知识迁移到未见过的任务上。具体的性能提升数据未知,论文可能未提供详细的数值比较。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。在这些领域中,通常需要智能体在多个相关任务上进行学习,并且奖励信号往往是稀疏的。通过使用集中式奖励代理,可以加速智能体的学习过程,提高其在复杂环境中的表现。未来的研究可以探索如何将该方法应用于更广泛的领域,例如自然语言处理和计算机视觉。
📄 摘要(原文)
Reward shaping is effective in addressing the sparse-reward challenge in reinforcement learning (RL) by providing immediate feedback through auxiliary, informative rewards. Based on the reward shaping strategy, we propose a novel multi-task reinforcement learning framework that integrates a centralized reward agent (CRA) and multiple distributed policy agents. The CRA functions as a knowledge pool, aimed at distilling knowledge from various tasks and distributing it to individual policy agents to improve learning efficiency. Specifically, the shaped rewards serve as a straightforward metric for encoding knowledge. This framework not only enhances knowledge sharing across established tasks but also adapts to new tasks by transferring meaningful reward signals. We validate the proposed method on both discrete and continuous domains, including the representative Meta-World benchmark, demonstrating its robustness in multi-task sparse-reward settings and its effective transferability to unseen tasks.