An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing
作者: Xinlang Yue, Yiran Liu, Fangzhou Shi, Sihong Luo, Chen Zhong, Min Lu, Zhe Xu
分类: cs.LG, cs.AI
发布日期: 2024-08-20
备注: 8 pages, 4 figures
💡 一句话要点
提出基于端到端强化学习的D2SN模型,解决网约车微观视角下的订单分配问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 强化学习 订单分配 网约车 马尔可夫决策过程 深度学习
📋 核心要点
- 现有网约车订单分配方案通常采用两阶段方法,难以有效处理司机和乘客行为的高度不确定性。
- 论文提出一种端到端的强化学习方法,通过D2SN网络直接生成订单-司机分配方案,实现联合优化。
- 在滴滴真实数据集上的实验表明,该方法在匹配效率和用户体验方面显著优于现有基线方法。
📝 摘要(中文)
本文提出了一种基于端到端强化学习的订单分配方法,用于解决网约车服务中局部时空环境下的微观订单调度问题。现有工业解决方案主要采用两阶段模式,结合启发式或学习算法与简单的组合方法,难以应对司机和乘客行为的不确定性,包括出现时间、空间关系和行程持续时间等。本文采用双层马尔可夫决策过程框架对该问题进行建模,并提出了深度双重可扩展网络(D2SN),一种编码器-解码器结构的神经网络,可以直接生成订单-司机分配方案并停止分配。此外,通过利用上下文动态,该方法可以适应行为模式以获得更好的性能。在滴滴真实数据集上的大量实验表明,所提出的方法在优化匹配效率和用户体验方面显著优于竞争基线。此外,我们评估了部署方案,并从大规模工程实施的角度讨论了部署测试中获得的收益和经验。
🔬 方法详解
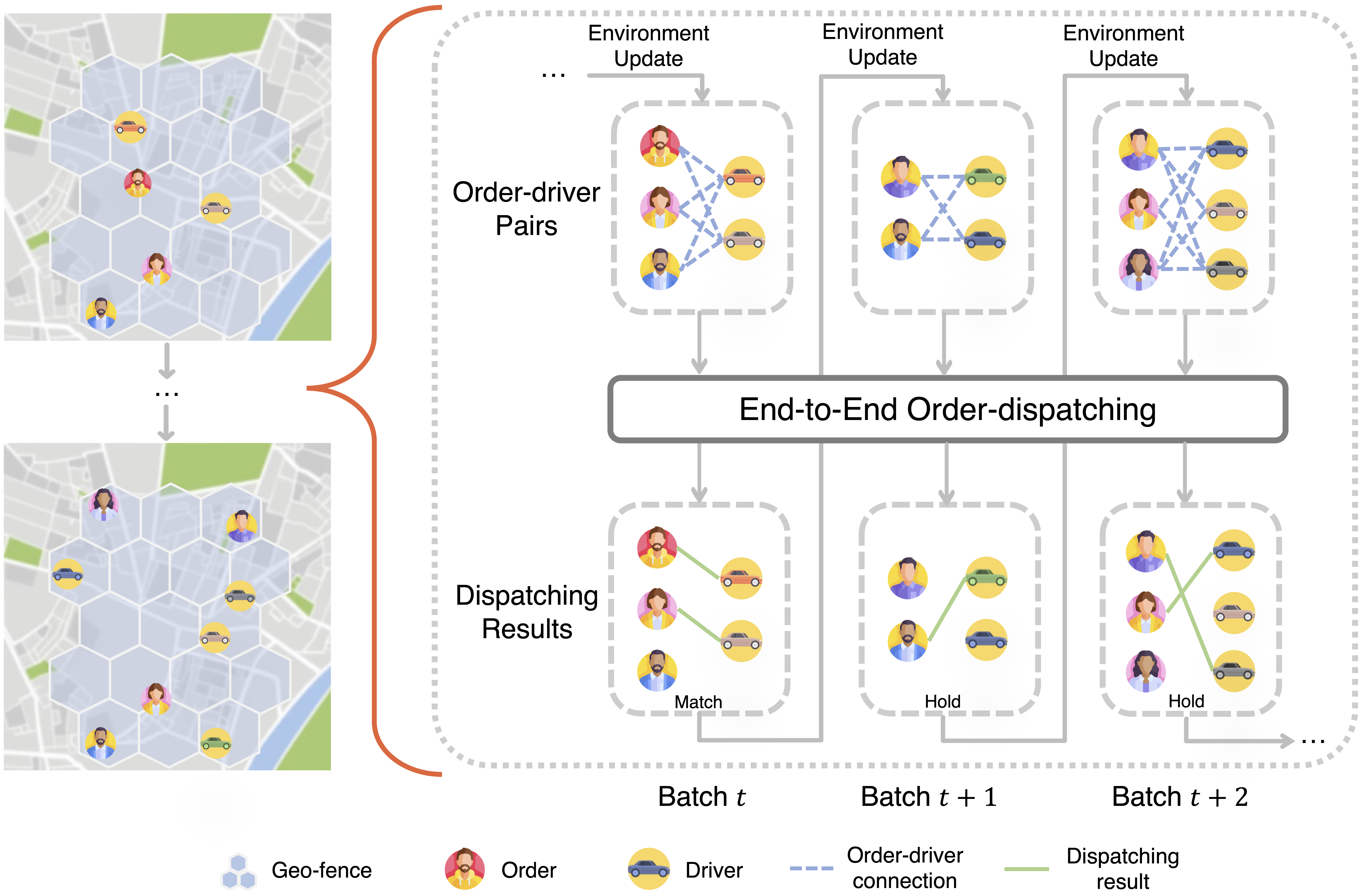
问题定义:论文旨在解决网约车平台中微观视角下的订单分配问题,即如何在局部时空环境中,将订单高效、合理地分配给司机。现有方法通常采用两阶段模式,首先预测司机和乘客的行为,然后使用组合优化方法进行分配。这种方法的痛点在于,两个阶段是分离的,无法进行端到端的优化,且难以充分利用上下文信息。
核心思路:论文的核心思路是将订单分配问题建模为一个序列决策过程,并使用强化学习方法进行求解。通过端到端的学习,模型可以直接从状态(当前订单和司机的信息)映射到动作(订单-司机分配方案),从而避免了传统方法中复杂的特征工程和组合优化过程。这种方法能够更好地适应司机和乘客行为的动态变化,并实现全局优化。
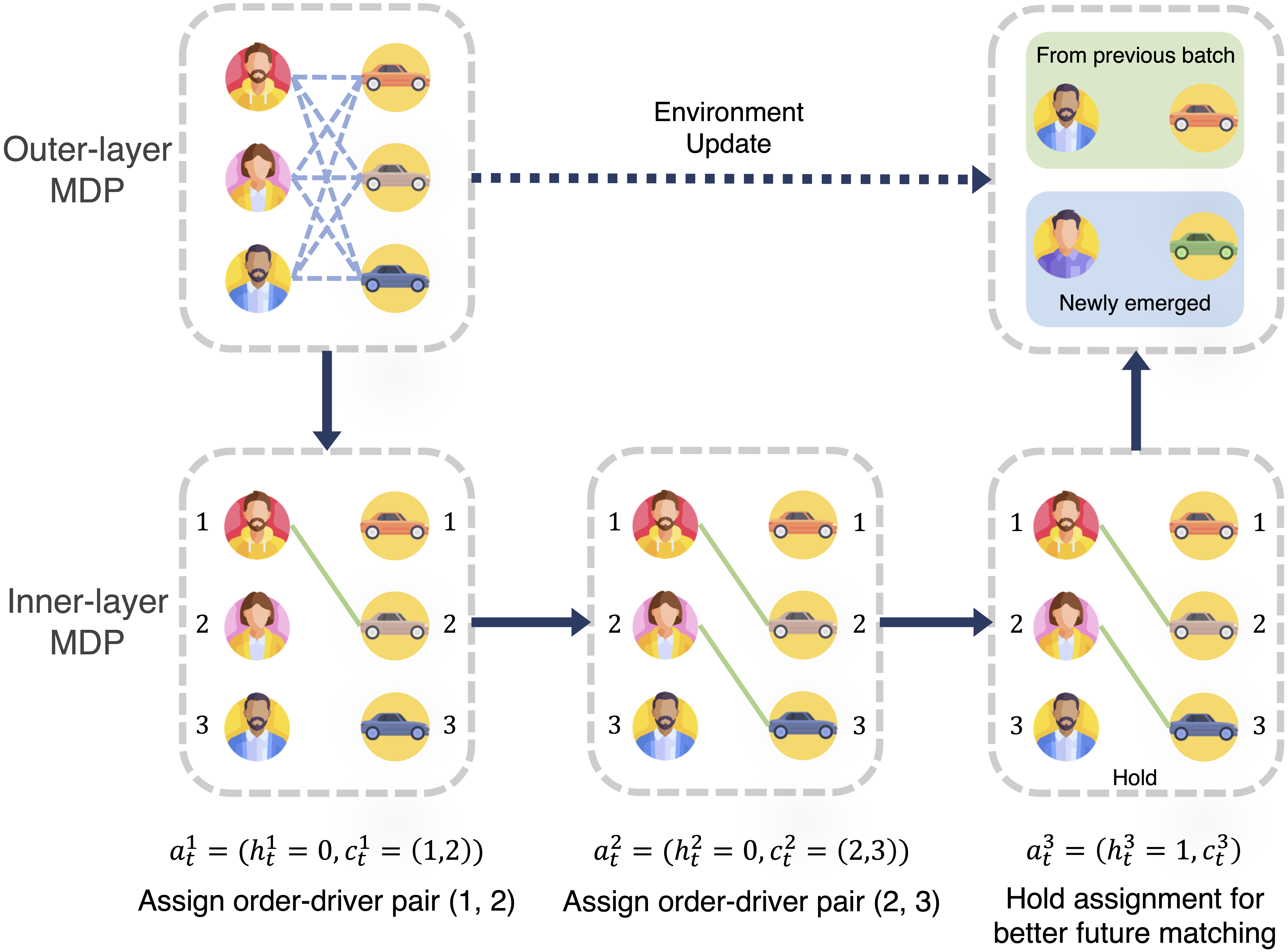
技术框架:论文采用双层马尔可夫决策过程(MDP)框架来建模订单分配问题。第一层MDP用于生成订单-司机分配方案,第二层MDP用于决定何时停止分配。D2SN网络作为强化学习智能体的核心,采用编码器-解码器结构。编码器负责提取订单和司机的特征,解码器负责生成订单-司机分配方案和停止分配的决策。整个框架通过强化学习算法进行训练,目标是最大化平台的收益,例如提高匹配率、降低等待时间等。
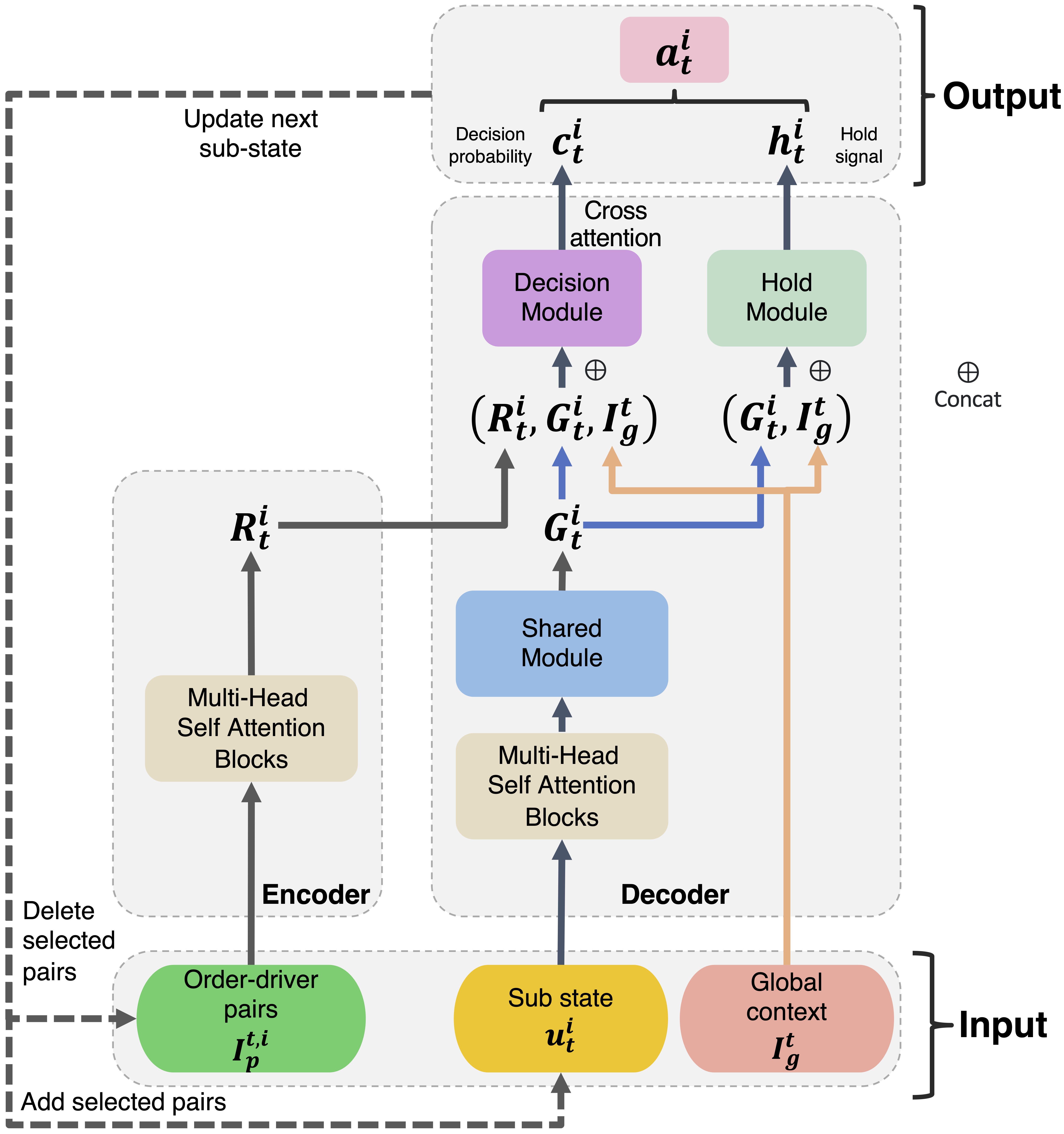
关键创新:论文最重要的技术创新点在于提出了端到端的强化学习方法,将行为预测和组合优化统一到一个框架中。与传统的两阶段方法相比,该方法能够实现全局优化,并更好地适应司机和乘客行为的动态变化。此外,D2SN网络的设计也考虑了订单分配问题的特点,能够有效地提取订单和司机的特征,并生成合理的分配方案。
关键设计:D2SN网络采用两层结构,第一层是编码器,用于提取订单和司机的特征。编码器可以使用各种神经网络结构,例如卷积神经网络(CNN)或循环神经网络(RNN)。第二层是解码器,用于生成订单-司机分配方案和停止分配的决策。解码器可以使用注意力机制来关注重要的订单和司机。损失函数包括匹配效率和用户体验两部分,通过强化学习算法进行优化。具体的强化学习算法未知。
🖼️ 关键图片
📊 实验亮点
在滴滴真实数据集上的实验结果表明,该方法在匹配效率和用户体验方面显著优于现有基线方法。具体提升幅度未知,但摘要中强调了“显著优于竞争基线”,表明性能提升较为明显。论文还评估了部署方案,并讨论了大规模工程实施的经验。
🎯 应用场景
该研究成果可应用于各种网约车平台,提升订单分配效率,降低乘客等待时间,提高司机收入,从而改善用户体验和平台运营效率。此外,该方法也可以扩展到其他类似的资源分配问题,例如外卖配送、物流调度等。
📄 摘要(原文)
Assigning orders to drivers under localized spatiotemporal context (micro-view order-dispatching) is a major task in Didi, as it influences ride-hailing service experience. Existing industrial solutions mainly follow a two-stage pattern that incorporate heuristic or learning-based algorithms with naive combinatorial methods, tackling the uncertainty of both sides' behaviors, including emerging timings, spatial relationships, and travel duration, etc. In this paper, we propose a one-stage end-to-end reinforcement learning based order-dispatching approach that solves behavior prediction and combinatorial optimization uniformly in a sequential decision-making manner. Specifically, we employ a two-layer Markov Decision Process framework to model this problem, and present \underline{D}eep \underline{D}ouble \underline{S}calable \underline{N}etwork (D2SN), an encoder-decoder structure network to generate order-driver assignments directly and stop assignments accordingly. Besides, by leveraging contextual dynamics, our approach can adapt to the behavioral patterns for better performance. Extensive experiments on Didi's real-world benchmarks justify that the proposed approach significantly outperforms competitive baselines in optimizing matching efficiency and user experience tasks. In addition, we evaluate the deployment outline and discuss the gains and experiences obtained during the deployment tests from the view of large-scale engineering implementation.