AdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference
作者: Shuzhang Zhong, Ling Liang, Yuan Wang, Runsheng Wang, Ru Huang, Meng Li
分类: cs.LG
发布日期: 2024-08-19
🔗 代码/项目: GITHUB
💡 一句话要点
AdapMoE:面向高效MoE推理的自适应专家门控与管理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 边缘计算 自适应门控 模型推理优化
📋 核心要点
- MoE模型在边缘设备部署面临高昂的专家按需加载开销,限制了其应用。
- AdapMoE通过敏感性分析动态调整激活专家数量,并结合预取和缓存管理降低加载延迟。
- 实验表明,AdapMoE在不损失精度的情况下,减少了25%的激活专家数量,加速1.35倍。
📝 摘要(中文)
混合专家模型(MoE)旨在提高大型语言模型(LLM)的效率,而无需成比例地增加计算需求。然而,由于管理稀疏激活专家带来的高按需加载开销,它们在边缘设备上的部署仍然面临重大挑战。本文介绍了一种用于高效MoE推理的算法-系统协同设计框架AdapMoE。AdapMoE具有自适应专家门控和管理功能,可减少按需加载开销。我们观察到专家加载在不同层和token之间的异构性,基于此,我们提出了一种基于敏感性的策略来动态调整激活专家的数量。同时,我们还集成了先进的预取和缓存管理技术,以进一步减少加载延迟。通过在各种平台上的全面评估,我们证明AdapMoE始终优于现有技术,在不降低准确性的前提下,平均减少了25%的激活专家数量,并实现了1.35倍的加速。
🔬 方法详解
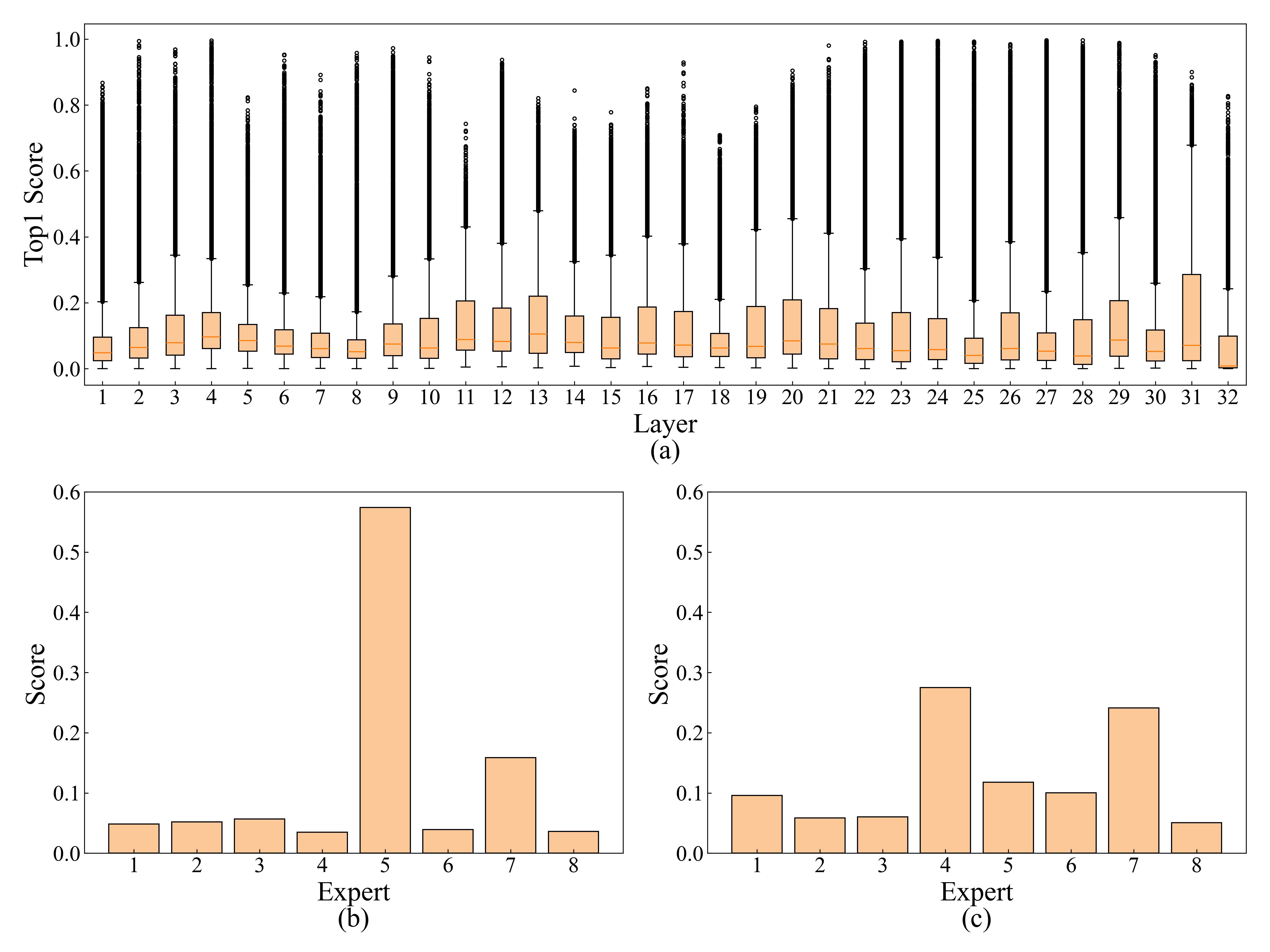
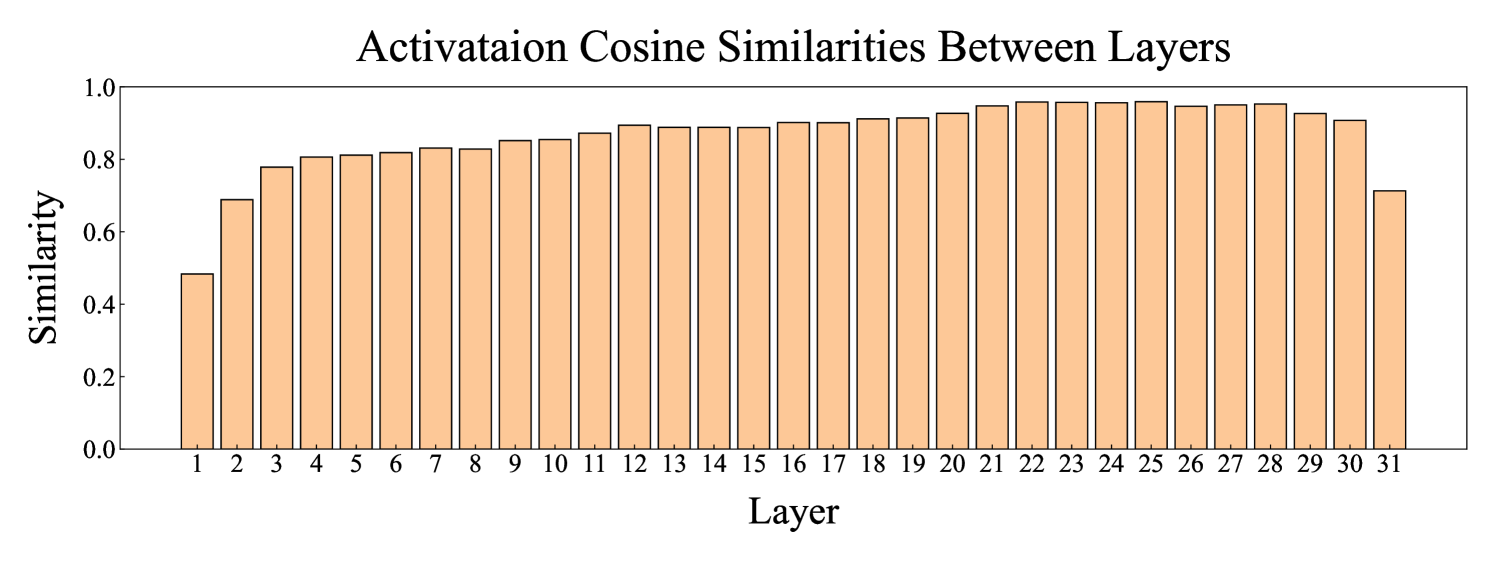
问题定义:MoE模型在边缘设备上部署时,由于专家模型的稀疏激活特性,需要频繁地按需加载专家模型,导致显著的加载开销。现有方法未能充分利用专家加载的异构性,导致资源浪费和推理效率低下。
核心思路:AdapMoE的核心思路是根据不同层和token对专家加载的敏感性,自适应地调整激活专家的数量。通过减少不必要的专家加载,降低整体的按需加载开销,从而提高推理效率。同时,结合预取和缓存管理,进一步降低加载延迟。
技术框架:AdapMoE是一个算法-系统协同设计框架,主要包含以下几个模块:1) 敏感性分析模块:用于分析不同层和token对专家加载的敏感性。2) 自适应专家门控模块:根据敏感性分析结果,动态调整激活专家的数量。3) 预取模块:提前加载即将使用的专家模型。4) 缓存管理模块:管理已加载的专家模型,减少重复加载。整体流程是,首先进行敏感性分析,然后根据分析结果动态调整专家门控,同时利用预取和缓存管理加速专家加载。
关键创新:AdapMoE的关键创新在于提出了基于敏感性的自适应专家门控策略。与现有方法中固定数量的专家激活不同,AdapMoE能够根据不同层和token的特性,动态调整激活专家的数量,从而更有效地利用计算资源。
关键设计:敏感性分析通过计算每个层和token对不同专家的梯度或激活值的变化来评估其重要性。自适应专家门控模块使用一个可学习的门控网络,根据敏感性分析的结果,输出每个专家的激活概率。预取模块根据历史访问模式预测即将使用的专家,并提前加载。缓存管理模块使用LRU(Least Recently Used)策略来管理缓存中的专家模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AdapMoE在各种平台上始终优于现有技术。具体来说,AdapMoE在不降低准确性的前提下,平均减少了25%的激活专家数量,并实现了1.35倍的加速。这些结果证明了AdapMoE在提高MoE模型推理效率方面的有效性。
🎯 应用场景
AdapMoE适用于各种需要在边缘设备上部署大型语言模型的场景,例如智能手机、物联网设备和自动驾驶汽车。通过提高MoE模型的推理效率,AdapMoE可以降低设备的功耗和延迟,从而改善用户体验,并为更复杂的边缘智能应用铺平道路。未来的研究可以探索AdapMoE在更多模型架构和硬件平台上的应用。
📄 摘要(原文)
Mixture-of-Experts (MoE) models are designed to enhance the efficiency of large language models (LLMs) without proportionally increasing the computational demands. However, their deployment on edge devices still faces significant challenges due to high on-demand loading overheads from managing sparsely activated experts. This paper introduces AdapMoE, an algorithm-system co-design framework for efficient MoE inference. AdapMoE features adaptive expert gating and management to reduce the on-demand loading overheads. We observe the heterogeneity of experts loading across layers and tokens, based on which we propose a sensitivity-based strategy to adjust the number of activated experts dynamically. Meanwhile, we also integrate advanced prefetching and cache management techniques to further reduce the loading latency. Through comprehensive evaluations on various platforms, we demonstrate AdapMoE consistently outperforms existing techniques, reducing the average number of activated experts by 25% and achieving a 1.35x speedup without accuracy degradation. Code is available at: https://github.com/PKU-SEC-Lab/AdapMoE.