Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
作者: Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
分类: cs.LG, cs.AI, cs.CL, cs.RO
发布日期: 2024-08-19
备注: weirdlabuw.github.io/vpl
💡 一句话要点
提出基于变分偏好学习的个性化RLHF方法,解决用户偏好多样性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 个性化 变分推断 潜在变量 奖励建模 多模态学习
📋 核心要点
- 传统RLHF方法无法处理用户偏好的多样性,简单平均导致奖励不准确和性能下降。
- 提出基于潜在变量的多模态RLHF方法,推断用户特定潜在变量,并以此为条件学习奖励模型和策略。
- 实验表明,该方法能有效应对欠规范问题,提高奖励函数准确性,并能测量不确定性和主动学习用户偏好。
📝 摘要(中文)
从人类反馈中进行强化学习(RLHF)是使基础模型与人类价值观和偏好对齐的强大范例。然而,当前的RLHF技术无法解释不同人群中个体人类偏好自然存在的差异。当这些差异出现时,传统的RLHF框架只是对它们进行平均,导致不准确的奖励和个体子群体的表现不佳。为了解决多元对齐的需求,我们开发了一类多模态RLHF方法。我们提出的技术基于潜在变量公式——推断一个新的用户特定的潜在变量,并学习以该潜在变量为条件的奖励模型和策略,而无需额外的用户特定数据。虽然概念上很简单,但我们表明,在实践中,这种奖励建模需要围绕模型架构和奖励缩放进行仔细的算法考虑。为了实证验证我们提出的技术,我们首先表明它可以提供一种方法来对抗模拟控制问题中的欠规范,推断和优化用户特定的奖励函数。接下来,我们对代表不同用户偏好的多元语言数据集进行实验,并证明了改进的奖励函数准确性。我们还展示了这种概率框架在测量不确定性和主动学习用户偏好方面的优势。这项工作能够从具有不同偏好的不同用户群体中学习,这是从机器人学习到基础模型对齐等问题中自然出现的重要挑战。
🔬 方法详解
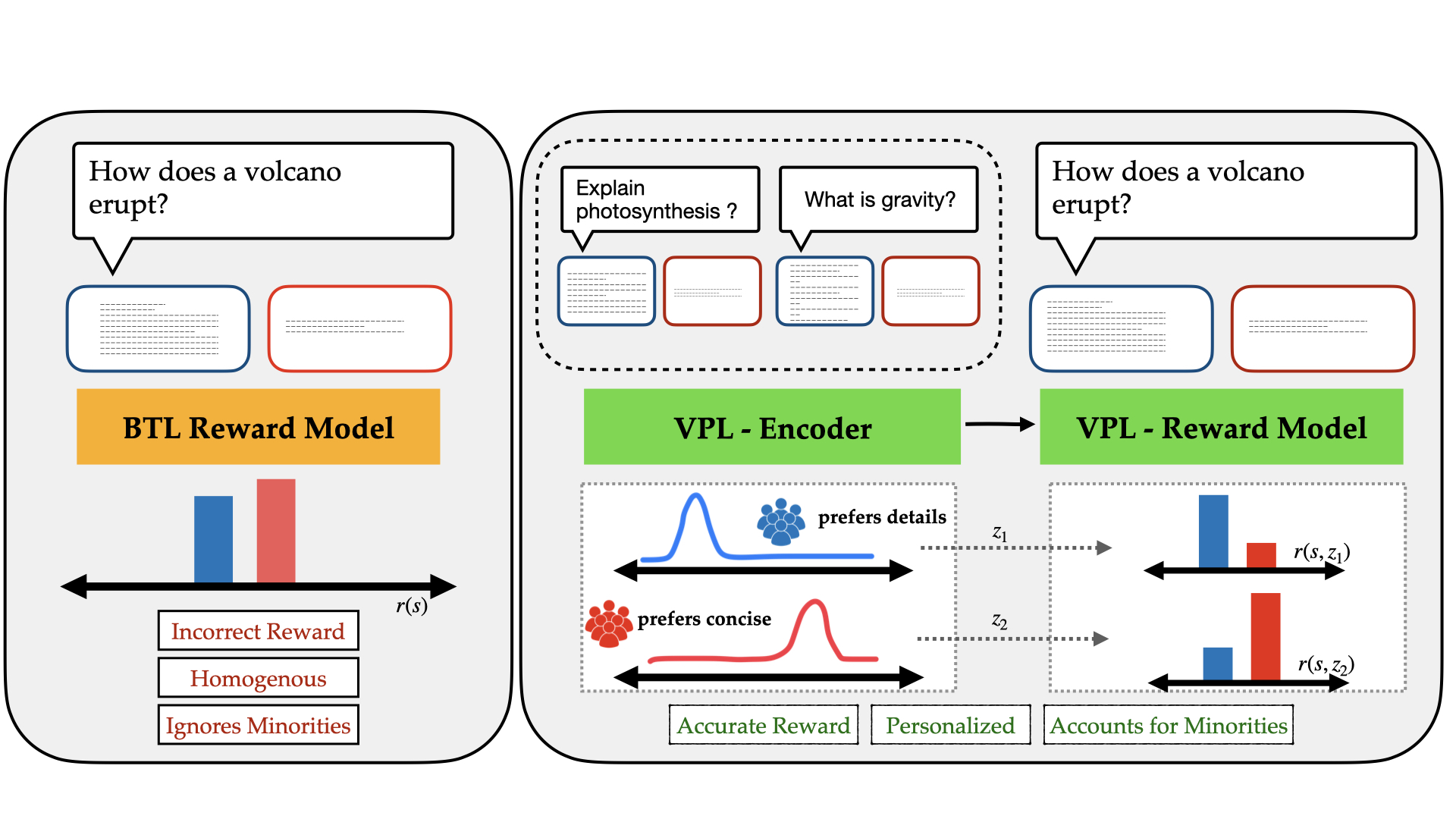
问题定义:现有RLHF方法在处理具有不同偏好的用户群体时存在局限性。传统方法通过简单平均用户反馈来学习奖励函数,忽略了个体偏好的差异,导致奖励信号不准确,最终影响强化学习策略的性能。这种平均策略无法满足个性化需求,尤其是在用户偏好差异显著的场景下。
核心思路:本文的核心思路是引入潜在变量来捕捉用户偏好的个性化差异。通过学习一个用户特定的潜在变量,并将奖励模型和策略以该潜在变量为条件,可以实现对不同用户偏好的建模和优化。这种方法避免了简单平均,能够更准确地反映个体用户的偏好,从而提高强化学习的性能。
技术框架:该方法基于变分推断框架,包含以下主要模块:1) 编码器:用于从用户反馈中推断用户特定的潜在变量。2) 奖励模型:以潜在变量为条件,预测给定状态-动作对的奖励。3) 策略网络:以潜在变量为条件,学习在给定状态下选择最优动作的策略。整个流程包括:收集用户反馈数据,使用编码器推断潜在变量,使用奖励模型预测奖励,使用强化学习算法优化策略,并循环迭代以提高性能。
关键创新:该方法最重要的创新点在于引入了潜在变量来建模用户偏好的个性化差异。与传统的RLHF方法相比,该方法能够更好地捕捉个体用户的偏好,从而提高奖励函数的准确性和强化学习策略的性能。此外,该方法还提供了一种测量不确定性和主动学习用户偏好的概率框架。
关键设计:在模型架构方面,编码器、奖励模型和策略网络可以使用各种神经网络结构,如多层感知机、卷积神经网络或循环神经网络。损失函数包括:1) 变分下界(ELBO)损失:用于优化编码器,确保潜在变量能够有效地捕捉用户偏好。2) 奖励预测损失:用于优化奖励模型,使其能够准确预测给定状态-动作对的奖励。3) 强化学习损失:用于优化策略网络,使其能够选择最优动作。奖励缩放是一个重要的技术细节,需要仔细调整以确保训练的稳定性和性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在模拟控制问题中能够有效应对欠规范问题,推断和优化用户特定的奖励函数。在多元语言数据集上,该方法显著提高了奖励函数准确性。此外,该方法还展示了在测量不确定性和主动学习用户偏好方面的优势。这些结果表明,该方法能够有效地处理用户偏好的多样性,提高强化学习的性能。
🎯 应用场景
该研究成果可广泛应用于需要个性化用户体验的领域,如个性化推荐系统、人机交互、机器人学习等。例如,在机器人学习中,可以根据不同用户的偏好定制机器人的行为。在基础模型对齐方面,可以更好地对齐不同用户的价值观,避免模型产生偏见或歧视。该研究有助于实现更公平、更个性化的人工智能系统。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.