MoDeGPT: Modular Decomposition for Large Language Model Compression
作者: Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-08-19 (更新: 2025-05-02)
备注: ICLR 2025 Oral
💡 一句话要点
MoDeGPT:通过模块分解实现大语言模型高效压缩,无需微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 模块分解 低秩分解 矩阵分解 推理加速
📋 核心要点
- 现有大语言模型压缩方法,如低秩分解,常导致精度下降或引入显著的参数和推理开销,限制了其在资源受限设备上的部署。
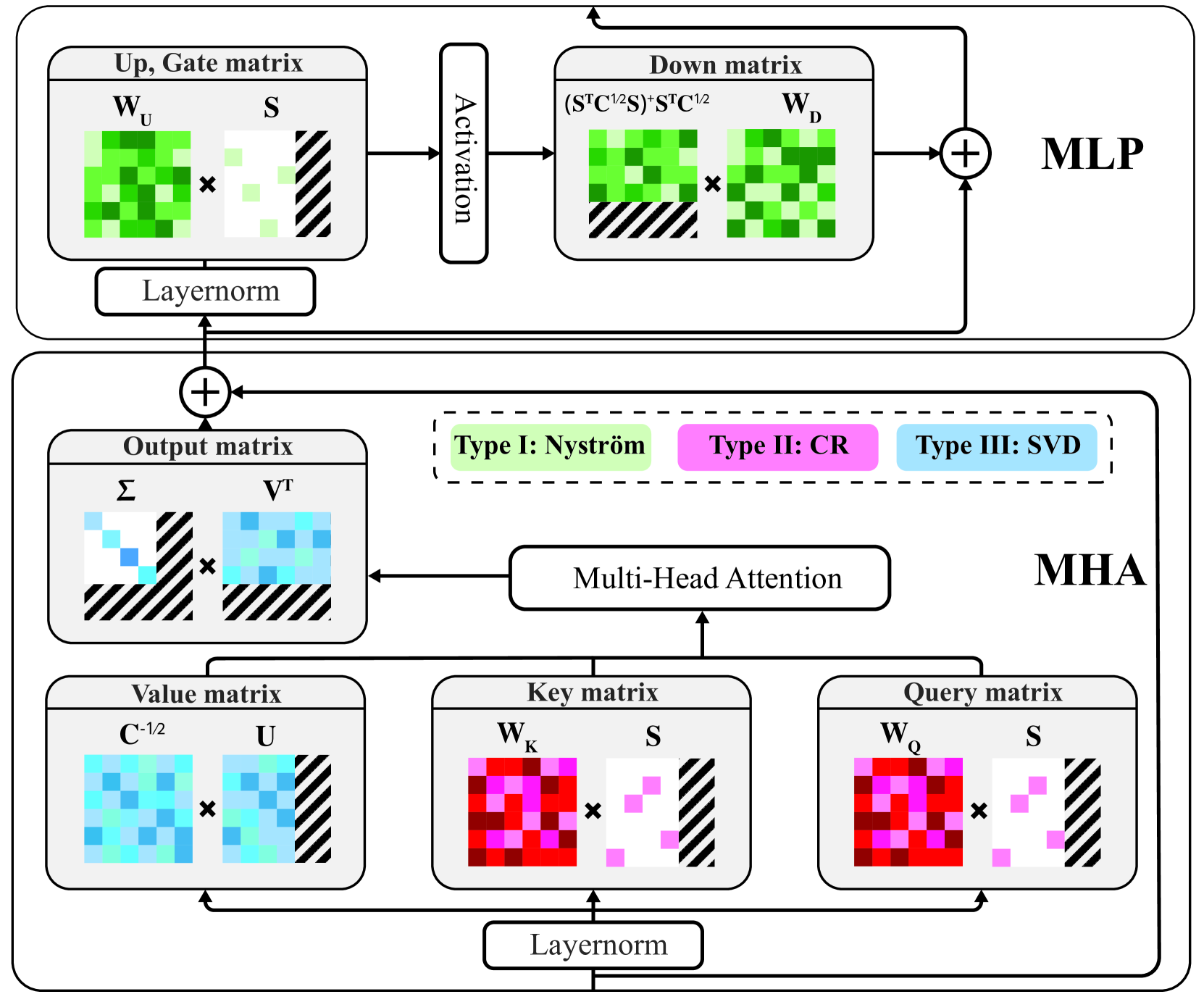
- MoDeGPT通过将Transformer块分解为模块,并利用矩阵分解算法重建模块级输出来实现压缩,无需额外的微调过程。
- 实验结果表明,MoDeGPT在压缩率高达30%的情况下,仍能保持90-95%的零样本性能,且压缩过程高效,推理吞吐量提升显著。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出卓越的性能,重塑了人工智能领域。然而,巨大的计算需求使得它们在资源受限的设备上的部署具有挑战性。最近,使用低秩矩阵技术的压缩方法显示出希望,但这些方法通常会导致精度下降或引入参数和推理延迟方面的显著开销。本文介绍了一种新颖的结构化压缩框架——模块分解(MoDeGPT),它不需要恢复微调,同时解决了上述缺点。MoDeGPT将Transformer块划分为由矩阵对组成的模块,并通过重建模块级输出来减少隐藏维度。MoDeGPT是基于一个理论框架开发的,该框架利用三种成熟的矩阵分解算法——Nyström近似、CR分解和SVD,并将它们应用于我们重新定义的Transformer模块。全面的实验表明,MoDeGPT在没有反向传播的情况下,匹配或超过了依赖梯度信息的先前结构化压缩方法,并在压缩一个13B模型时节省了98%的计算成本。在 extsc{Llama}-2/3和OPT模型上,MoDeGPT以25-30%的压缩率保持了90-95%的零样本性能。此外,压缩可以在单个GPU上在几个小时内完成,并将推理吞吐量提高了高达46%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在资源受限设备上部署的难题。现有基于低秩矩阵分解的压缩方法虽然有效,但通常会牺牲模型精度或引入额外的参数和推理延迟,无法同时保证压缩效率和模型性能。
核心思路:MoDeGPT的核心思路是将Transformer块分解为更小的模块,并在模块级别上进行压缩。通过重建模块的输出,可以在不进行微调的情况下减少隐藏维度,从而实现模型的压缩。这种模块化的分解方式允许更精细的控制压缩过程,并减少了对模型整体性能的影响。
技术框架:MoDeGPT的技术框架主要包含以下几个步骤:1) 将Transformer块分解为由矩阵对组成的模块;2) 对每个模块的输出进行重建,以减少隐藏维度;3) 利用三种矩阵分解算法(Nyström近似、CR分解和SVD)来实现模块级别的压缩。整个过程无需反向传播和微调。
关键创新:MoDeGPT的关键创新在于其模块化的分解压缩方法,以及在模块级别上应用矩阵分解算法。与传统的全局低秩分解方法不同,MoDeGPT能够更精细地控制压缩过程,并减少对模型性能的影响。此外,MoDeGPT无需微调,大大简化了压缩流程,并降低了计算成本。
关键设计:MoDeGPT的关键设计包括:1) Transformer块的模块划分方式,具体如何将Transformer块分解为矩阵对;2) 模块输出重建的具体方法,如何利用矩阵分解算法来减少隐藏维度;3) 三种矩阵分解算法(Nyström近似、CR分解和SVD)的选择和应用策略,如何根据不同的模块选择合适的分解算法。
🖼️ 关键图片


📊 实验亮点
MoDeGPT在压缩Llama-2/3和OPT模型时,实现了25-30%的压缩率,同时保持了90-95%的零样本性能。在压缩一个13B模型时,节省了98%的计算成本。此外,压缩过程可以在单个GPU上在几个小时内完成,并将推理吞吐量提高了高达46%。这些结果表明,MoDeGPT是一种高效且有效的模型压缩方法。
🎯 应用场景
MoDeGPT适用于各种需要部署大型语言模型的场景,尤其是在资源受限的设备上,如移动设备、嵌入式系统和边缘计算设备。该方法可以显著降低模型的计算和存储成本,提高推理速度,从而使得这些设备能够运行更复杂的AI应用。此外,MoDeGPT还可以应用于云端服务器,以降低模型部署和推理的成本。
📄 摘要(原文)
Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms -- Nyström approximation, CR decomposition, and SVD -- and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.