Understanding Transformer Architecture through Continuous Dynamics: A Partial Differential Equation Perspective
作者: Yukun Zhang, Xueqing Zhou
分类: cs.LG, cs.AI, cs.IT
发布日期: 2024-08-18 (更新: 2025-09-27)
💡 一句话要点
Transformer架构连续动力学分析:基于偏微分方程的理解框架
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: Transformer架构 偏微分方程 连续动力系统 残差连接 层归一化 深度学习 理论分析
📋 核心要点
- Transformer内部机制缺乏理论理解,现有方法难以解释其设计原理。
- 将Transformer视为连续时空动力系统,用偏微分方程描述其行为,分析各组件的数学作用。
- 实验表明,残差连接和层归一化是保证Transformer稳定训练的关键数学稳定器。
📝 摘要(中文)
Transformer架构彻底改变了人工智能领域,但对其内部机制的理论理解仍然不足。本文提出了一种新的分析框架,将Transformer离散的分层结构重新概念化为一个由主偏微分方程(PDE)控制的连续时空动力系统。在这个框架内,我们将核心架构组件映射到不同的数学算子:自注意力作为非局部交互,前馈网络作为局部反应,以及残差连接和层归一化作为不可或缺的稳定机制。我们没有提出新的模型,而是使用PDE系统作为理论探针来分析这些组件的数学必要性。通过比较标准Transformer和一个缺乏显式稳定器的PDE模拟器,我们的实验为中心论点提供了令人信服的经验证据。我们证明,如果没有残差连接,系统会遭受灾难性的表征漂移,而缺少层归一化会导致不稳定、爆炸性的训练动态。我们的发现表明,这些看似启发式的“技巧”实际上是驯服强大但本质上不稳定的连续系统所需的基本数学稳定器。这项工作为Transformer的设计提供了第一性原理的解释,并为通过连续动力学视角分析深度神经网络建立了一个新的范例。
🔬 方法详解
问题定义:Transformer架构在各种AI任务中取得了巨大成功,但对其内部工作原理的理论理解仍然有限。现有的研究主要集中在经验观察和模型改进上,缺乏对Transformer设计原则的数学解释,例如残差连接和层归一化为何如此重要。
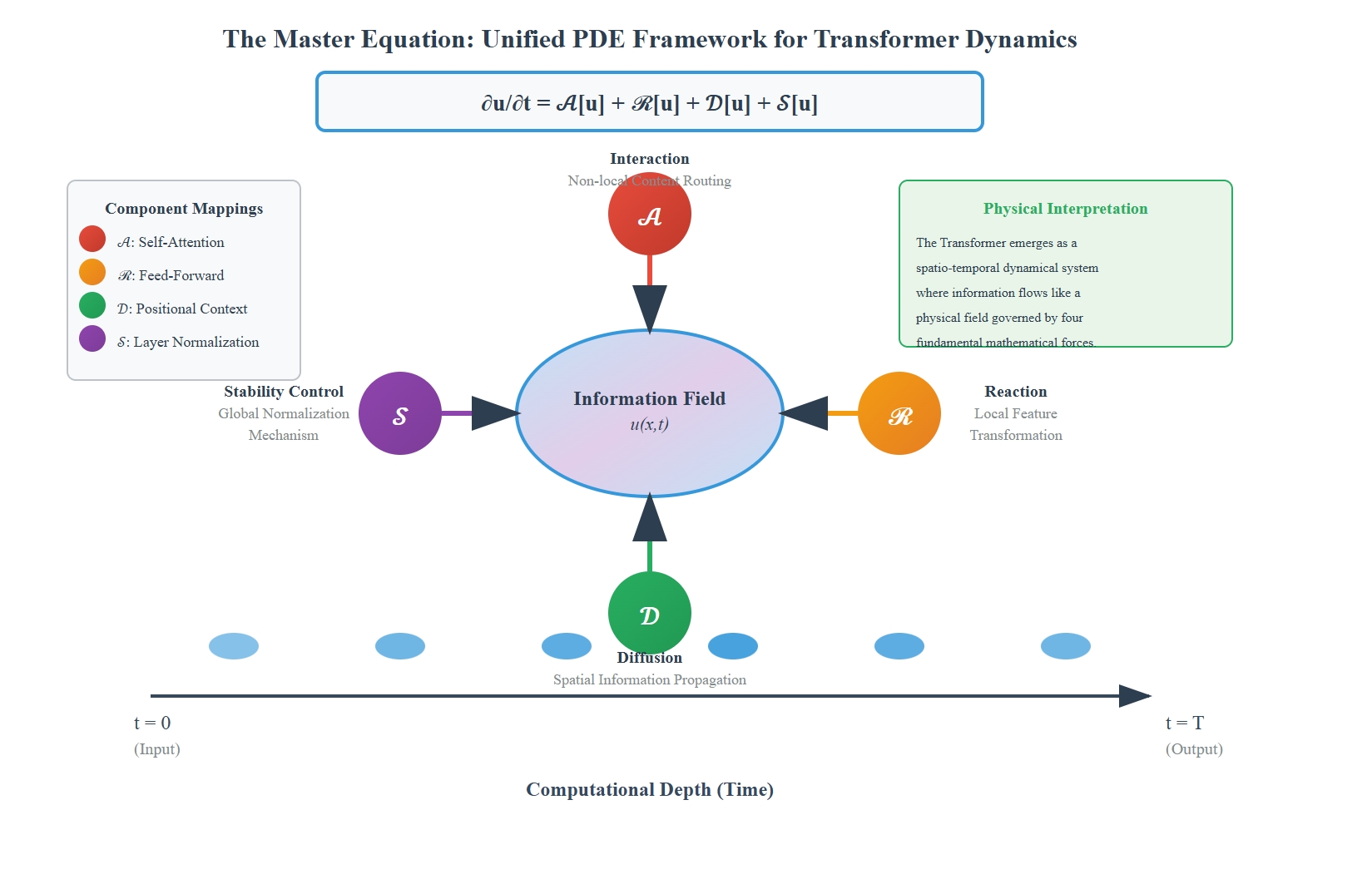
核心思路:本文的核心思路是将Transformer的离散层结构视为一个连续的动力系统,并用偏微分方程(PDE)来描述其演化过程。通过这种连续化的视角,可以将Transformer的各个组件(如自注意力、前馈网络、残差连接和层归一化)映射到PDE中的不同算子,从而分析它们在系统中的作用。
技术框架:该研究没有提出新的模型架构,而是建立了一个理论框架。首先,将Transformer的离散层转化为连续的时间变量。然后,将Transformer的各个组件映射到PDE中的算子:自注意力对应于非局部交互项,前馈网络对应于局部反应项,残差连接和层归一化对应于稳定项。最后,通过数值模拟PDE来验证理论分析。
关键创新:该研究的关键创新在于将Transformer架构与连续动力系统联系起来,并用偏微分方程来描述其行为。这种连续化的视角提供了一种新的理解Transformer内部机制的途径,并为解释Transformer的设计原则提供了数学基础。
关键设计:该研究的关键设计在于如何将Transformer的离散层转化为连续的时间变量,以及如何将Transformer的各个组件映射到PDE中的算子。具体来说,残差连接被解释为防止表征漂移的稳定机制,而层归一化被解释为防止训练过程中出现不稳定和爆炸性行为的稳定机制。通过数值模拟PDE,研究人员验证了这些解释,并证明了残差连接和层归一化对于Transformer的稳定训练至关重要。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当PDE模拟器中移除残差连接时,系统会遭受灾难性的表征漂移;而移除层归一化会导致训练过程不稳定和爆炸性。这些结果有力地支持了残差连接和层归一化是Transformer稳定训练的关键数学稳定器的论点。
🎯 应用场景
该研究为理解和改进Transformer架构提供了新的理论工具,有助于设计更高效、更稳定的深度学习模型。其潜在应用领域包括自然语言处理、计算机视觉、语音识别等,并可能促进新型神经网络架构的开发。
📄 摘要(原文)
The Transformer architecture has revolutionized artificial intelligence, yet a principled theoretical understanding of its internal mechanisms remains elusive. This paper introduces a novel analytical framework that reconceptualizes the Transformer's discrete, layered structure as a continuous spatiotemporal dynamical system governed by a master Partial Differential Equation (PDE). Within this paradigm, we map core architectural components to distinct mathematical operators: self-attention as a non-local interaction, the feed-forward network as a local reaction, and, critically, residual connections and layer normalization as indispensable stabilization mechanisms. We do not propose a new model, but rather employ the PDE system as a theoretical probe to analyze the mathematical necessity of these components. By comparing a standard Transformer with a PDE simulator that lacks explicit stabilizers, our experiments provide compelling empirical evidence for our central thesis. We demonstrate that without residual connections, the system suffers from catastrophic representational drift, while the absence of layer normalization leads to unstable, explosive training dynamics. Our findings reveal that these seemingly heuristic "tricks" are, in fact, fundamental mathematical stabilizers required to tame an otherwise powerful but inherently unstable continuous system. This work offers a first-principles explanation for the Transformer's design and establishes a new paradigm for analyzing deep neural networks through the lens of continuous dynamics.