Directed Exploration in Reinforcement Learning from Linear Temporal Logic
作者: Marco Bagatella, Andreas Krause, Georg Martius
分类: cs.LG
发布日期: 2024-08-18 (更新: 2025-06-09)
💡 一句话要点
提出基于线性时序逻辑引导的强化学习探索方法,提升高维连续控制任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 线性时序逻辑 探索策略 内在奖励 贝叶斯方法 马尔可夫决策过程 自动机 高维控制
📋 核心要点
- 现有基于LTL的强化学习方法面临奖励稀疏问题,限制了其在高维、长时程任务中的应用。
- 论文核心思想是将LTL规范转化为马尔可夫奖励过程,并利用贝叶斯方法估计LDBA的价值,作为内在奖励。
- 实验结果表明,该方法在表格环境和高维连续控制任务中均表现出优越的性能,显著提升了探索效率。
📝 摘要(中文)
线性时序逻辑(LTL)是一种强大的强化学习任务规范语言,它允许描述超出传统折扣回报公式的目标。最近的研究表明,LTL公式可以转化为一种可变的奖励和折扣方案,其优化产生一种策略,使公式满足概率的下界最大化。然而,合成的奖励信号仍然非常稀疏,使得探索具有挑战性。我们旨在克服这个限制,它可以阻止当前的算法扩展到低维、短视距问题之外。我们展示了如何通过进一步利用LTL规范并将相应的极限确定性Büchi自动机(LDBA)转换为马尔可夫奖励过程来实现更好的探索,从而实现一种高级价值估计。通过对LDBA动力学采取贝叶斯视角并提出合适的先验分布,我们表明通过该程序估计的值可以被视为塑造势,并映射到信息丰富的内在奖励。在经验上,我们展示了我们的方法从表格设置到高维连续系统的应用,这些系统迄今为止代表了基于LTL的强化学习算法的重大挑战。
🔬 方法详解
问题定义:现有基于线性时序逻辑(LTL)的强化学习方法,虽然能够处理复杂的任务规范,但由于LTL公式转换后的奖励信号非常稀疏,导致智能体难以有效探索环境,尤其是在高维和长时程任务中。这种稀疏性阻碍了算法的扩展性和实际应用。
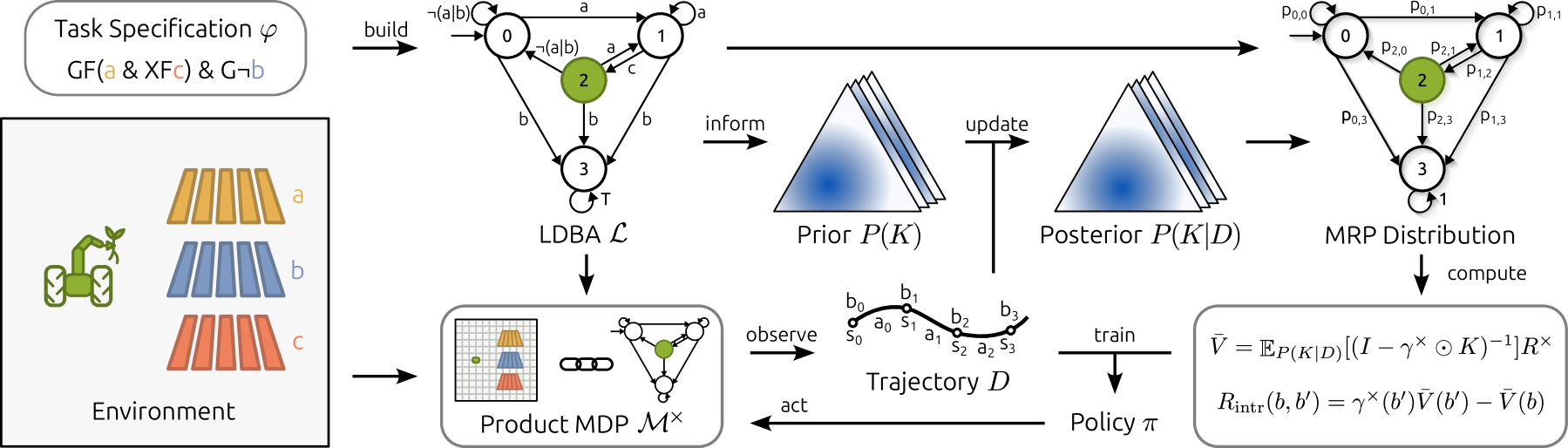
核心思路:论文的核心思路是利用LTL规范本身的信息来指导智能体的探索。具体而言,将与LTL规范对应的极限确定性Büchi自动机(LDBA)视为一个马尔可夫奖励过程,并利用贝叶斯方法对LDBA的动态进行建模和价值估计。这些估计的价值被用作塑造势,进而生成信息丰富的内在奖励,引导智能体探索更有可能满足LTL规范的状态。
技术框架:该方法的技术框架主要包括以下几个步骤:1) 将LTL公式转换为LDBA;2) 将LDBA视为马尔可夫奖励过程;3) 对LDBA的动态进行贝叶斯建模,并使用合适的先验分布;4) 基于贝叶斯模型估计LDBA的价值;5) 将估计的价值作为塑造势,生成内在奖励;6) 使用强化学习算法(如Q-learning或Actor-Critic)优化策略,同时考虑环境奖励和内在奖励。
关键创新:该方法最重要的创新在于利用LTL规范本身的信息来指导探索,而不是仅仅依赖于稀疏的环境奖励。通过将LDBA视为马尔可夫奖励过程并进行贝叶斯建模,该方法能够有效地估计LTL规范的价值,并将其转化为内在奖励,从而引导智能体探索更有希望的区域。与现有方法相比,该方法能够更有效地解决奖励稀疏问题,并提高在高维和长时程任务中的性能。
关键设计:在贝叶斯建模方面,论文提出了一个合适的先验分布,用于描述LDBA动态的不确定性。具体细节未知。内在奖励的设计基于塑造势,确保内在奖励不会改变最优策略。强化学习算法的选择可以根据具体任务进行调整,例如,可以使用Q-learning处理表格环境,使用Actor-Critic方法处理高维连续控制任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在表格环境和高维连续控制任务中均取得了显著的性能提升。在高维连续控制任务中,该方法能够成功解决现有基于LTL的强化学习算法难以处理的问题。具体的性能数据和对比基线未知,但论文强调该方法在高维连续系统中的应用是显著的挑战。
🎯 应用场景
该研究成果可应用于机器人导航、任务规划、自动驾驶等领域,尤其是在需要满足复杂时序逻辑约束的场景下。例如,机器人需要在特定时间内到达指定地点,并避免进入某些危险区域。该方法可以帮助智能体更有效地探索环境,学习满足复杂约束的策略,从而提高任务完成的成功率和效率。未来,该方法有望推动强化学习在更广泛的实际应用中落地。
📄 摘要(原文)
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Büchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.