Meta SAC-Lag: Towards Deployable Safe Reinforcement Learning via MetaGradient-based Hyperparameter Tuning
作者: Homayoun Honari, Amir Mehdi Soufi Enayati, Mehran Ghafarian Tamizi, Homayoun Najjaran
分类: cs.LG, cs.AI, cs.RO, eess.SY
发布日期: 2024-08-15
备注: Main text accepted to the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2024, 10 pages, 4 figures, 3 tables
💡 一句话要点
提出Meta SAC-Lag,通过元梯度优化超参数,提升安全强化学习的部署能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 元学习 拉格朗日方法 超参数优化 机器人控制
📋 核心要点
- 现有基于拉格朗日的安全强化学习方法,在实际部署中面临超参数(尤其是安全阈值)难以精确调整的问题,导致策略收敛效果不佳。
- Meta SAC-Lag采用元梯度优化方法,自动更新与安全相关的超参数,从而在安全探索和阈值调整方面减少了对人工超参数调整的依赖。
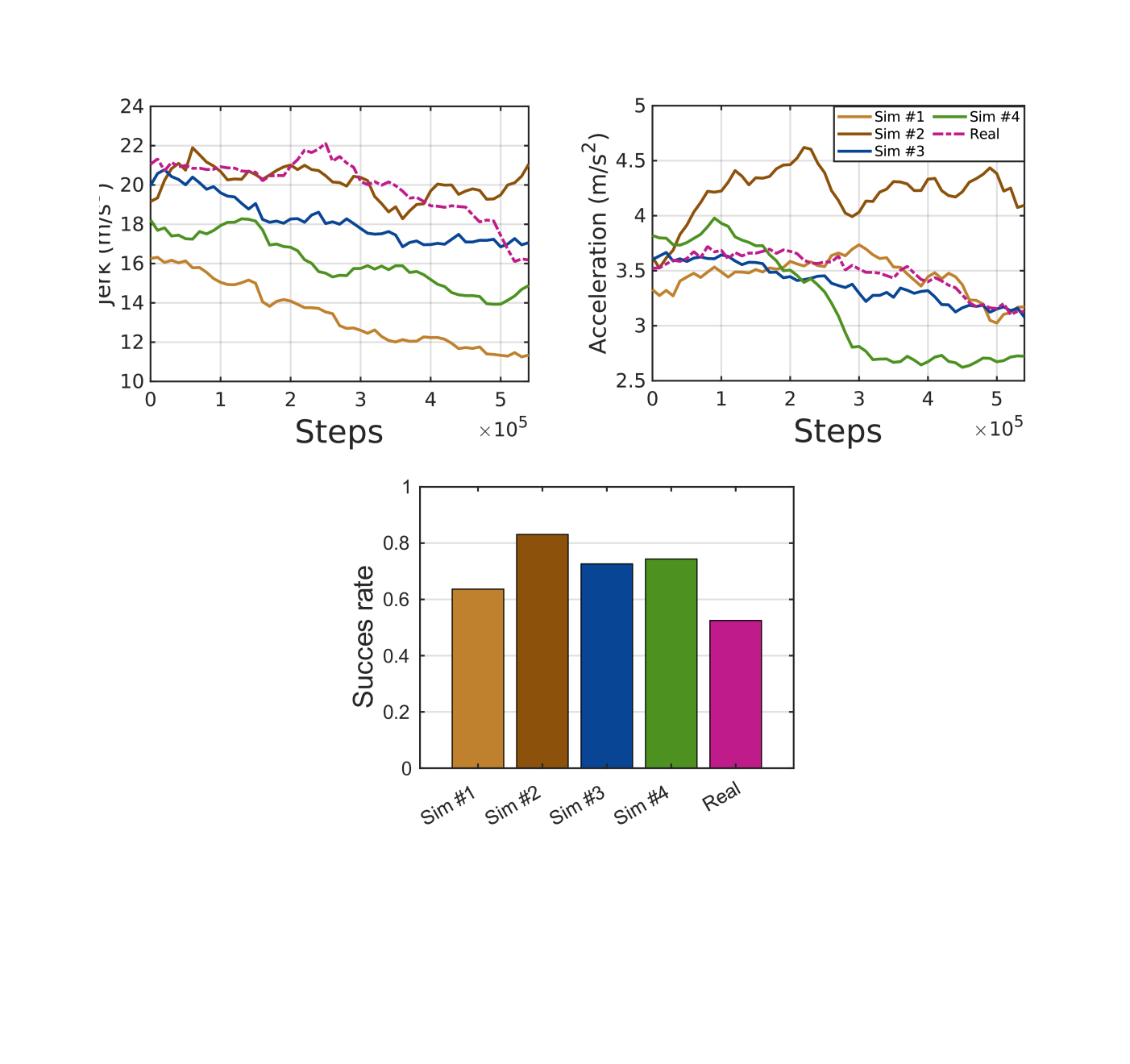
- 实验结果表明,Meta SAC-Lag能够可靠地调整安全性能,并在多个模拟环境和真实机器人任务中,取得了优于或媲美基线方法的结果。
📝 摘要(中文)
安全强化学习(Safe RL)旨在通过试错法部署到真实世界系统中。在安全RL中,目标是最大化奖励性能,同时最小化约束,这通常通过约束函数的边界设定和拉格朗日方法来实现。然而,由于阈值微调的必要性,基于拉格朗日的安全RL在实际部署中面临挑战,因为不精确的调整可能导致次优策略收敛。为了缓解这一挑战,我们提出了一种统一的基于拉格朗日的无模型架构,称为Meta Soft Actor-Critic Lagrangian(Meta SAC-Lag)。Meta SAC-Lag使用元梯度优化来自动更新与安全相关的超参数。该方法旨在以最小的超参数调整需求来解决安全探索和阈值调整问题。在我们的流程中,内部参数通过传统公式更新,超参数使用基于更新参数定义的元目标进行调整。结果表明,由于安全阈值的相对快速收敛速度,智能体可以可靠地调整安全性能。我们在五个模拟环境中评估了Meta SAC-Lag相对于拉格朗日基线的性能,结果表明它能够创建参数之间的协同作用,从而产生更好或具有竞争力的结果。此外,我们进行了一项真实世界的实验,涉及一个机械臂,其任务是将咖啡倒入杯中而不洒出。Meta SAC-Lag成功地训练执行该任务,同时最大限度地减少了努力约束。
🔬 方法详解
问题定义:论文旨在解决安全强化学习中,基于拉格朗日方法的算法对超参数(尤其是安全阈值)敏感的问题。现有方法需要手动调整这些超参数,这不仅耗时,而且不精确的调整会导致策略收敛到次优解,限制了安全强化学习在实际场景中的部署。
核心思路:论文的核心思路是利用元学习的思想,通过元梯度优化来自动调整与安全相关的超参数。具体来说,将安全阈值等超参数视为元参数,通过优化一个元目标函数来更新这些元参数,使得智能体在不同的任务或环境中能够更快地适应,并满足安全约束。
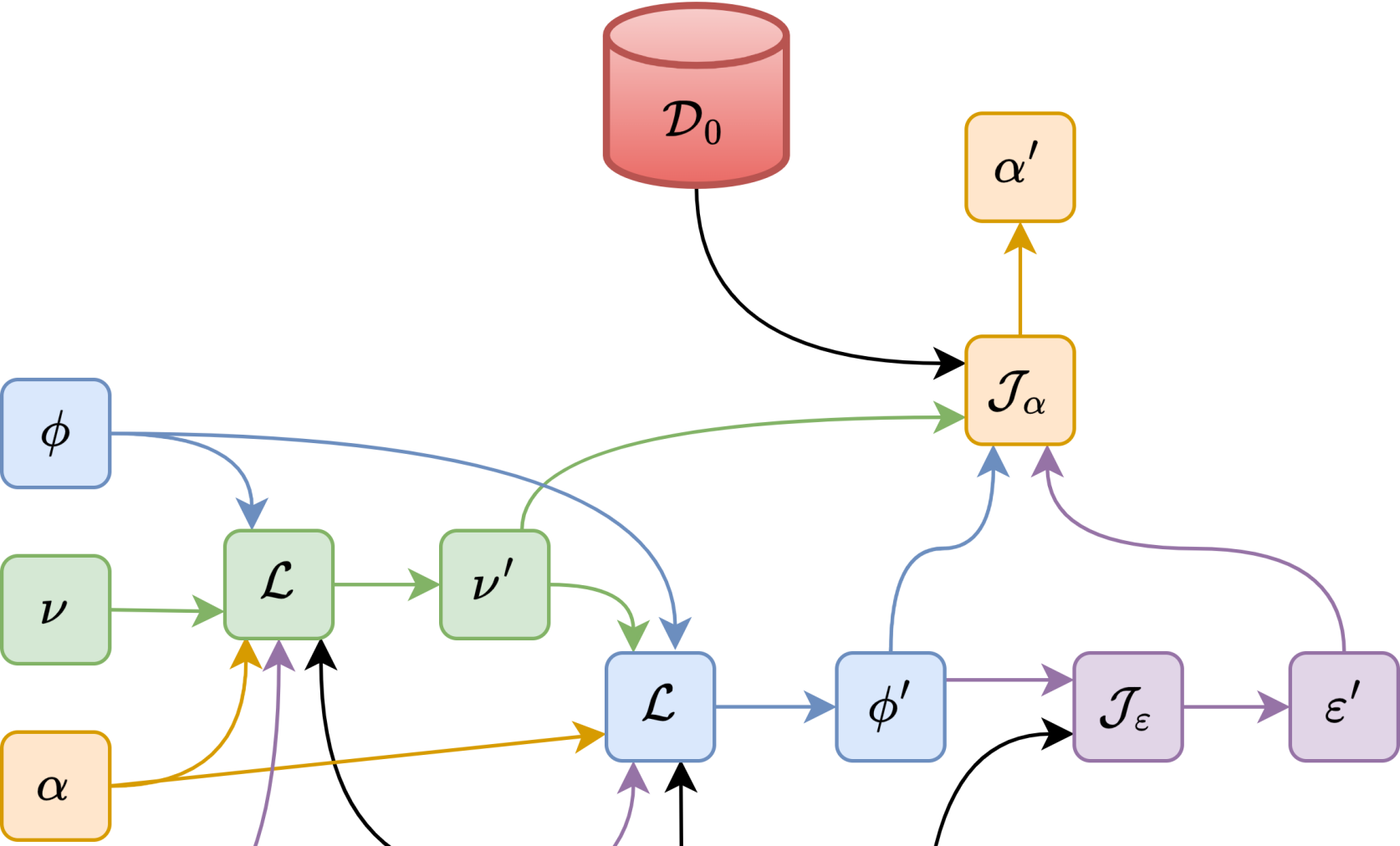
技术框架:Meta SAC-Lag的整体框架基于Soft Actor-Critic (SAC) 算法,并结合了拉格朗日方法来处理安全约束。该框架包含以下主要模块:1) Actor-Critic网络,用于学习策略和价值函数;2) 拉格朗日乘子,用于平衡奖励和约束;3) 元梯度优化器,用于更新安全相关的超参数。训练过程分为内循环和外循环。内循环使用SAC算法更新Actor-Critic网络的参数,外循环使用元梯度优化器更新超参数。
关键创新:该论文的关键创新在于将元学习与拉格朗日安全强化学习相结合,提出了一种能够自动调整安全相关超参数的算法。与传统方法相比,Meta SAC-Lag无需手动调整超参数,从而降低了部署难度,并提高了算法的鲁棒性和泛化能力。
关键设计:Meta SAC-Lag的关键设计包括:1) 元目标的定义,元目标旨在最大化奖励并最小化约束违反;2) 元梯度优化器的选择,论文使用了基于梯度的优化器来更新超参数;3) 损失函数的设计,损失函数包括奖励损失、约束损失和元损失,用于训练Actor-Critic网络和元梯度优化器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Meta SAC-Lag在五个模拟环境中,相较于传统的拉格朗日基线方法,能够取得更好或具有竞争力的性能。在真实的机器人咖啡倾倒实验中,Meta SAC-Lag成功训练机器人完成任务,同时最小化了倾倒过程中的咖啡洒出量,验证了该方法在实际应用中的有效性。
🎯 应用场景
Meta SAC-Lag可应用于各种需要安全保障的机器人控制任务,例如自动驾驶、工业机器人、医疗机器人等。通过自动调整安全阈值,该方法可以确保机器人在执行任务时不会违反安全约束,从而避免潜在的危险和损失。此外,该方法还可以应用于资源受限的环境中,例如在电力受限的机器人中,可以通过调整能量消耗的约束来优化任务执行效率。
📄 摘要(原文)
Safe Reinforcement Learning (Safe RL) is one of the prevalently studied subcategories of trial-and-error-based methods with the intention to be deployed on real-world systems. In safe RL, the goal is to maximize reward performance while minimizing constraints, often achieved by setting bounds on constraint functions and utilizing the Lagrangian method. However, deploying Lagrangian-based safe RL in real-world scenarios is challenging due to the necessity of threshold fine-tuning, as imprecise adjustments may lead to suboptimal policy convergence. To mitigate this challenge, we propose a unified Lagrangian-based model-free architecture called Meta Soft Actor-Critic Lagrangian (Meta SAC-Lag). Meta SAC-Lag uses meta-gradient optimization to automatically update the safety-related hyperparameters. The proposed method is designed to address safe exploration and threshold adjustment with minimal hyperparameter tuning requirement. In our pipeline, the inner parameters are updated through the conventional formulation and the hyperparameters are adjusted using the meta-objectives which are defined based on the updated parameters. Our results show that the agent can reliably adjust the safety performance due to the relatively fast convergence rate of the safety threshold. We evaluate the performance of Meta SAC-Lag in five simulated environments against Lagrangian baselines, and the results demonstrate its capability to create synergy between parameters, yielding better or competitive results. Furthermore, we conduct a real-world experiment involving a robotic arm tasked with pouring coffee into a cup without spillage. Meta SAC-Lag is successfully trained to execute the task, while minimizing effort constraints.