FedQUIT: On-Device Federated Unlearning via a Quasi-Competent Virtual Teacher
作者: Alessio Mora, Lorenzo Valerio, Paolo Bellavista, Andrea Passarella
分类: cs.LG, cs.DC
发布日期: 2024-08-14 (更新: 2025-11-06)
💡 一句话要点
FedQUIT:通过准胜任虚拟教师实现设备端联邦遗忘
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 遗忘学习 知识蒸馏 隐私保护 设备端学习
📋 核心要点
- 联邦学习中,用户有权要求删除其数据贡献,但现有方法常依赖不切实际的假设,如存储历史更新或访问代理数据集。
- FedQUIT利用知识蒸馏,通过教师-学生框架在客户端设备上直接擦除数据贡献,无需额外数据或历史信息。
- 实验表明,FedQUIT在遗忘数据方面优于现有方法,计算开销与FedAvg相当,并显著降低了通信成本。
📝 摘要(中文)
联邦学习(FL)系统支持在无需集中收集个人数据的情况下协同训练机器学习模型。FL参与者应有权行使被遗忘权,确保根据请求将其过去的贡献从学习到的模型中删除。本文提出了一种新的算法FedQUIT,它使用知识蒸馏从FL全局模型中擦除要遗忘的数据的贡献,同时保持其泛化能力。FedQUIT直接在请求离开联邦的客户端设备上工作,并利用教师-学生框架。FL全局模型充当教师,本地模型充当学生。为了诱导遗忘,FedQUIT定制教师在本地数据(要遗忘的数据)上的输出,惩罚真实类别的预测分数。与之前的工作不同,我们的方法不需要跨设备设置中难以实现的假设,例如存储参与者的历史更新或需要访问代理数据集。在各种数据集和模型架构上的实验结果表明,(i) FedQUIT在遗忘数据方面优于最先进的竞争对手,(ii)具有与常规FedAvg轮次完全相同的计算要求,并且(iii)与从头开始重新训练以恢复遗忘后的初始泛化性能相比,累积通信成本降低了高达117.6倍。
🔬 方法详解
问题定义:联邦学习系统需要支持用户“被遗忘权”,即从全局模型中移除特定用户的数据贡献。现有联邦遗忘方法通常需要存储用户的历史更新信息,或者依赖于额外的代理数据集,这在实际的跨设备联邦学习场景中难以实现,因为设备资源有限,存储历史数据会带来额外的开销,且代理数据集的质量难以保证。
核心思路:FedQUIT的核心思路是利用知识蒸馏技术,将全局模型作为教师,客户端的本地模型作为学生。通过修改教师模型的输出,使其在要遗忘的数据上表现不佳,从而引导学生模型学习到不包含这些数据的知识。这种方法避免了对历史数据或代理数据集的依赖,直接在客户端设备上进行遗忘操作。
技术框架:FedQUIT的整体框架基于教师-学生模型。首先,全局模型(教师)将知识传递给本地模型(学生)。然后,对于请求遗忘的客户端,FedQUIT会修改教师模型的输出,具体来说,对于要遗忘的数据,教师模型会降低真实类别的预测概率。学生模型通过学习被修改后的教师模型的输出,从而逐渐遗忘相关数据。最后,学生模型更新被上传到服务器,用于更新全局模型。
关键创新:FedQUIT的关键创新在于其在客户端设备上直接进行遗忘操作,无需访问历史数据或代理数据集。通过修改教师模型的输出,诱导学生模型遗忘特定数据,这种方法更加灵活和高效,更适合资源受限的跨设备联邦学习场景。
关键设计:FedQUIT的关键设计在于如何修改教师模型的输出。论文采用的方法是惩罚真实类别的预测分数。具体来说,对于要遗忘的数据样本,教师模型输出的真实类别概率会被降低,从而使得学生模型在学习时更加关注其他类别,最终达到遗忘的效果。具体的惩罚力度可以通过超参数进行调整,以平衡遗忘效果和模型性能。
🖼️ 关键图片


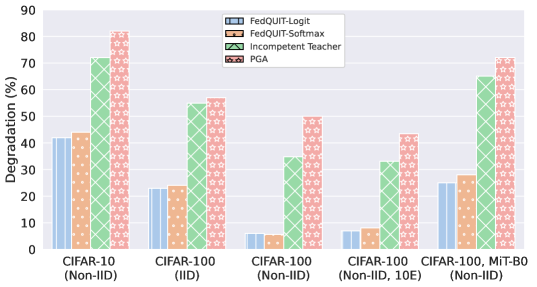
📊 实验亮点
实验结果表明,FedQUIT在遗忘数据方面优于现有方法,同时保持了良好的模型泛化性能。与从头开始重新训练相比,FedQUIT可以将累积通信成本降低高达117.6倍。此外,FedQUIT的计算开销与常规的FedAvg轮次相当,使其易于部署和应用。
🎯 应用场景
FedQUIT可应用于各种联邦学习场景,尤其是在用户隐私保护要求较高的领域,如医疗健康、金融服务等。它使得用户可以安全地退出联邦学习系统,并确保其数据贡献被有效移除,从而增强用户对联邦学习系统的信任,促进联邦学习技术的广泛应用。
📄 摘要(原文)
Federated Learning (FL) systems enable the collaborative training of machine learning models without requiring centralized collection of individual data. FL participants should have the ability to exercise their right to be forgotten, ensuring their past contributions can be removed from the learned model upon request. In this paper, we propose FedQUIT, a novel algorithm that uses knowledge distillation to scrub the contribution of the data to forget from an FL global model while preserving its generalization ability. FedQUIT directly works on client devices that request to leave the federation, and leverages a teacher-student framework. The FL global model acts as the teacher, and the local model works as the student. To induce forgetting, FedQUIT tailors the teacher's output on local data (the data to forget) penalizing the prediction score of the true class. Unlike previous work, our method does not require hardly viable assumptions for cross-device settings, such as storing historical updates of participants or requiring access to proxy datasets. Experimental results on various datasets and model architectures demonstrate that (i) FedQUIT outperforms state-of-the-art competitors in forgetting data, (ii) has the exact computational requirements as a regular FedAvg round, and (iii) reduces the cumulative communication costs by up to 117.6$\times$ compared to retraining from scratch to restore the initial generalization performance after unlearning.