Nonlocal Attention Operator: Materializing Hidden Knowledge Towards Interpretable Physics Discovery
作者: Yue Yu, Ning Liu, Fei Lu, Tian Gao, Siavash Jafarzadeh, Stewart Silling
分类: cs.LG, math.AP
发布日期: 2024-08-14
💡 一句话要点
提出非局部注意力算子(NAO)用于可解释的物理发现,解决逆PDE问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 非局部注意力算子 神经算子 物理发现 逆问题 偏微分方程 注意力机制 物理建模
📋 核心要点
- 物理系统建模面临病态PDE逆问题,现有方法难以有效提取全局先验信息。
- 提出非局部注意力算子(NAO),利用注意力机制等价的双重积分算子进行非局部交互。
- 实验表明NAO在泛化性和处理不同数据分辨率和系统状态方面优于现有模型。
📝 摘要(中文)
尽管基于注意力的神经架构在自然语言处理(NLP)和计算机视觉(CV)等核心人工智能领域广受欢迎,但它们在建模复杂物理系统方面的潜力仍未得到充分探索。物理系统中的学习问题通常被描述为发现算子,这些算子基于少量函数对的实例在函数空间之间进行映射。这项任务通常表现为一个严重的病态偏微分方程(PDE)反问题。在这项工作中,我们提出了一种基于注意力机制的新型神经算子架构,我们称之为非局部注意力算子(NAO),并探索其在开发基础物理模型方面的能力。特别地,我们表明注意力机制等价于一个双重积分算子,它能够实现空间标记之间的非局部交互,其数据相关的核表征了从数据到底层算子的隐藏参数场的逆映射。因此,注意力机制从多个系统生成的训练数据中提取全局先验信息,并以非线性核映射的形式提出探索空间。因此,NAO可以通过编码正则化和实现泛化来解决逆PDE问题中的病态性和秩亏问题。我们通过实验证明了NAO在泛化到未见数据分辨率和系统状态方面优于基线神经模型。我们的工作不仅提出了一种用于学习物理系统可解释基础模型的新型神经算子架构,而且为理解注意力机制提供了一个新的视角。
🔬 方法详解
问题定义:论文旨在解决物理系统建模中遇到的病态偏微分方程(PDE)反问题。传统的数值方法和一些机器学习方法在处理这类问题时,往往需要大量的先验知识或者对特定系统进行定制化设计,泛化能力较差。现有的方法难以有效提取全局先验信息,导致模型在未见过的系统状态或数据分辨率下表现不佳。
核心思路:论文的核心思路是将注意力机制与神经算子相结合,提出非局部注意力算子(NAO)。NAO将注意力机制解释为一个双重积分算子,从而能够捕捉空间标记之间的非局部交互。通过这种方式,NAO可以从训练数据中提取全局先验信息,并将其编码到模型的参数中,从而提高模型的泛化能力和鲁棒性。
技术框架:NAO的整体架构包含以下几个主要模块:1) 输入嵌入层:将输入数据映射到高维空间;2) 注意力层:利用注意力机制进行非局部交互,提取全局先验信息;3) 输出层:将注意力层的输出映射到目标函数空间。整个流程可以看作是一个从输入函数空间到输出函数空间的映射,其中注意力层起到了关键作用,它通过学习数据相关的核函数来实现非局部交互。
关键创新:NAO最重要的技术创新点在于将注意力机制与神经算子相结合,并将其解释为一个双重积分算子。这种解释不仅为理解注意力机制提供了一个新的视角,而且为设计更有效的神经算子提供了理论基础。与现有方法相比,NAO能够更好地捕捉全局先验信息,从而提高模型的泛化能力和鲁棒性。
关键设计:NAO的关键设计包括:1) 注意力头的数量:多个注意力头可以捕捉不同的非局部交互模式;2) 核函数的选择:不同的核函数可以适应不同的物理系统;3) 损失函数的设计:损失函数需要能够反映模型的预测精度和泛化能力。论文中使用了均方误差(MSE)作为损失函数,并采用正则化技术来防止过拟合。
🖼️ 关键图片

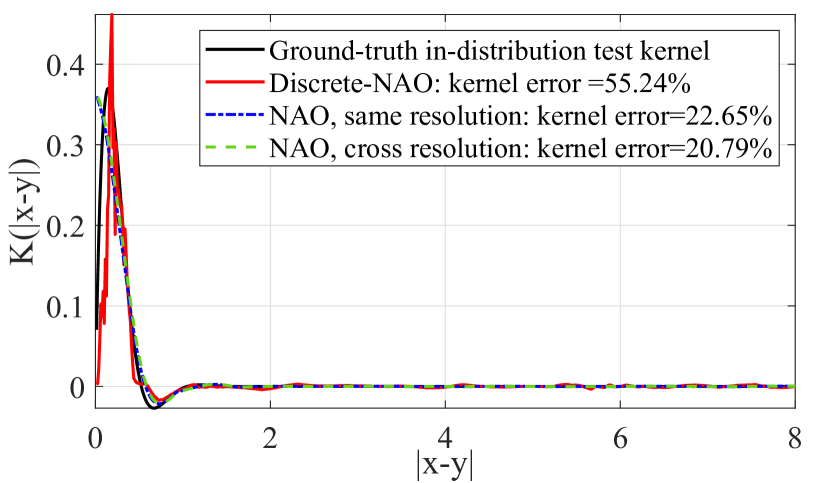

📊 实验亮点
实验结果表明,NAO在泛化到未见数据分辨率和系统状态方面优于基线神经模型。具体来说,NAO在处理不同分辨率的数据时,能够保持较高的预测精度,而基线模型则会出现明显的性能下降。此外,NAO在处理不同系统状态的数据时,也表现出更强的鲁棒性,能够有效地捕捉全局先验信息,并将其应用于新的系统状态。
🎯 应用场景
NAO在物理系统建模领域具有广泛的应用前景,例如流体动力学、固体力学、热传导等。它可以用于预测复杂物理系统的行为,优化系统设计,以及进行反问题求解。NAO的实际价值在于能够加速物理系统的建模和仿真过程,降低实验成本,并为科学研究提供新的工具和方法。未来,NAO有望成为物理领域的基础模型,为各种应用提供支持。
📄 摘要(原文)
Despite the recent popularity of attention-based neural architectures in core AI fields like natural language processing (NLP) and computer vision (CV), their potential in modeling complex physical systems remains under-explored. Learning problems in physical systems are often characterized as discovering operators that map between function spaces based on a few instances of function pairs. This task frequently presents a severely ill-posed PDE inverse problem. In this work, we propose a novel neural operator architecture based on the attention mechanism, which we coin Nonlocal Attention Operator (NAO), and explore its capability towards developing a foundation physical model. In particular, we show that the attention mechanism is equivalent to a double integral operator that enables nonlocal interactions among spatial tokens, with a data-dependent kernel characterizing the inverse mapping from data to the hidden parameter field of the underlying operator. As such, the attention mechanism extracts global prior information from training data generated by multiple systems, and suggests the exploratory space in the form of a nonlinear kernel map. Consequently, NAO can address ill-posedness and rank deficiency in inverse PDE problems by encoding regularization and achieving generalizability. We empirically demonstrate the advantages of NAO over baseline neural models in terms of generalizability to unseen data resolutions and system states. Our work not only suggests a novel neural operator architecture for learning interpretable foundation models of physical systems, but also offers a new perspective towards understanding the attention mechanism.