Solving Truly Massive Budgeted Monotonic POMDPs with Oracle-Guided Meta-Reinforcement Learning
作者: Manav Vora, Jonas Liang, Michael N. Grussing, Melkior Ornik
分类: cs.LG, cs.AI, math.OC
发布日期: 2024-08-13 (更新: 2025-09-15)
💡 一句话要点
提出基于Oracle引导的元强化学习方法,解决大规模预算约束单调POMDP问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 单调POMDP 元强化学习 预算约束 资源分配 近端策略优化 随机森林 价值迭代
📋 核心要点
- 现有方法难以解决大规模多组件单调POMDP问题,主要挑战在于状态空间随组件数量呈指数增长。
- 论文提出两步法:先用随机森林近似预算分配,再用Oracle引导的元训练PPO求解单组件POMDP。
- 实验表明,该方法在实际维护场景中有效,并通过计算复杂度分析验证了其可扩展性。
📝 摘要(中文)
本文提出了一种解决预算约束多组件单调部分可观测马尔可夫决策过程(POMDPs)的方法,该方法适用于系统状态逐渐减少直至执行恢复性动作的场景。由于组件数量增加导致状态空间呈指数增长,直接求解此类POMDP在计算上是不可行的。为此,我们提出了一种两步法:首先,利用随机森林模型近似每个组件POMDP的最优价值函数,从而近似最优预算分配。然后,引入Oracle引导的元训练近端策略优化(PPO)算法,求解每个独立的预算约束单组件单调POMDP。Oracle策略通过对相应的单调马尔可夫决策过程(MDP)执行价值迭代获得。该方法显著提高了求解大规模多组件单调POMDP的可扩展性。我们通过一个涉及行政建筑检查和维修的实际维护场景验证了该方法的有效性,并进行了计算复杂度分析,证明了其可扩展性。
🔬 方法详解
问题定义:论文旨在解决大规模预算约束多组件单调POMDP的求解问题。传统的POMDP求解方法,如值迭代或策略迭代,在状态空间随组件数量指数增长时变得计算不可行。现有方法难以处理这种大规模问题,导致无法有效地进行资源分配和决策。
核心思路:论文的核心思路是将复杂的多组件POMDP分解为多个独立的单组件POMDP,并通过近似预算分配来协调这些组件。这种分解降低了每个子问题的复杂度,使得可以使用强化学习方法进行求解。Oracle引导的元学习则加速了强化学习的收敛,提高了策略的质量。
技术框架:整体框架包含两个主要阶段:1) 预算分配阶段:使用随机森林模型近似每个组件POMDP的最优价值函数,从而确定各组件的最优预算分配。2) 策略优化阶段:使用Oracle引导的元训练PPO算法,针对每个单组件POMDP,学习最优的维修策略。Oracle策略通过对相应的单调MDP执行价值迭代获得,用于指导PPO的训练。
关键创新:论文的关键创新在于将预算分配问题与单组件POMDP求解问题解耦,并利用Oracle策略引导元强化学习。这种方法有效地降低了问题的复杂度,并提高了求解效率。元学习的使用使得算法能够快速适应不同的单组件POMDP,而Oracle策略则提供了有价值的先验知识,加速了学习过程。
关键设计:随机森林模型用于近似价值函数,其输入是组件的状态和预算,输出是期望回报。PPO算法使用Actor-Critic结构,Actor网络输出策略,Critic网络评估价值。Oracle策略通过价值迭代计算得到,作为PPO的监督信号。损失函数包括PPO的策略损失、价值损失和熵正则化项。元学习通过在多个单组件POMDP上进行训练,使得PPO能够快速适应新的组件。
🖼️ 关键图片
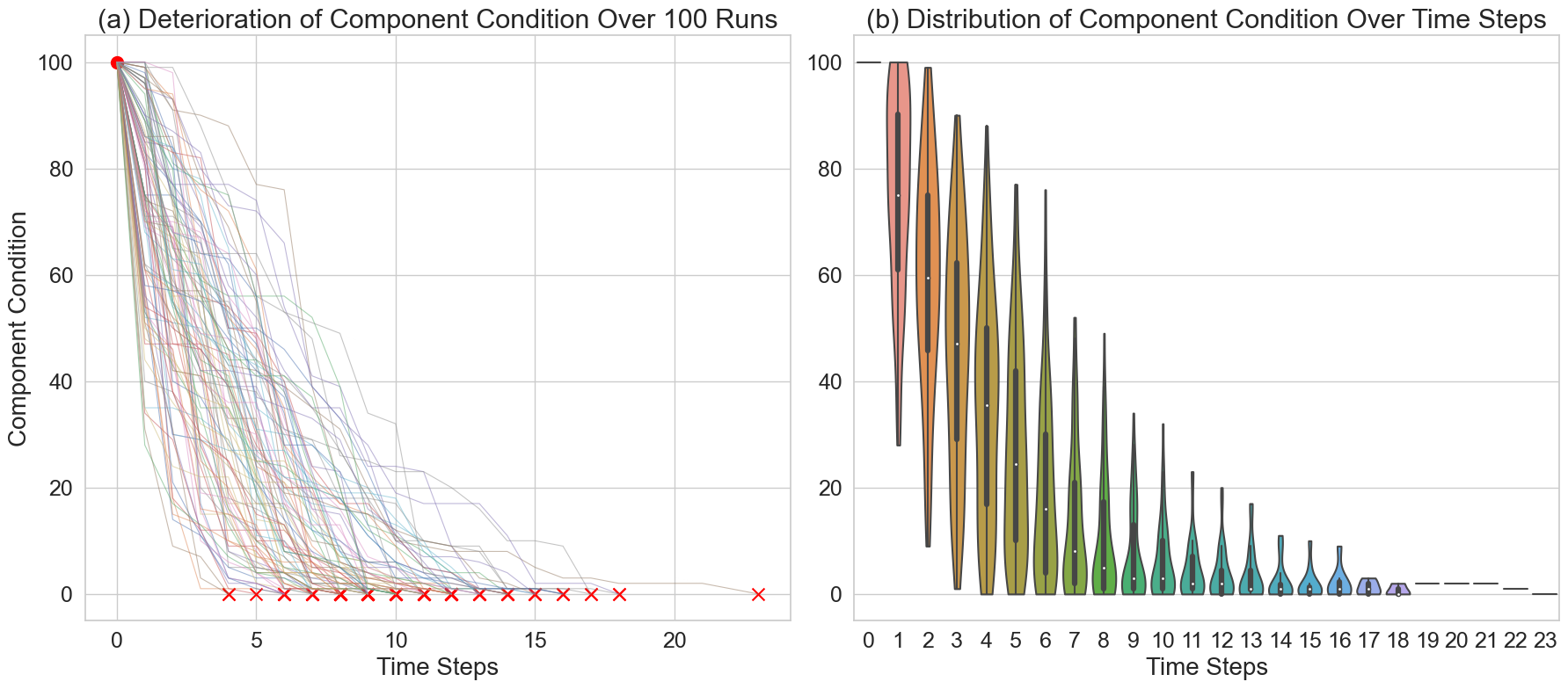
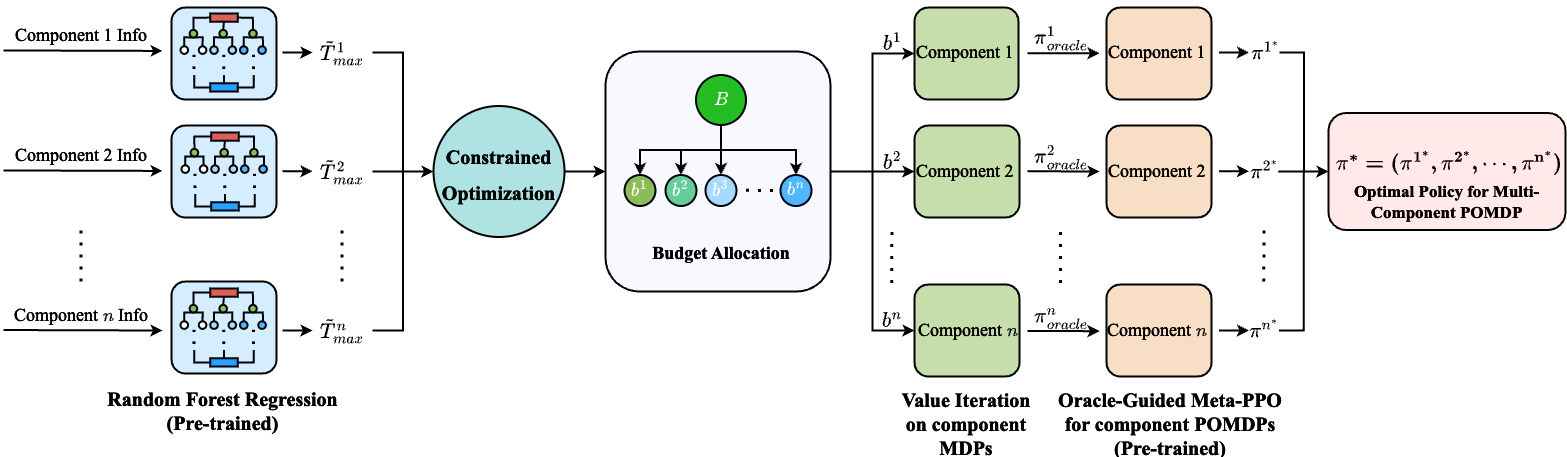
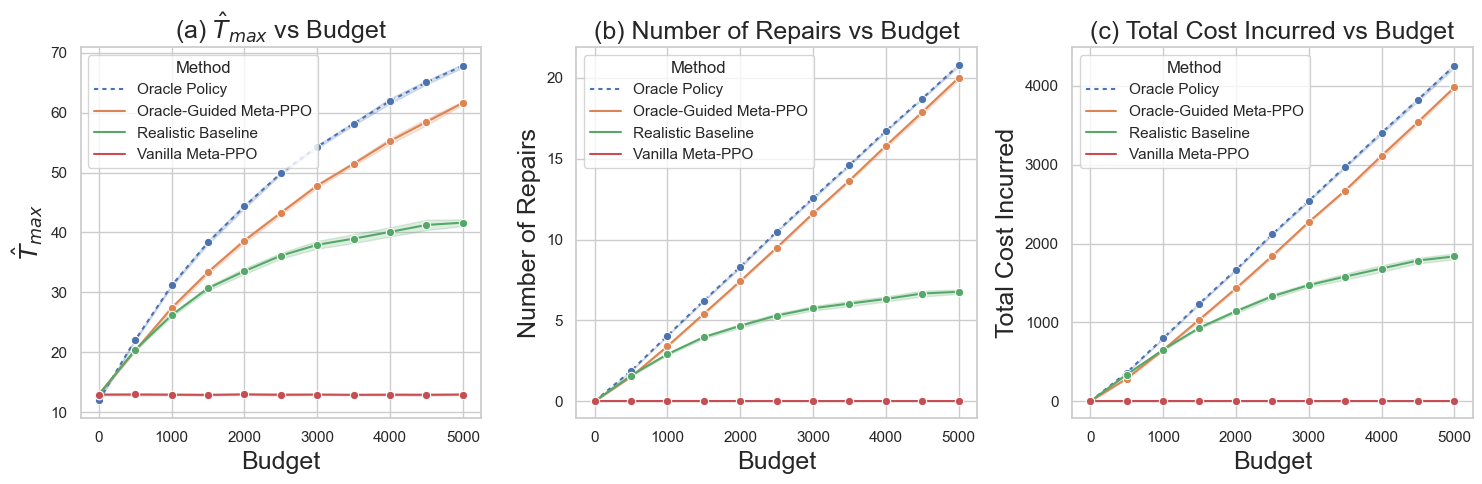
📊 实验亮点
论文通过实际的行政建筑维护场景验证了所提出方法的有效性。计算复杂度分析表明,该方法在组件数量增加时具有良好的可扩展性,显著优于传统的POMDP求解方法。虽然文中没有给出具体的性能数据,但强调了该方法在处理大规模问题上的优势。
🎯 应用场景
该研究成果可应用于各种需要资源分配和维护决策的场景,例如:基础设施维护(桥梁、道路)、设备维修、生产线管理、软件系统维护等。通过优化资源分配和维护策略,可以降低维护成本,提高系统可靠性,并延长使用寿命。该方法在智能运维领域具有广阔的应用前景。
📄 摘要(原文)
Monotonic Partially Observable Markov Decision Processes (POMDPs), where the system state progressively decreases until a restorative action is performed, can be used to model sequential repair problems effectively. This paper considers the problem of solving budget-constrained multi-component monotonic POMDPs, where a finite budget limits the maximal number of restorative actions. For a large number of components, solving such a POMDP using current methods is computationally intractable due to the exponential growth in the state space with an increasing number of components. To address this challenge, we propose a two-step approach. Since the individual components of a budget-constrained multi-component monotonic POMDP are only connected via the shared budget, we first approximate the optimal budget allocation among these components using an approximation of each component POMDP's optimal value function which is obtained through a random forest model. Subsequently, we introduce an oracle-guided meta-trained Proximal Policy Optimization (PPO) algorithm to solve each of the independent budget-constrained single-component monotonic POMDPs. The oracle policy is obtained by performing value iteration on the corresponding monotonic Markov Decision Process (MDP). This two-step method provides scalability in solving truly massive multi-component monotonic POMDPs. To demonstrate the efficacy of our approach, we consider a real-world maintenance scenario that involves inspection and repair of an administrative building by a team of agents within a maintenance budget. Finally, we perform a computational complexity analysis for a varying number of components to show the scalability of the proposed approach.