LUT Tensor Core: A Software-Hardware Co-Design for LUT-Based Low-Bit LLM Inference
作者: Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, Mao Yang
分类: cs.AR, cs.LG
发布日期: 2024-08-12 (更新: 2025-07-28)
备注: Conference Version (ISCA'25). Fixed a typo
💡 一句话要点
提出LUT Tensor Core软硬件协同设计,加速低比特LLM的LUT推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低比特量化 LLM推理 混合精度计算 LUT加速 软硬件协同设计
📋 核心要点
- 现有硬件对低比特LLM的混合精度矩阵乘法(mpGEMM)支持不足,导致效率低下的反量化实现。
- 论文提出LUT Tensor Core,通过软硬件协同优化,包括软件优化减少预计算开销,硬件优化提高表重用率。
- 实验结果表明,LUT Tensor Core在计算密度和能源效率方面,相比现有技术有显著提升。
📝 摘要(中文)
大型语言模型(LLM)推理对资源的需求日益增长,促使人们转向低比特模型权重,以减少内存占用并提高效率。这种低比特LLM需要混合精度矩阵乘法(mpGEMM),这是一种重要但未被充分探索的运算,涉及较低精度权重与较高精度激活值的乘法。现成的硬件不支持这种原生运算,导致基于反量化的间接且低效的实现。本文研究了基于查找表(LUT)的mpGEMM方法,并发现传统的LUT实现未能实现预期的收益。为了充分发挥基于LUT的mpGEMM的潜力,我们提出了LUT Tensor Core,一种用于低比特LLM推理的软硬件协同设计。LUT Tensor Core通过以下方式与传统的LUT设计区分开来:1)基于软件的优化,以最大限度地减少表预计算开销和权重重新解释,以减少表存储;2)基于LUT的Tensor Core硬件设计,具有细长的平铺形状,以最大限度地提高表重用,以及支持mpGEMM中各种精度组合的位串行设计;3)用于基于LUT的mpGEMM的新指令集和编译优化。LUT Tensor Core显著优于现有的纯软件LUT实现,并且与以前最先进的基于LUT的加速器相比,在计算密度和能源效率方面提高了1.44倍。
🔬 方法详解
问题定义:论文旨在解决低比特量化LLM推理中,混合精度矩阵乘法(mpGEMM)在现有硬件上效率低下的问题。现有方法主要依赖反量化,计算开销大,或者传统的LUT实现未能充分发挥其潜力。
核心思路:论文的核心思路是采用软硬件协同设计,针对LUT-based mpGEMM进行优化。通过软件优化减少LUT预计算开销和存储需求,并通过定制的硬件架构最大化LUT的重用率,从而提高整体推理效率。
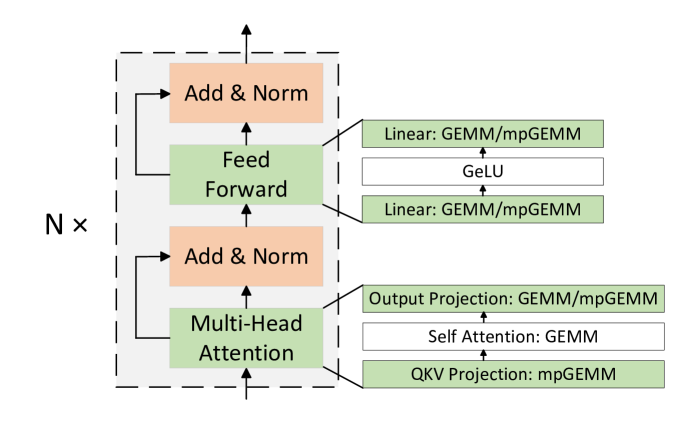
技术框架:LUT Tensor Core的整体框架包括:1)软件优化阶段,对权重进行重新解释,减少LUT的存储需求,并优化LUT的预计算过程;2)硬件加速阶段,采用基于LUT的Tensor Core架构,利用细长的平铺形状提高LUT的重用率,并采用位串行设计支持不同的精度组合;3)编译优化阶段,设计新的指令集,并进行编译优化,以充分利用LUT Tensor Core的硬件特性。
关键创新:论文的关键创新在于软硬件协同设计。软件方面,通过权重重解释减少LUT存储,降低预计算开销。硬件方面,定制的Tensor Core架构,特别是细长的平铺形状和位串行设计,显著提高了LUT的利用率和灵活性。
关键设计:LUT Tensor Core的关键设计包括:1)权重重解释策略,用于减少LUT的存储空间;2)细长的平铺形状,用于最大化LUT的重用;3)位串行计算单元,用于支持不同的精度组合;4)定制的指令集和编译优化,用于充分利用硬件特性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LUT Tensor Core显著优于现有的纯软件LUT实现,并且与以前最先进的基于LUT的加速器相比,在计算密度和能源效率方面提高了1.44倍。这表明该软硬件协同设计在加速低比特LLM推理方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要低功耗、高性能LLM推理的场景,例如移动设备、边缘计算设备和嵌入式系统。通过提高低比特LLM推理的效率,可以降低部署成本,并使LLM能够在资源受限的环境中运行,从而推动LLM在更广泛领域的应用。
📄 摘要(原文)
Large Language Model (LLM) inference becomes resource-intensive, prompting a shift toward low-bit model weights to reduce the memory footprint and improve efficiency. Such low-bit LLMs necessitate the mixed-precision matrix multiplication (mpGEMM), an important yet underexplored operation involving the multiplication of lower-precision weights with higher-precision activations. Off-the-shelf hardware does not support this operation natively, leading to indirect, thus inefficient, dequantization-based implementations. In this paper, we study the lookup table (LUT)-based approach for mpGEMM and find that a conventional LUT implementation fails to achieve the promised gains. To unlock the full potential of LUT-based mpGEMM, we propose LUT Tensor Core, a software-hardware co-design for low-bit LLM inference. LUT Tensor Core differentiates itself from conventional LUT designs through: 1) software-based optimizations to minimize table precompute overhead and weight reinterpretation to reduce table storage; 2) a LUT-based Tensor Core hardware design with an elongated tiling shape to maximize table reuse and a bit-serial design to support diverse precision combinations in mpGEMM; 3) a new instruction set and compilation optimizations for LUT-based mpGEMM. LUT Tensor Core significantly outperforms existing pure software LUT implementations and achieves a 1.44$\times$ improvement in compute density and energy efficiency compared to previous state-of-the-art LUT-based accelerators.